
Um das Verhalten Physik-basierter Charaktere per Sprache zu lenken, kombiniert Nvidias PADL Sprachmodell mit Reinforcement Learning.
Zu den ersten medienwirksamen Bildern der jüngsten KI-Welle gehören sicherlich die sich seltsam bewegenden 3D-Figuren von Deepmind und anderen Forschungseinrichtungen. Diese dreibeinigen Spinnen oder humanoiden 3D-Puppen haben ihre Bewegungen durch Reinforcement Learning gelernt.

Inzwischen gibt es zahlreiche Ansätze, die Bewegungen von digitalen Tieren oder menschenähnlichen Figuren auf diese Weise zu lernen. Ziel dieser Methoden ist es, KI-Systeme zu entwickeln, die für eine Vielzahl simulierter Figuren natürlich wirkende Bewegungen generieren und damit manuelle Animationen und Motion-Capture-Verfahren langfristig ergänzen oder ersetzen können.
Nvidias PADL macht KI-Animationen per Sprache steuerbar
Damit KI-Animationen auch im industriellen Workflow eingesetzt werden können, müssen sie steuerbar sein. Nvidia stellt nun mit "Physics-based Animation Directed with Language" (PADL) ein Framework vor, das Fortschritte in der natürlichen Sprachverarbeitung mit Methoden des Reinforcement Learning zu einem sprachgesteuerten System verbindet.
PADL wird in drei Phasen trainiert: In der Skill-Embedding-Phase trainiert Nvidia über einen Sprach- und einen Bewegungsencoder einen gemeinsamen Embedding Space aus kurzen Videos mit Bewegungen und zugehörigen Textbeschreibungen.
Dieser vereint Sprache und im Video gesehene Fähigkeiten und wird in der zweiten Phase genutzt, um mehrere Strategien (Policies) zur Lösung einfacher Aufgaben zu erlernen, wie die Bewegung zu einem bestimmten Objekt. In der dritten Phase führt Nvidia die verschiedenen gelernten Strategien zusammen (Multi-Task Aggregation).
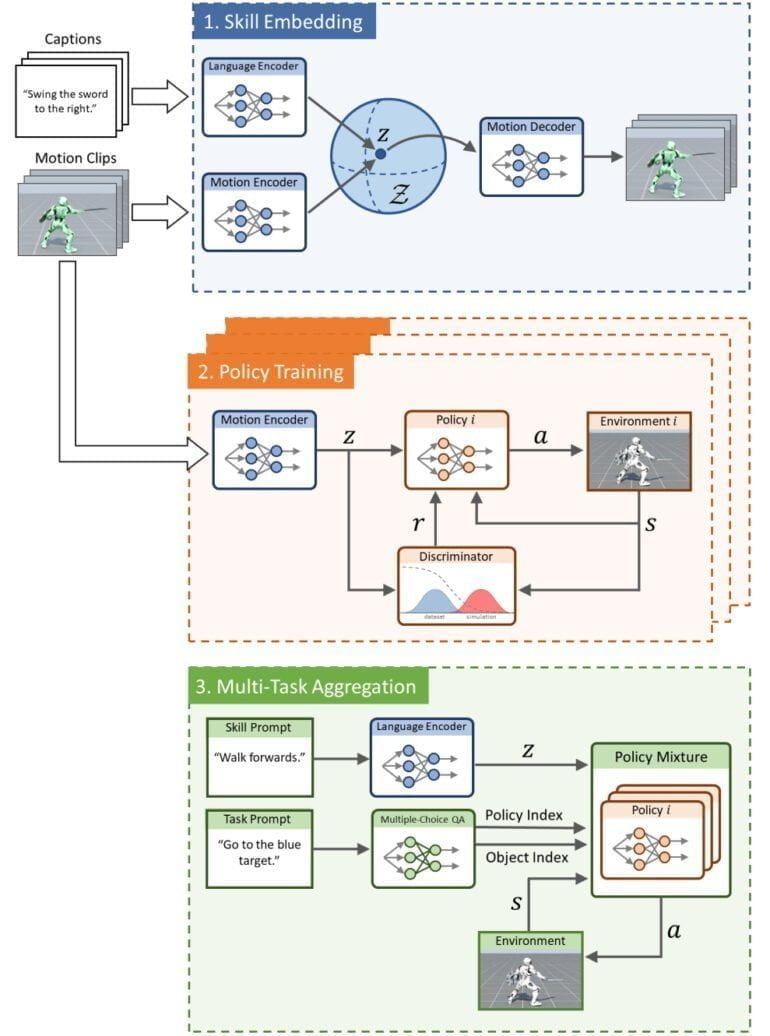
Das so entstandene Modell kann dann per Sprache gesteuert werden: Nutzende können einer Figur per Texteingabe eine bestimmte Aufgabe und eine entsprechende Fähigkeit zuweisen, zum Beispiel "Sprinte zum roten Block" oder "Drehe dich zum Ziel und schlage es mit dem Schild".
Charaktere lernen verwandte Bewegungen automatisch mit
Durch das Training mit den verschiedenen Bewegungen und den entsprechenden Textbeschreibungen kann das Modell zwischen verwandten Bewegungen, wie langsames Laufen und Sprinten, interpolieren.
Im Video sieht man, wie die Figur ihre Geschwindigkeit schrittweise erhöht oder langsam aus dem Stand in die Hocke geht, ohne die Zwischenschritte im Training gesehen zu haben. Mit völlig neuen Fertigkeiten, wie dem Radschlagen, oder gar ungesehenen Aufgaben ist das Modell jedoch überfordert.

Nvidia will PADL mit einem deutlich größeren Datensatz an annotierten Motion-Capture-Aufnahmen für mehr Fähigkeiten trainieren und beim Policy-Training die wenigen festen Aufgaben zugunsten eines allgemeineren Ansatzes aufgeben.
Weitere Informationen gibt es auf der PADL-Projektseite. Der Code wird dort in Kürze veröffentlicht.




