Neues Trainingsverfahren lässt KI-Agenten besser im Team arbeiten

Kurz & Knapp
- Forscher haben ein Framework entwickelt, bei dem spezialisierte KI-Agenten als Team mit klaren Rollen zusammenarbeiten und komplexe Aufgaben schneller lösen.
- Die neue Trainingsmethode M-GRPO gleicht unterschiedliche Arbeitslasten und Teamgrößen aus, indem sie Agenten unabhängig trainiert und ihre Lernerfahrungen synchronisiert.
- In Tests übertraf das System Einzelagenten und bisherige Ansätze bei Stabilität, Effizienz und Lösung schwieriger Aufgaben.
Forscher stellen ein neues Framework vor, das verschiedene KI-Agenten gemeinsam trainieren kann. Die Methode soll komplexe Aufgaben durch spezialisierte Rollen und Teamwork besser lösen.
Bisherige KI-Systeme setzen laut den Forschern vom Londoner Imperial College und der zu Alibaba gehörenden Ant Group meist auf einen einzelnen Agenten, der sowohl plant als auch handelt. Das funktioniert gut bei einfachen Aufgaben, wird aber problematisch bei komplexen, mehrstufigen Prozessen. Fehler verstärken sich über längere Ketten hinweg, und ein Agent kann nicht gleichzeitig Experte für Planung und Tool-Nutzung sein. Verschiedene Teilaufgaben erfordern unterschiedliche "Denkweisen", und bei langen Koordinationsaufgaben in dynamischen Umgebungen versagen einzelne Agenten häufig.
Die Lösung liegt in der Arbeitsteilung: KI-Agenten übernehmen spezialisierte Rollen, ähnlich wie in einem Unternehmen. Ein Agent fungiert als Projektmanager und plant sowie koordiniert, andere arbeiten als Spezialisten für bestimmte Tools wie Websuche oder Datenanalyse. Studien zeigen laut den Forschern, dass Multi-Agent-Systeme mit einem führenden Agenten Aufgaben fast zehn Prozent schneller lösen als solche ohne klare Hierarchie.
Besonders effektiv sind "vertikale" Architekturen, bei denen ein Hauptagent die Führung übernimmt und andere ihm berichten. Eine ähnliche Strategie verwendet Anthropic etwa bei seinem vor wenigen Monaten vorgestellten Research-Agenten.
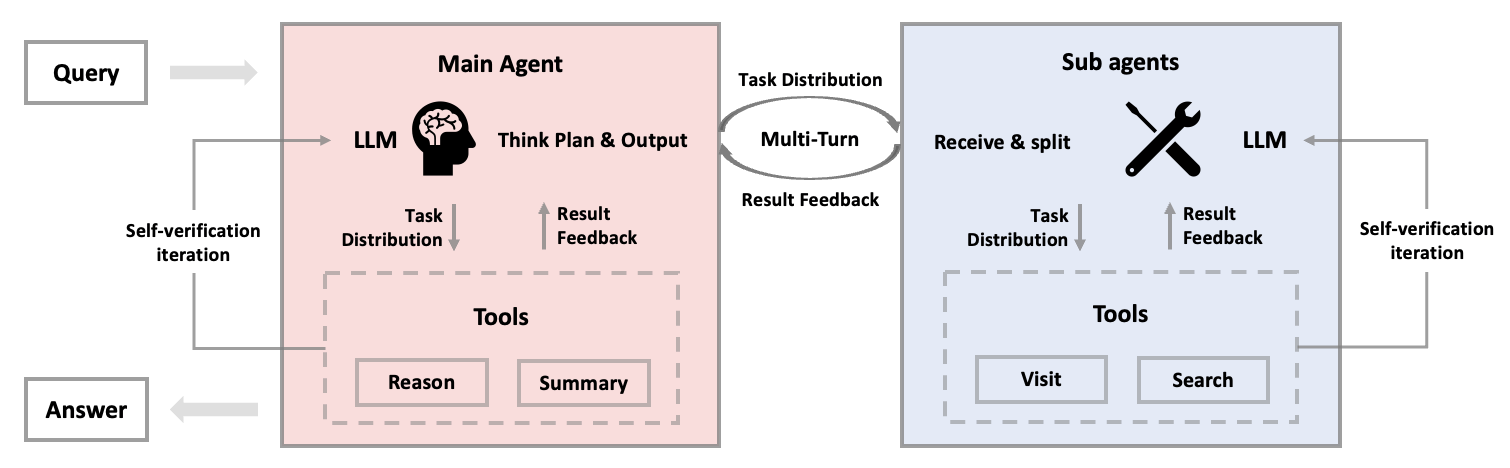
M-GRPO soll Hürden beim gemeinsamen Training überwinden
Einzelne KI-Modelle werden heute mit einer Methode namens "Group Relative Policy Optimization" (GRPO) trainiert. Vereinfacht gesagt generiert das System mehrere Antworten auf dieselbe Frage, vergleicht deren Qualität und verstärkt die besseren Ansätze.
