Nvidia veröffentlicht Nemotron 3: Hybride Mamba-Modelle für autonome KI-Agenten

Kurz & Knapp
- Nvidia stellt mit Nemotron-3 eine neue KI-Modellreihe vor, die dank hybrider Mamba- und Transformer-Architektur lange Texte effizient verarbeitet und speziell für agentische KI entwickelt wurde.
- Das Modell Nano ist offen verfügbar und kombiniert hohe Geschwindigkeit mit geringem Speicherbedarf; kommende Modelle bringen zusätzliche Effizienz- und Beschleunigungstechniken.
- Nvidia veröffentlicht neben den Modellgewichten auch Trainingsanleitungen und große Datensätze.
Mit der Nemotron-3-Familie setzt Nvidia auf eine Kombination aus Mamba- und Transformer-Architekturen, um lange Kontextfenster ressourcenschonend auszunutzen.
Mit der neuen Modellgeneration zielt der Konzern spezifisch auf agentische KI ab. Darunter versteht die Industrie KI-Systeme, die komplexe Aufgaben über längere Zeiträume und viele Einzelschritte hinweg autonom bewältigen. Die Familie umfasst die drei Modelle Nano, Super und Ultra, wobei das Einstiegsmodell Nano bereits veröffentlicht wurde. Die leistungsstärkeren Varianten Super und Ultra sollen in der ersten Jahreshälfte 2026 folgen.
Technisch bricht Nvidia mit dem aktuell weitverbreiteten Standard reiner Transformer-Modelle und setzt stattdessen auf eine hybride Struktur. Diese verknüpft effiziente Mamba-2-Schichten mit einzelnen Transformer-Elementen und einem Mixture-of-Experts-Ansatz (MoE), wie auch IBM und Mistral ihn schon getestet haben.
Gegenüber Transformern benötigt es gerade bei langen Eingabesequenzen weniger Ressourcen. Während der Speicherbedarf bei reinen Transformern linear mit der Länge der Eingabe wächst, benötigen die hier überwiegend eingesetzten Mamba-Schichten während der Textgenerierung nur einen konstanten Speicherzustand.
Das ermöglicht bei Nemotron 3 ein Kontextfenster von bis zu einer Million Token, was keinen neuen Rekord markiert, aber sich in eine Reihe mit ressourcenintensiven Frontier-Modellen von OpenAI oder Google stellt. Ein solches Volumen erlaubt es KI-Agenten, ganze Code-Repositories, umfangreiche Dokumentensammlungen oder lange Verlaufshistorien im Arbeitsspeicher zu halten, ohne die Hardware-Anforderungen immer weiter steigen zu lassen.
Effizienz durch hybrides Design
Das nun veröffentlichte Modell Nano verfügt über insgesamt 31,6 Milliarden Parameter, von denen pro Berechnungsschritt jedoch nur 3 Milliarden aktiv sind. Im Benchmark-Aggregator Artificial Analysis Index konkurrieren die Open-Source-Modelle mit gpt-oss-20B oder Qwen3-30B bei der Genauigkeit, weisen aber einen weit höheren Tokendurchsatz auf. Allerdings benötigt es laut Artificial Intelligence mit 160 Millionen Token für einen Test-Durchlauf auch weit mehr als das zweitplatzierte Qwen3-VL mit 110 Millionen.

