Open-Source-KI GeoVista findet Aufnahmeorte von Fotos durch Zoom und Websuche
Ein Forschungsteam aus China hat mit GeoVista ein Open-Source-KI-Modell vorgestellt, das Bilder analysiert und gleichzeitig das Internet durchsucht, um deren Aufnahmeort zu bestimmen. Das Modell soll die Leistung kommerzieller Systeme wie Gemini-2.5-flash erreichen.
Das von Forschern verschiedener chinesischer Universitäten und Tencent entwickelte Modell nutzt zwei Werkzeuge während seiner Analyse. Mit einem Zoom-Tool vergrößert es interessante Bildregionen, während ein Suchwerkzeug bis zu zehn relevante Informationsquellen wie Tripadvisor, Instagram, Facebook, Pinterest und Wikipedia aus dem Internet abruft. GeoVista entscheidet dabei selbstständig, wann und wie es diese Tools einsetzt.
Websuche unterscheidet GeoVista von anderen Modellen
Die Forscher sehen in der Integration von Websuche einen wichtigen Unterschied zu bestehenden Ansätzen. Während sich Modelle wie das von Bytedance entwickelte Mini-o3 oder DeepEyes auf Bildmanipulation konzentrieren, greift GeoVista aktiv auf externes Wissen zu. Über welchen Suchanbieter das geschieht, bleibt im Paper unbeantwortet.

Das Team hat GeoVista auf Basis von Qwen2.5-VL-7B-Instruct entwickelt. Das Training bestand aus zwei Phasen. Zunächst lernte das Modell in einer überwachten Lernphase grundlegende Denkmuster und Werkzeugnutzung anhand von 2000 kuratierten Beispielen. Dabei nutzen die Forscher kommerzielle KI-Modelle, um Beispiele für Tool-Aufrufe mit Begründungen zu generieren. Diese werden dann zu mehrstufigen Denkabläufen zusammengesetzt.
In der zweiten Phase optimierte Reinforcement Learning mit 12000 Trainingsbeispielen die Fähigkeiten weiter. Für diese Phase entwickelten die Forscher ein Belohnungssystem, das die mehrstufige Struktur geografischer Angaben nutzt. Korrekte Antworten auf Stadtebene erhalten höhere Belohnungen als solche auf Provinz- oder Länderebene.
Open-Source-Modell erreicht kommerzielle Leistung
In Tests auf dem eigens kuratierten GeoBench erreichte GeoVista laut den Forschern 92,64 Prozent Genauigkeit auf Länderebene, 79,60 Prozent auf Provinzebene und 72,68 Prozent auf Stadtebene. Bei Panoramen liegt die Stadtgenauigkeit bei 79,49 Prozent, bei Fotos bei 72,27 Prozent. Satellitenbilder stellen mit 44,92 Prozent die größte Herausforderung dar.
