Open ASR Leaderboard vergleicht über 60 Spracherkennungssysteme transparent

Ein internationales Forscherteam hat eine umfassende Bewertungsplattform für automatische Spracherkennung entwickelt. Das Open ASR Leaderboard soll faire Vergleiche zwischen verschiedenen Transkriptionssystemen ermöglichen.
Entwickelt wurde das System von einem Team aus Hugging Face, Nvidia, der University of Cambridge und Mistral AI. Laut der veröffentlichten Studie wurden bereits über 60 Open-Source- und kommerzielle Modelle von 18 verschiedenen Unternehmen getestet.
Die Bewertung erfolgt in drei Kategorien. Die erste umfasst englische Spracherkennung, die zweite mehrsprachige Tests für Deutsch, Französisch, Italienisch, Spanisch und Portugiesisch. Die dritte Kategorie konzentriert sich auf längere Audiodateien über 30 Sekunden, da manche Modelle bei kurzen und langen Aufnahmen unterschiedlich gut abschneiden.
Das Team verwendet zwei zentrale Messwerte:
- Die Word Error Rate (WER) gibt an, wie viele Wörter falsch erkannt werden. Je niedriger dieser Wert, desto besser die Transkription.
- Der Inverse Real-Time Factor (RTFx) misst die Geschwindigkeit. Er zeigt, wie schnell ein System im Verhältnis zur tatsächlichen Audiodauer arbeitet. Ein RTFx von 100 bedeutet, dass eine Minute Audio in 0,6 Sekunden transkribiert wird.
Um verschiedene Modelle fair vergleichen zu können, werden alle Texte vor der Bewertung vereinheitlicht. Satzzeichen und Groß- und Kleinschreibung werden entfernt, Zahlen in Wörter umgewandelt und Füllwörter wie "äh" oder "mhm" gestrichen. Diese Normalisierung folgt dem Standard des bekannten Whisper-Modells von OpenAI.
Genauigkeit kostet Geschwindigkeit
Bei der englischen Spracherkennung zeigen sich deutliche Unterschiede zwischen verschiedenen Systemtypen. Modelle, die auf großen Sprachmodellen basieren, erreichen die besten Erkennungsraten. Nvidias Canary Qwen 2.5B führt mit einer WER von 5,63 Prozent.
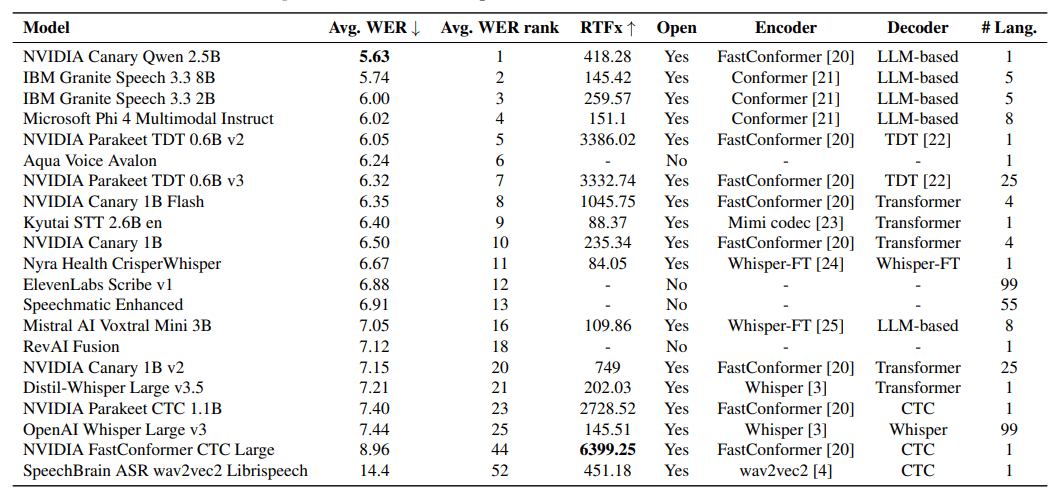
Diese hohe Genauigkeit hat jedoch einen Nachteil bei der Geschwindigkeit. Die Systeme mit großen Sprachmodellen benötigen deutlich länger für die Verarbeitung als andere Technologien. Alternative Ansätze arbeiten wesentlich schneller, machen aber mehr Fehler bei der Worterkennung. Nvidias Parakeet CTC 1.1B verarbeitet Audio beispielsweise 2728-mal schneller als in Echtzeit, erreicht aber nur Platz 23 bei der Fehlerrate.
Mehrsprachigkeit geht auf Kosten der Spezialisierung
Die Tests in verschiedenen Sprachen offenbaren einen wichtigen Zielkonflikt. Modelle, die speziell für eine Sprache optimiert wurden, verlieren oft ihre Fähigkeiten in anderen Sprachen. Whisper-Varianten, die nur auf Englisch trainiert wurden, übertreffen das ursprüngliche mehrsprachige Whisper Large v3 bei englischen Texten, verstehen aber weniger oder gar keine anderen Sprachen mehr.
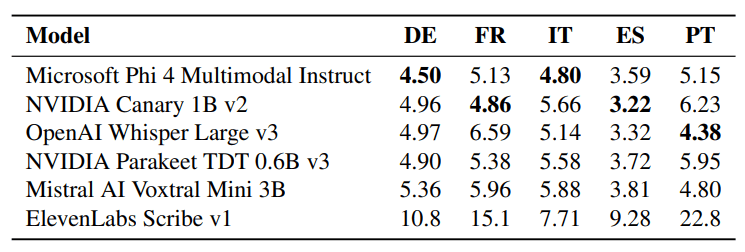
Microsofts Phi-4-Multimodal-Instruct führt auf Deutsch und Italienisch die mehrsprachigen Tests an. Nvidias Modellreihe zeigt den Trade-off besonders deutlich. Die v3-Version des Parakeet TDT unterstützt 25 Sprachen statt nur einer wie die v2-Version, schneidet aber bei englischen Texten schlechter ab.
Open Source schlägt kommerzielle Anbieter
Bei kurzen Audiodateien dominieren frei verfügbare Modelle die Ranglisten. Das beste kommerzielle System, Aqua Voice Avalon, erreicht nur Platz 6. Für proprietäre Dienste lassen sich die Geschwindigkeitswerte nicht fair messen, da Upload-Zeiten und andere Faktoren die Ergebnisse verfälschen.
Anders sieht es bei langen Audiodateien aus. Hier führen kommerzielle Anbieter wie Elevenlabs Scribe v1 mit 4,33 Prozent WER und RevAI Fusion mit 5,04 Prozent. Die Autoren vermuten, dass diese Systeme von spezieller Optimierung für längere Inhalte und professioneller Infrastruktur profitieren.
Kompletter Code öffentlich verfügbar
Das gesamte Bewertungssystem ist auf GitHub frei zugänglich. Entwickler:innen können neue Modelle durch Pull-Requests hinzufügen. Dafür müssen sie Skripte bereitstellen, die ihr System auf den Testdaten evaluieren. Die verwendeten Datensätze sind über den Hugging Face Hub verfügbar und können direkt im Browser erkundet werden.
Die Initiator:innen planen, das Leaderboard um weitere Sprachen und Anwendungsbereiche zu erweitern. Künftige Versionen sollen zusätzliche Messwerte einbeziehen und bisher wenig erforschte Kombinationen verschiedener Systemkomponenten testen. Mit dem Erfolg großer Sprachmodelle erwarten sie mehr Ansätze, die diese Technologie für Spracherkennung nutzen.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.