OmniGen 2 vereint Bild und Text wie GPT-4o, ist aber Open Source

Forschende der Beijing Academy of Artificial Intelligence haben OmniGen 2 vorgestellt, ein Open-Source-Modell für Text-zu-Bild-Generation, Bildbearbeitung und kontextuelle Generierung.
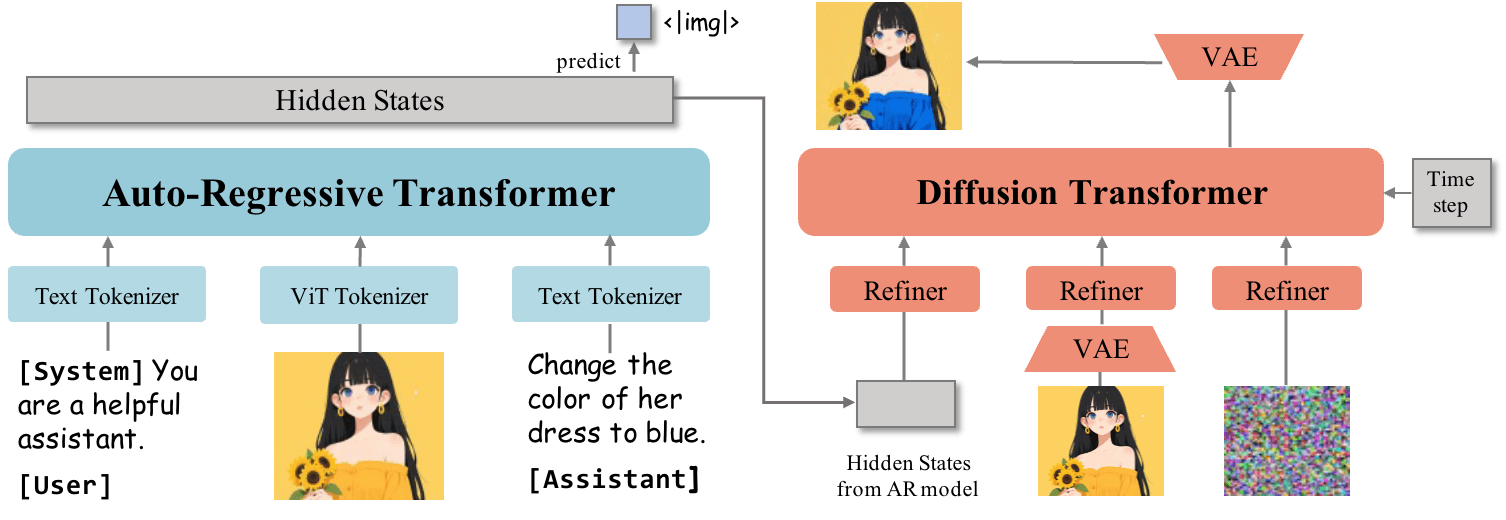
Im Gegensatz zum im November 2024 veröffentlichten Vorgänger OmniGen verwendet OmniGen2 zwei getrennte Dekodierungspfade für Texte und Bilder mit ungeteilten Parametern und einem entkoppelten Bildtokenizer. Diese Architektur ermöglicht es dem Modell laut den Wissenschaftler:innen, auf bestehenden multimodalen Verständnismodellen aufzubauen, ohne deren ursprüngliche Textgenerierungsfähigkeiten zu beeinträchtigen.

Das System basiert auf einem multimodalen Large Language Model (MLLM) mit einem Qwen2.5-VL-3B-Transformer als Grundlage. Für die Bildgenerierung kommt ein spezieller Diffusion Transformer mit etwa vier Milliarden Parametern zum Einsatz. Ein spezielles Token "<|img|>" signalisiert dem System, wann es von der Textgenerierung zur Bildgenerierung wechseln soll.
Beim Training verwendeten die Wissenschaftler:innen etwa 140 Millionen Bilder aus verschiedenen Open-Source-Datensätzen und eigenen Sammlungen. Zusätzlich entwickelten sie spezielle Verfahren, die Videomaterial nutzen, um bessere Trainingsdaten zu erstellen.
Um die Bildbearbeitungsfähigkeiten zu verbessern, extrahiert das System zwei ähnliche Bilder aus Videos - etwa ein Gesicht mit und ohne Lächeln - und lässt dann ein Sprachmodell eine passende Bearbeitungsanweisung formulieren.

Für die kontextuelle Generierung verfolgt OmniGen 2 Personen oder Objekte durch mehrere Video-Frames, um zu lernen, wie dasselbe Motiv in verschiedenen Situationen aussieht.

Neuartige Positionseinbettung für multimodale Prompts
Die Forschenden entwickelten eine spezielle "Omni-RoPE"-Positionseinbettung, die Positionsinformationen in drei Komponenten aufteilt: einen Sequenz- und Modalitätsidentifikator, der verschiedene Bilder unterscheidet, sowie 2D-Koordinaten für die räumliche Position innerhalb jeder Bildeinheit. Diese Technik soll besonders bei Bildbearbeitung und kontextueller Generation die Konsistenz verbessern.

Ein weiterer technischer Unterschied: OmniGen2 nutzt VAE-Features (Variational Autoencoder) ausschließlich als Eingabe für den Diffusion-Decoder, anstatt sie in das multimodale Sprachmodell zu integrieren. Das soll die Architektur vereinfachen und die ursprünglichen Verständnisfähigkeiten des Sprachmodells erhalten.
Reflection-Mechanismus für iterative Verbesserung
Eine besondere Neuerung ist der Reflection-Mechanismus, der es OmniGen2 ermöglicht, generierte Bilder selbst zu bewerten und iterativ zu verbessern. Das System analysiert Mängel im generierten Bild und schlägt spezifische Korrekturen vor.

Da bisherige Benchmarks für kontextuelle Generation unzureichend gewesen seien, führten die Forschenden den OmniContext-Benchmark ein. Dieser umfasst drei Kategorien - Character, Object und Scene - mit insgesamt acht Teilaufgaben und je 50 Beispielen pro Aufgabe.
Die Evaluierung erfolgt durch GPT-4.1, das sowohl Prompt-Befolgung als auch Subjektkonsistenz auf einer Skala von 0 bis 10 bewertet. OmniGen2 erreichte einen Gesamtscore von 7,18 und übertraf damit alle anderen Open-Source-Modelle deutlich. GPT-4o, das seit Kurzem ebenfalls native Bildgenerierung unterstützt, erreicht 8,8.
Bei der Text-zu-Bild-Generation erzielte OmniGen2 auf wichtigen Benchmarks wie GenEval und DPG-Bench kompetitive Ergebnisse. In der Bildbearbeitung etablierte sich das Modell als neuer State-of-the-Art unter den Open-Source-Modellen.
Das Modell weist aber auch noch einige Einschränkungen auf: Englische Prompts funktionierten zuverlässiger als chinesische, Körperformmodifikationen bereiteten Schwierigkeiten, und die Ausgabequalität hänge stark von der Eingabebildqualität ab. Bei mehrdeutigen Multi-Bild-Eingaben benötigt das System außerdem explizite Anweisungen zur Zuordnung von Objekten.
Die Forschenden planen, sowohl die Modelle als auch die Trainingsdaten und Konstruktionspipelines der Community auf Hugging Face zur Verfügung zu stellen.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.