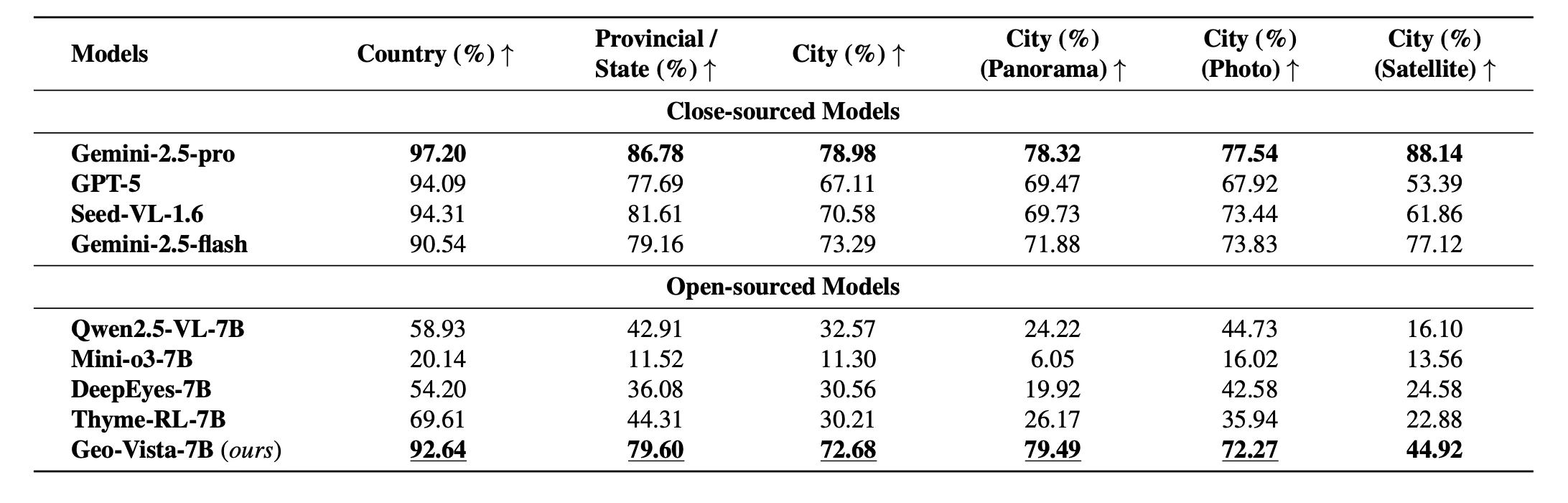
Zum Vergleich erreicht Gemini-2.5-pro 78,98 Prozent auf Stadtebene, GPT-5 67,11 Prozent und Gemini-2.5-flash 73,29 Prozent. Andere Open-Source-Modelle wie Mini-o3-7B kommen nur auf 11,3 Prozent, andere immerhin auf rund 30 Prozent. Es ist gut denkbar, dass das kürzlich vorgestellte Gemini 3 sogar noch bessere Ergebnisse in dem Benchmark erzielt.
Bei der präzisen Distanzmessung liegen 52,83 Prozent der GeoVista-Vorhersagen innerhalb von drei Kilometern zum tatsächlichen Standort. Der Median der Abweichung beträgt 2,35 Kilometer. Gemini-2.5-pro erreicht 64,45 Prozent bei 800 Metern im Median, GPT-5 kommt auf 55,12 Prozent bei 1,86 Kilometern.
Modell lernt fehlerfreie Werkzeugnutzung ohne direkte Anweisung
Testläufe ohne einzelne Trainingskomponenten zeigen laut den Forschern die Notwendigkeit beider Trainingsphasen. Ohne die erste überwachte Lernphase kollabiert die Leistung, da das Modell zu kurze Antworten generiert und zögert, Werkzeuge aufzurufen. Ohne Reinforcement Learning bleibt die Leistung ebenfalls deutlich zurück. Das gestufte Belohnungssystem erwies sich als entscheidend für die volle Nutzung der mehrstufigen geografischen Angaben.
Eine interessante Beobachtung der Forscher betrifft fehlerhafte Werkzeugaufrufe. Während des Reinforcement-Learning-Trainings sank die Rate fehlerhafter Tool-Aufrufe, obwohl diese nicht direkt optimiert wurde. Die Forscher beobachteten zudem einen kontinuierlichen Leistungsanstieg mit wachsender Datenmenge. Tests mit 1500, 3000, 6000 und 12000 Trainingsbeispielen bestätigen durchgehende Verbesserungen. Bei logarithmischer Darstellung der Datengröße zeigt sich ein nahezu linearer Zusammenhang zur Leistung.
Neuer Benchmark filtert triviale und unlösbare Aufgaben
Parallel zu GeoVista haben die Forscher GeoBench veröffentlicht, einen Testdatensatz mit 1.142 hochauflösenden Bildern aus 66 Ländern und 108 Städten weltweit. Der Datensatz umfasst 512 Standardfotos, 512 Panoramen und 108 Satellitenbilder. Alle Bilder haben mindestens eine Million Pixel Auflösung.
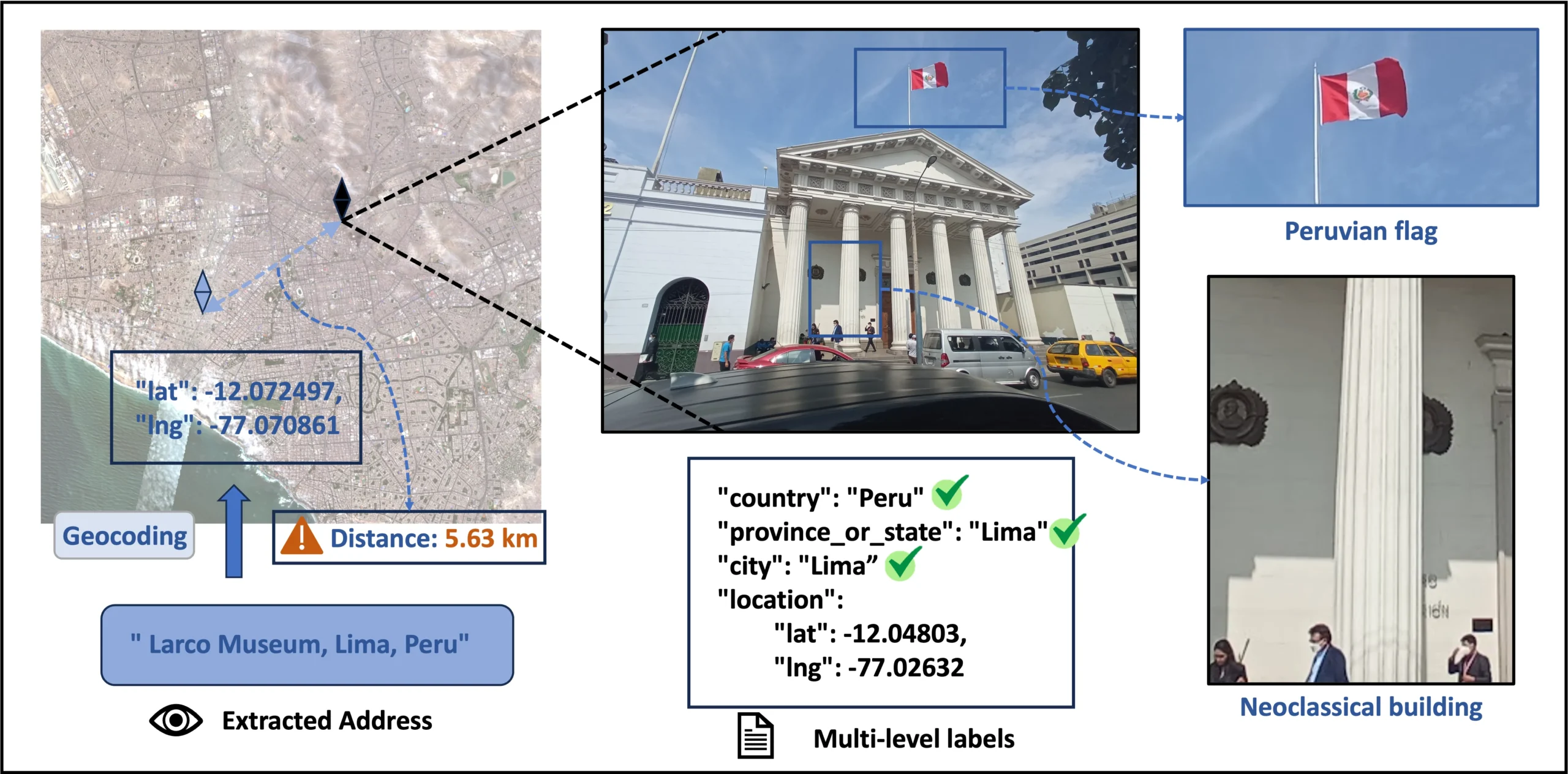
GeoBench unterscheidet sich von bestehenden Benchmarks wie OpenStreetView-5M oder GeoComp durch strengere Filterkriterien. Die Forscher entfernten nicht-lokalisierbare Bilder wie Nahaufnahmen von Essen oder generische Landschaften sowie leicht erkennbare Wahrzeichen. Sie begründen das damit, dass Bilder aus dem Internet unterschiedliche Grade an Lokalisierbarkeit zeigten.
Der Benchmark ermöglicht zwei Bewertungsformen. Eine stufenweise Bewertung prüft die Genauigkeit auf Länder-, Provinz- und Stadtebene. Eine präzise Distanzmessung wandelt Textadressen über Geocoding-Dienste in Koordinaten um und berechnet die tatsächliche Entfernung zum korrekten Standort auf der Erdkugel.
Die Forscher haben die Modellgewichte, den Code und den Benchmark über eine Projektseite öffentlich zugänglich gemacht. Zu möglichen Risiken und Datenschutzproblemen äußern sich die Forscher in dem Paper nicht. Dabei liegt nahe, dass solche Technologien die Privatsphäre gefährden können. Wer also Fotos öffentlich postet, sollte bedenken, dass KI-Modelle daraus inzwischen den nahezu exakten Aufnahmeort ermitteln können.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.