OmniHuman-1: ByteDance kann Menschen jetzt fotorealistisch animieren

Forscher:innen des TikTok-Mutterkonzerns ByteDance haben mit OmniHuman-1 ein neues Framework vorgestellt, um aus Bild- und Audiobeispielen Videos zu generieren.
Das System basiert auf der Diffusion-Transformer-Architektur (DiT) und erzeugt aus einem Referenzbild und Audioclip, etwa einem Songschnipsel, kurze Videos. In diesem Beispiel bringt OmniHuman-1 so Nvidias CEO Jensen Huang zum Singen.
https://www.youtube.com/watch?v=XF5vOR7Bpzs
Bisherige Ansätze zur datengetriebenen Generierung menschlicher Bewegungen in Videos stießen laut den Forscher:innen schnell an Grenzen, wenn es um die Skalierbarkeit ging. Die Datenmenge zu vergrößern führe nicht zwangsläufig zu besseren Resultaten, da ein Großteil der Rohdaten irrelevante Informationen enthalte und daher aufwendig gefiltert werden müsse. Dabei gingen wertvolle Bewegungsmuster verloren.
Mehrstufiges Training berücksichtigt auch Körperposen
Die Forscher:innen begegnen diesem Problem in OmniHuman, indem sie mehrere bewegungsbezogene Bedingungen in das Training einfließen lassen - darunter Text, Audio und Körperposen. Auf diese Weise können sie einen viel größeren Anteil der verfügbaren Daten gewinnbringend nutzen. Durch die Kombination der Modalitäten und die Anpassung ihrer Gewichtung im Trainingsprozess lernt das System, die Vorteile jeder Bedingung optimal auszunutzen, heißt es im Paper. Der Trainingsdatensatz umfasste insgesamt rund 19.000 Stunden Videomaterial.
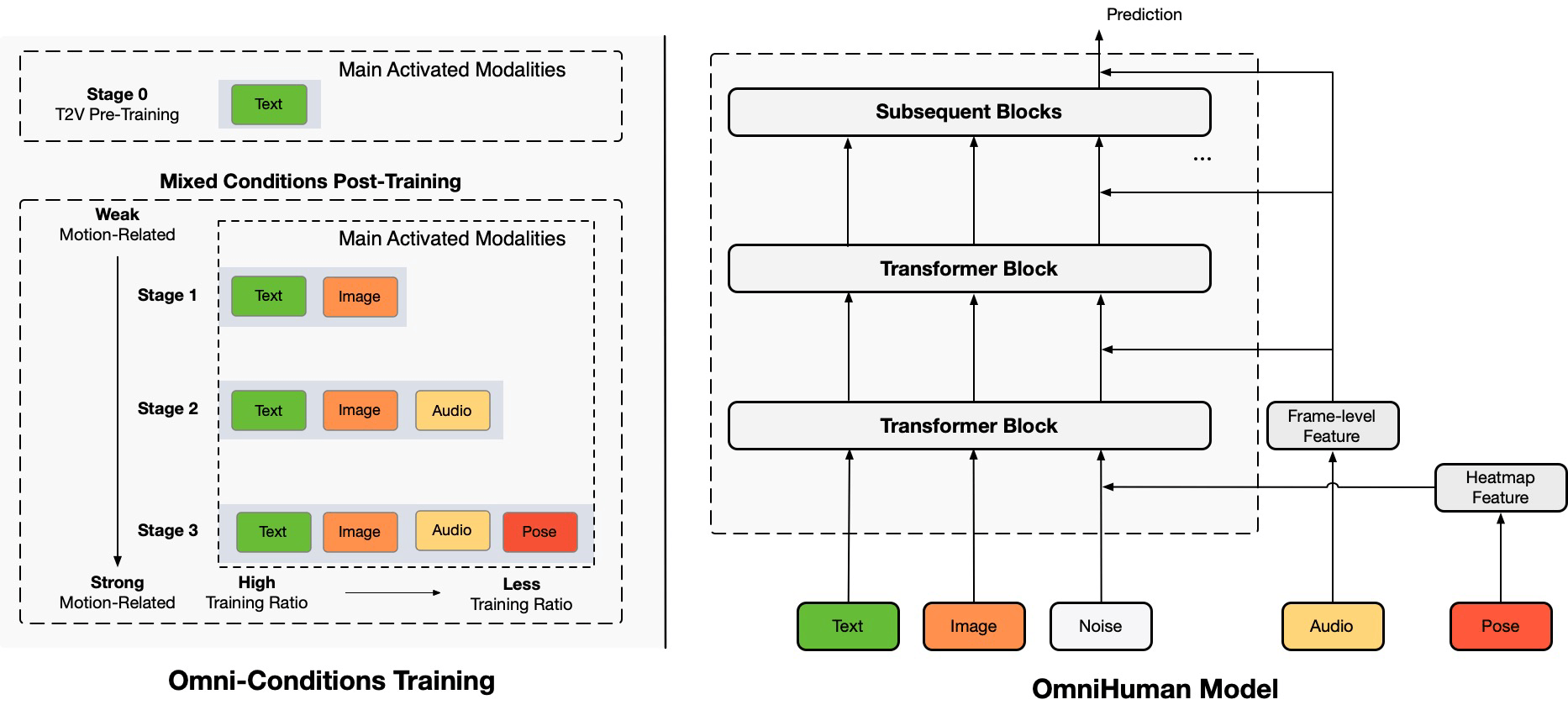
Das OmniHuman-Modell verarbeitet die verschiedenen Eingaben zunächst separat und komprimiert die darin enthaltenen Bewegungsinformationen. Aus Text-Beschreibungen, Referenzbildern, Audiosignalen und Bewegungsdaten entsteht so eine kompakte Zwischendarstellung. Diese verfeinert es dann schrittweise zu einem videorealistischen Output. Durch den Abgleich mit echten Videos hat das Modell gelernt, Details und flüssige Bewegungsabläufe zu erzeugen.

OmniHuman produziert so lebensechte Mundbewegungen und natürlich wirkende Begleitgestik, die gut zum Gesprochenen passen. Auch bei Körperproportionen und Umgebungen, mit denen bisherige Modelle Schwierigkeiten hatten, liefert es überzeugende Ergebnisse.
Neben Fotos echter Menschen animiert OmniHuman auch Cartoon-Figuren eindrucksvoll.
Video: ByteDance
Theoretisch unbegrenzt lange KI-Videos
Die Länge der generierten Videos ist offenbar nicht seitens des Modells beschränkt, sondern lediglich durch den verfügbaren Speicher. Auf der Projektseite finden sich zahlreiche Beispiele zwischen fünf und 25 Sekunden.
Erst vor wenigen Wochen hat ByteDance mit INFP ein ganz ähnliches Forschungsprojekt vorgestellt, das auf die Animation von Gesichtern in Dialogsituationen ausgelegt ist.
Mit TikTok und dem Video-Editor CapCut verfügt ByteDance über Plattformen mit riesigen Nutzerzahlen, auf denen schon jetzt großflächig KI-Funktionen zum Einsatz kommen. Im Februar 2024 kündigte ByteDance an, bei KI "all-in" gehen zu wollen.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.