Nvidia gibt Unternehmen Zugriff auf große Sprachmodelle, die für Chatbots, digitale Assistenten und andere KI-Anwendungen genutzt werden können.
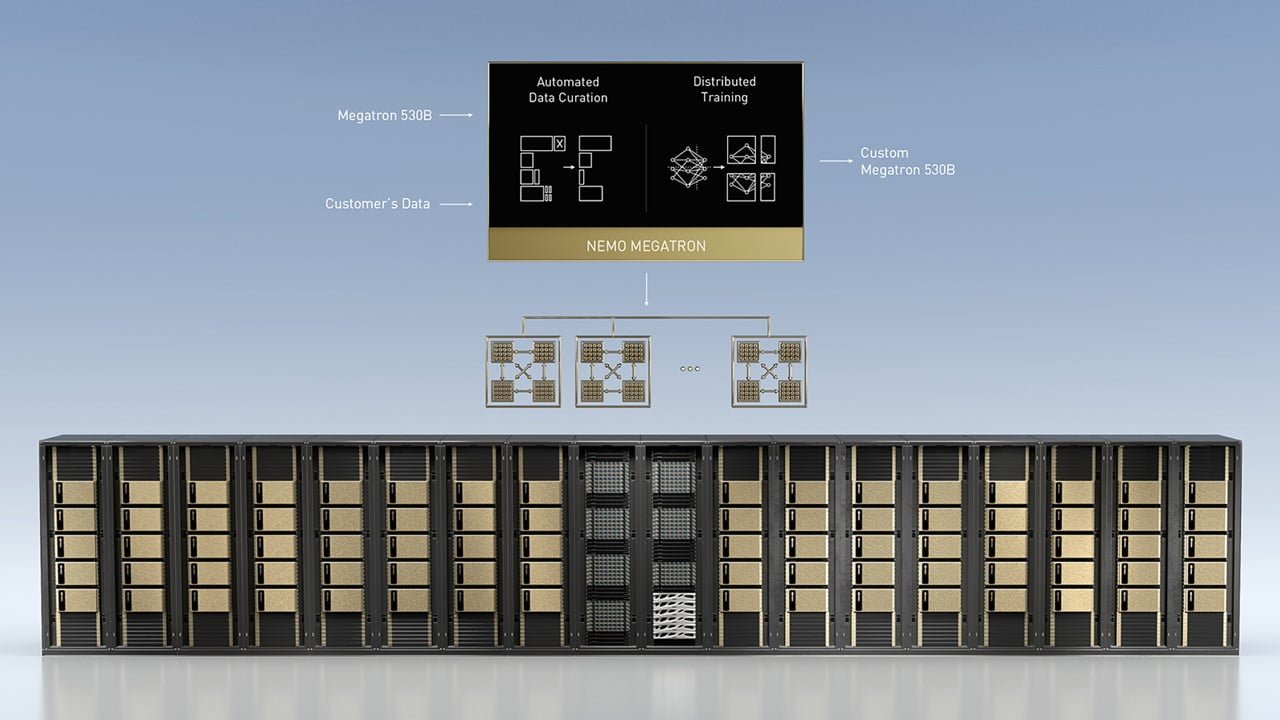
Im Rahmen des diesjährigen GTC (GPU Technology Conference) kündigte Nvidia eine Reihe von Services und Produkten an, die Unternehmen erlauben sollen, eigene KI-Sprachsysteme zu entwickeln und einzusetzen. Dafür setzt Nvidia auf das neue Framework Nvidia NeMo Megatron.
Nvidias NeMo ist ein Baukasten für Künstliche Intelligenz und Sprache und lässt Entwickler:innen simple automatische Spracherkennung (ASR), Sprachverarbeitung (NLP) und Text-zu-Sprach-Synthese (TTS) kombinieren.
Laut Nvidia lassen sich so etwa Video-Transkriptionen oder automatisierte Call-Center-Systeme realisieren. Mit NeMo Megatron geht Nvidia nun den nächsten Schritt und lässt Unternehmen ihre eigenen Sprachmodelle für das Baukastensystem trainieren.
Nvidia NeMo Megatron bietet Zugriff auf aktuell größtes Sprachmodell
NeMo Megatron bietet Unternehmen die Möglichkeit, große Sprachmodelle zu bauen, trainieren und anzupassen – darunter auch Nvidias Megatron 530B. Die 530 Milliarden Parameter große Sprach-KI wurde vor knapp einem Monat von Nvidia und Microsoft als das weltweit größte Sprachmodell vorgestellt. Laut Nvidia erreicht Megatron 530B eine hohe Genauigkeit in zahlreichen Sprachaufgaben, darunter Leseverständnis, logisches Denken und Schlussfolgerungen.
"Große Sprachmodelle haben sich als flexibel und nützlich erwiesen. Sie sind in der Lage, Fragen zu beantworten, Sprachen zu übersetzen, Dokumente zu verstehen und zusammenzufassen, Geschichten zu schreiben und Programme zu coden - und das alles ohne spezielles Training oder Aufsicht", so Bryan Catanzaro, Nvidia-Ressortleiter für angewandte Deep Learning-Forschung.
Mit NeMo Megatron sollen Unternehmen den Aufbau solcher großen Sprachmodelle – auch für neue Sprachen und Aufgaben – zukünftig selbst in der Hand haben.
Nvidia Triton Inference Server soll Sprachmodelle ausführen
Neben NeMo Megatron kündigte Nvidia auch Updates für die Triton Inference Server an, darunter einen KI-Modell-Analyzer, der automatisch die beste Server-Konfiguration für ein KI-Modell findet und "Multi-GPU Multinode-Funktionalität". Mit der sollen riesige Sprachmodelle wie Megatron 530B, die zu groß für den Speicher einer Grafikkarte sind, über mehrere Grafikkarten und Server-Nodes ohne Einbußen in der Inferenz-Geschwindigkeit verteilt werden.
Mit Triton Inference Server könne Megatron 530B auf zwei NVIDIA DGX-Systemen laufen und die Verarbeitungszeit von über einer Minute auf einem klassischen CPU-Server auf eine halbe Sekunde zu reduzieren, schreibt Nvidia. Ein DGX-A100-System mit acht Nvidia A100 80 Gigabyte GPUs kostet knapp 200.000 US-Dollar.

Mit dem NVIDIA LaunchPad, das ebenfalls auf der GTC angekündigt wurde, können Unternehmen die Entwicklung und den Einsatz großer Sprachmodelle kostenlos testen. Sie können sich außerdem für die Teilnahme am Early-Access-Programm für das beschleunigte Framework NVIDIA NeMo Megatron zum Training großer Sprachmodelle bewerben.