Bei Multi-Agent-Systemen wird das komplizierter. Verschiedene Agenten arbeiten mit unterschiedlichen Frequenzen, haben verschiedene Aufgaben und laufen oft auf getrennten Servern. Die bewährten Trainingsmethoden funktionieren hier nicht mehr. Aktuelle Ansätze verwenden ein einheitliches Large Language Model für alle Agenten, was die Spezialisierung einschränkt, da verschiedene Agenten unterschiedliche Aufgaben mit verschiedenen Datenverteilungen bearbeiten.
Das Training bringt drei zentrale Herausforderungen mit sich. Erstens arbeiten Agenten mit ungleichen Arbeitslasten: Der Hauptagent arbeitet kontinuierlich, Sub-Agenten nur bei Bedarf. Dies führt zu unausgewogenen Trainingsdaten und instabilen Lernprozessen.
Zweitens variieren die Teamgrößen stark. Mal ruft der Hauptagent einen Sub-Agenten auf, mal fünf. Diese unterschiedlichen Rollout-Zahlen erschweren das gemeinsame Training erheblich. Drittens laufen Agenten oft auf getrennten Servern, wodurch Standard-Trainingsmethoden nicht mehr über Server-Grenzen hinweg funktionieren.
Hier setzt die neue "Multi-Agent Group Relative Policy Optimization" (M-GRPO) an. Es erweitert die bewährte GRPO-Methode für das gemeinsame Training verschiedener spezialisierter Agenten und soll die Probleme durch drei Innovationen lösen.

Das System bewertet jeden Agenten im Kontext seiner spezifischen Aufgabe. Der Hauptagent wird an der finalen Antwortqualität gemessen, Sub-Agenten an einer Mischung aus lokaler Ausführungsqualität und Beitrag zum Gesamterfolg. M-GRPO berechnet sogenannte "group-relative advantages". Das System vergleicht die Leistung jedes Agenten mit dem Durchschnitt seiner Gruppe und passt das Training entsprechend an. Dabei bleibt die hierarchische Struktur erhalten.
Durch das "Trajectory-Alignment-Schema" werden unterschiedliche Anzahlen von Sub-Agent-Aufrufen ausgeglichen. Das System legt eine Zielanzahl von Sub-Agent-Aktionen fest und dupliziert oder entfernt Trainingsdaten, um einheitliche Batch-Größen zu erreichen. Die Agenten können auf getrennten Servern laufen, einer für den Hauptagenten, einer für Sub-Agenten. Sie tauschen nur minimale Statistiken über eine gemeinsame Datenbank aus, wodurch das Training ohne komplexe serverübergreifende Berechnungen möglich wird.