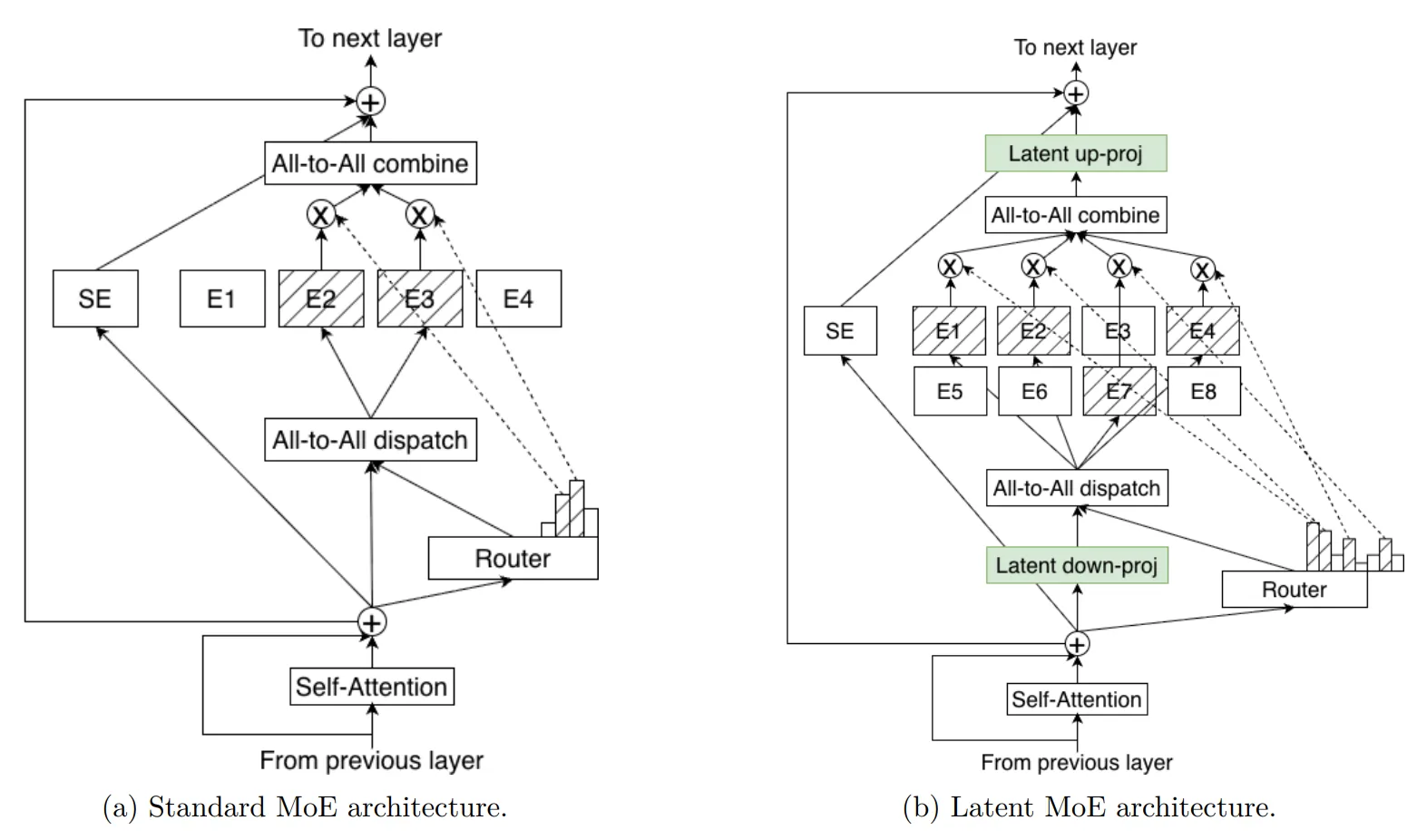
Für die kommenden größeren Modelle Super und Ultra führt Nvidia zwei wesentliche architektonische Neuerungen ein. Die erste Technik nennt sich LatentMoE. Bei herkömmlichen MoE-Modellen werden Token direkt zu Experten-Netzwerken geroutet, was viel Speicherbandbreite kostet.
Die neue Technik projiziert die Token zunächst in eine komprimierte, latente Repräsentation, bevor sie verarbeitet werden. das erlaubt es laut Nvidia, die Anzahl der Experten und die Anzahl der aktiven Experten pro Token drastisch zu erhöhen, ohne die Inferenzgeschwindigkeit zu drosseln.
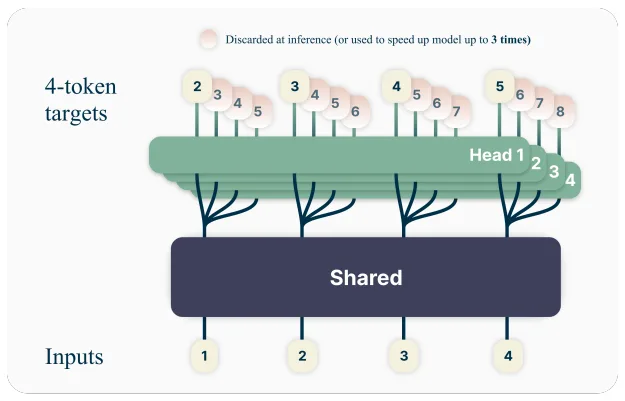
Zusätzlich nutzen die großen Modelle eine sogenannte Multi-Token-Prediction (MTP). Dabei sagen die Modelle während des Trainings mehrere zukünftige Token gleichzeitig voraus. Das soll das logische Schlussfolgern verbessern und gleichzeitig die Textgenerierung beschleunigen. Trainiert werden Super und Ultra im neuen 4-Bit-Gleitkommaformat NVFP4, das speziell auf die Blackwell-GPU-Architektur zugeschnitten ist.
Nvidia legt Datensätze offen
Ungewöhnlich für einen großen KI-Akteur ist der Umfang der Veröffentlichung. Nvidia stellt nicht nur die Modellgewichte für die Nano-Version unter einer offenen Lizenz bereit, sondern veröffentlicht auch die Trainingsrezepte und große Teile der verwendeten Datensätze auf Hugging Face.
Dazu gehören der Datensatz Nemotron-CC-v2.1 mit 2,5 Billionen Token basierend auf Common Crawl, Nemotron-CC-Code-v1 mit 428 Milliarden Code-Token sowie synthetische Datensätze für mathematisches Denken, wissenschaftliches Programmieren und agentische Sicherheit.
Das Training der Modelle erfolgte mittels Reinforcement Learning (RL) in einer Vielzahl von Umgebungen gleichzeitig. Dieses Multi-Environment-RL soll verhindern, dass das Modell Fähigkeiten in einem Bereich verliert, während es in einem anderen optimiert wird. Entwickler können über die Open-Source-Bibliothek NeMo Gym eigene RL-Umgebungen nutzen.
Schon vor einigen Monaten hatte Nvidia die Industrie dazu aufgerufen, die Forschung mit Blick auf agentischen Einsatz eher in Richtung kleinerer Sprachmodelle zu lenken. Nemotron-3 mit Fokus auf Geschwindigkeit statt Leistung scheint daher ein logischer Schritt in dieser Strategie.
Etwas verwirrend ist indes die Nummerierung: Nemotron-4, das auf die Generierung synthetischer Trainingsdaten spezialisiert ist, hatte das US-Unternehmen bereits im Sommer 2024 präsentiert.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnieren