Nvidias eDiffi ist eine beeindruckende DALL-E-Alternative

Nvidias eDiffi ist ein generatives KI-Modell für Text-zu-Bild und schlägt laut Nvidia Alternativen wie DALL-E 2 oder Stable Diffusion.
Nach OpenAI, Google, Midjourney und StabilityAI zeigt nun auch Nvidia ein generatives Text-zu-Bild KI-Modell. Bekannte Beispiele für solche Systeme sind DALL-E 2, Midjourney, Imagen oder Stable Diffusion.
Alle großen generativen KI-Modelle im Text-zu-Bild-Bereich sind Diffusion Modelle. In diesen Modellen erfolgt die Bildsynthese über einen iterativen Entrauschungsprozess, der namensgebenden Diffusion. So entstehen aus zufälligem Rauschen schrittweise Bilder.
Nvidias eDiffi setzt auf Denoiser-Experten
In den bisher veröffentlichten oder vorgestellten Varianten wird üblicherweise ein einziges Modell trainiert, alle Bildschritte im kompletten Prozess zu entrauschen. Das jetzt von Nvidia vorgestellte eDiffi-Modell setzt dagegen auf ein Ensemble von Experten-Denoisern, die auf das Entrauschen verschiedener Intervalle des generativen Prozesses spezialisiert sind.
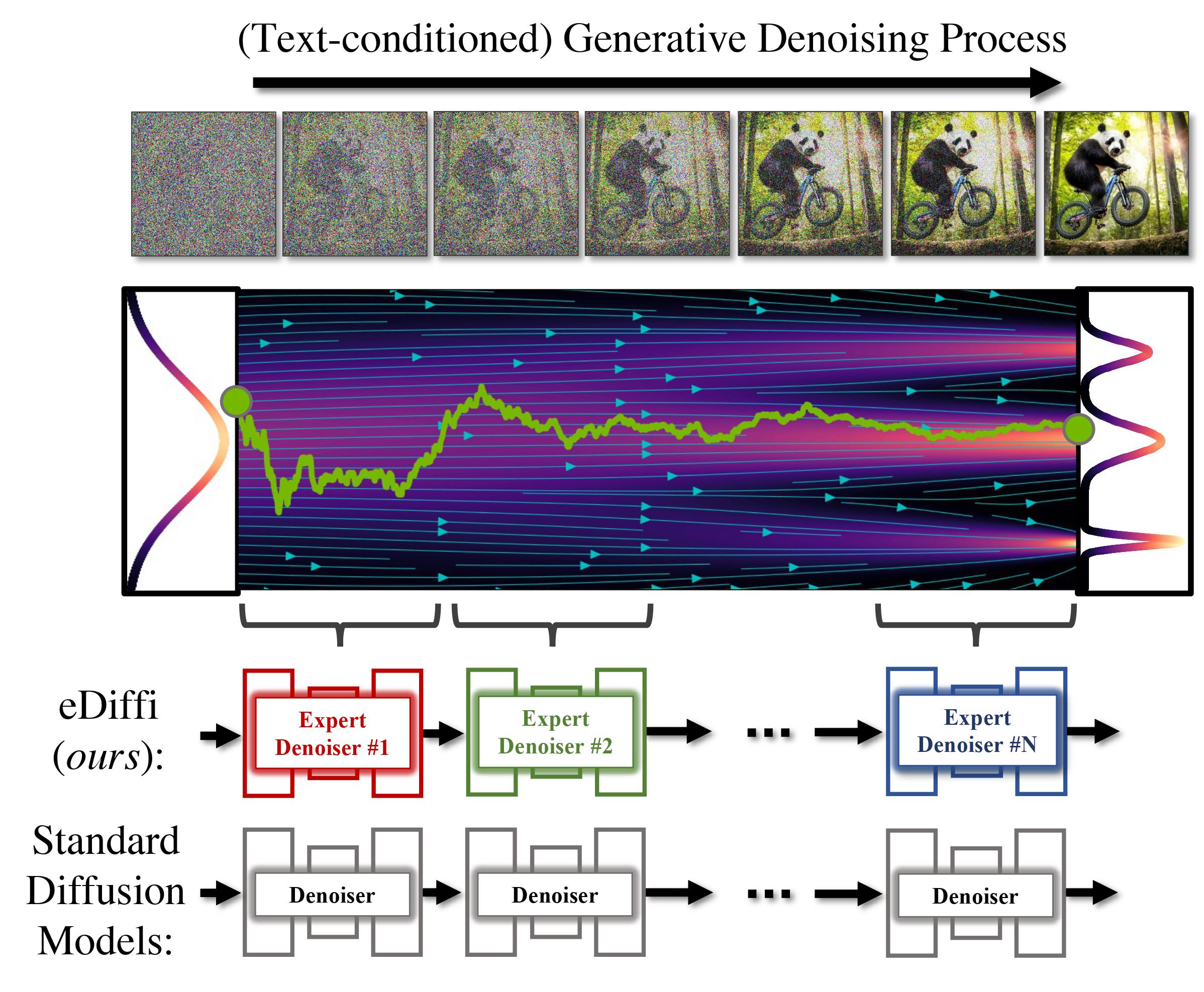
Laut Nvidia produziert eDiffi durch die Verwendung der verschiedenen Experten im Vergleich mit DALL-E 2 oder Stable Diffusion bessere Ergebnisse. So kann eDiffi besser Text in Bildern generieren und hält sich in den von Nvidia gezeigten Beispielen besser an die inhaltlichen Vorgaben der ursprünglichen Text-Eingabe.

Nvidias Modell setzt auf eine Kombination aus drei Diffusionsmodellen: einem Basismodell, das Bilder mit einer Auflösung von 64x64 synthetisieren kann, und zwei Super-Resolution-Modelle, die die Bilder schrittweise auf eine Auflösung von 256x256 oder 1024x1024 hochrechnen.
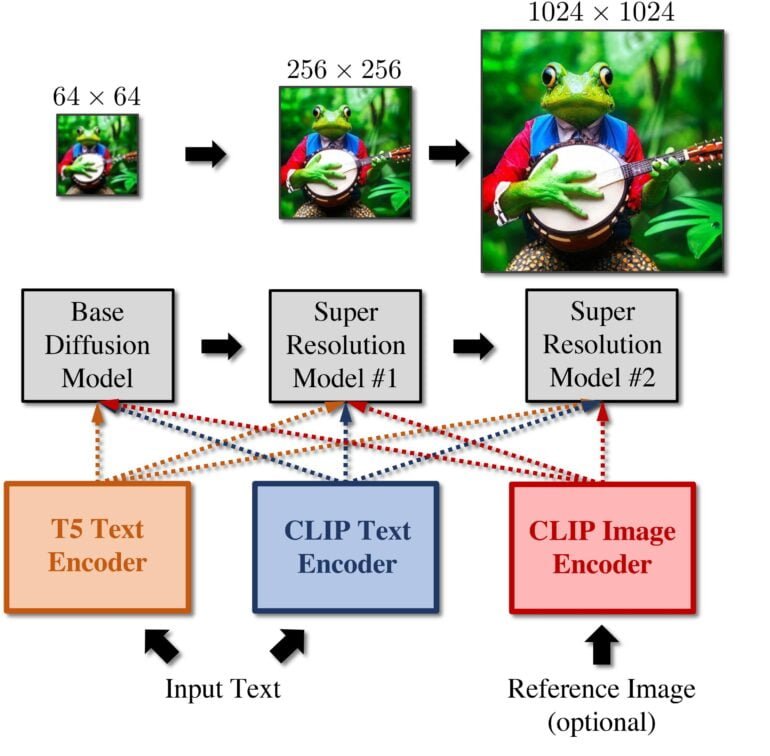
Die Modelle berechnen zudem zu den üblichen CLIP Text- und Bild-Embeddings auch T5 Text-Embeddings. T5 ist Googles Text-zu-Text Transformer und ergänzt laut Nvidia die CLIP-Embeddings. Die Kombination der zwei Text-Embeddings erzeugt laut Nvidia detailliertere und besser an der Eingabe orientierte Bilder.
Nvidia eDiffi bietet "Malen mit Worten"
EDiffi kann neben Text-Eingaben ein Referenzbild als Eingabe verarbeiten und dessen Stil für die eigene Bildsynthese nutzen. Nvidia zeigt zusätzlich eine "Malen mit Worten"-Funktion, bei der Benutzer:innen die Position der in der Texteingabeaufforderung erwähnten Objekte kontrollieren können, indem sie zuerst eine Skizze anfertigen, anschließend Wörter auswählen und sie auf das Bild schreiben.
Video: Nvidia
Nvidia hält sich bedeckt zu zukünftigen Plänen mit eDiffi. Bisher ist lediglich ein Paper verfügbar. Doch die vorgestellten Veränderungen in der Trainings-Pipeline könnten in Zukunft auch für neue Modelle von DALL-E oder Stable Diffusion genutzt werden und dort große Fortschritte bei der Qualität und Kontrolle über die synthetisierten Bilder ermöglichen.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.