Präzisere Aufträge, bessere Ergebnisse
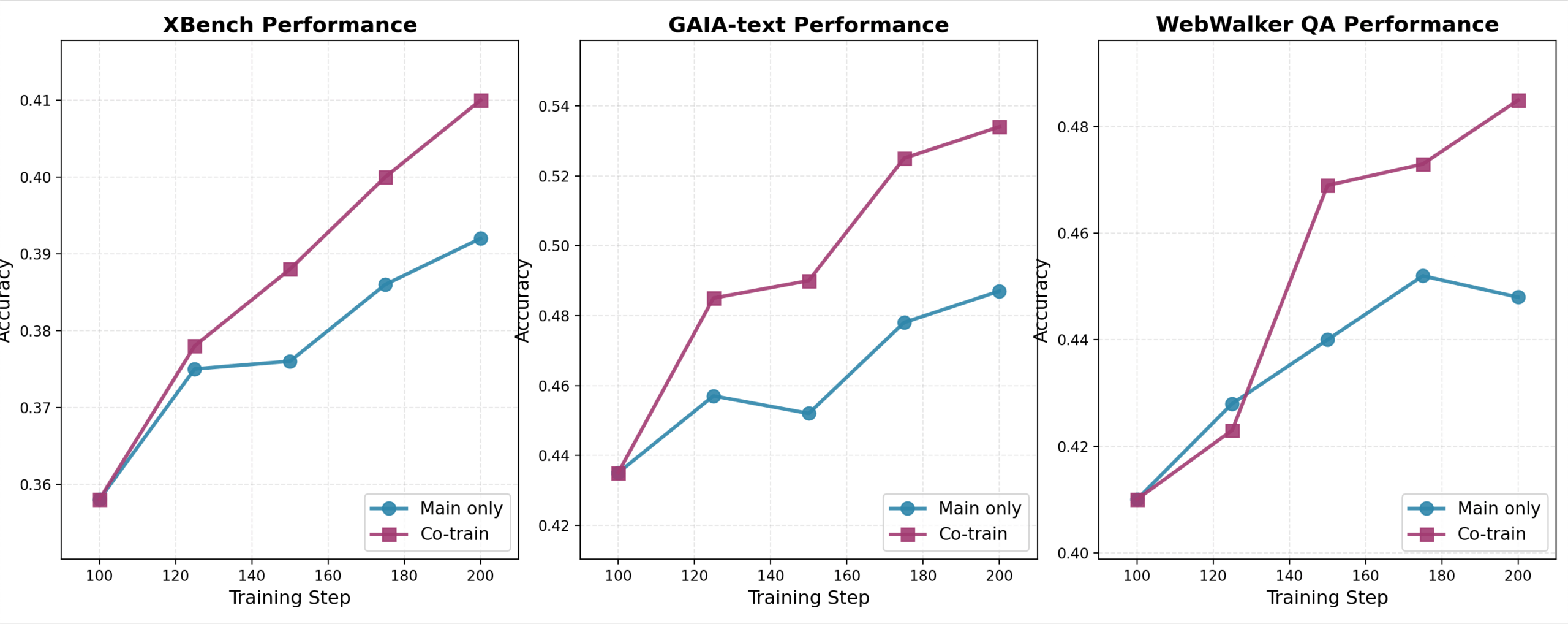
Die Forscher testeten das mit dem Qwen3-30B-Modell auf insgesamt 64 H800-GPUs trainierten M-GRPO-System auf drei anspruchsvollen Benchmarks: GAIA für allgemeine KI-Assistenten-Aufgaben, XBench-DeepSearch für Tool-Nutzung in verschiedenen Bereichen und WebWalkerQA für Web-Navigation.
Das Ergebnis war eindeutig: M-GRPO übertraf sowohl einzelne GRPO-Agenten als auch Multi-Agent-Systeme mit eingefrorenen (nicht weiter trainierten) Sub-Agenten konsistent über alle Benchmarks hinweg. Die Methode zeigte verbesserte Stabilität und benötigte weniger Trainingsdaten für gute Ergebnisse.
Praktische Beispiele verdeutlichen die Verbesserungen. Bei einer komplexen Logik-Aufgabe zu einem Rubik’s Cube wählte das trainierte System das richtige "Reasoner"-Tool für mathematische Ableitungen, während das untrainierte System fälschlicherweise den "Browser" verwendete.
Bei einer Recherche-Aufgabe zu invasiven Fischarten formulierte der trainierte Hauptagent präzisere Aufträge für Sub-Agenten. Statt allgemein nach "invasiven Clownfischen" zu suchen, spezifizierte er "Arten, die invasiv wurden, nachdem Haustierbesitzer sie freiließen". Dieser scheinbar kleine Unterschied war entscheidend für die korrekte Antwort.
Code und Datensätze sind auf GitHub verfügbar.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnieren