Open Source KI-Modell GLM-5 fordert Claude Opus 4.5 und GPT-5.2 im Coding heraus
Kurz & Knapp
- Zhipu AI veröffentlicht GLM-5, ein Open-Source-Modell mit 744 Milliarden Parametern unter MIT-Lizenz, das bei Coding und Agenten-Aufgaben laut Herstellerangaben mit Claude Opus 4.5 und GPT-5.2 mithalten kann.
- Das Modell läuft neben Nvidia-GPUs auch auf chinesischen Chips von Huawei und anderen, ein Vorteil aus chinesischer Perspektive angesichts der US-Exportbeschränkungen.
- Der Wettbewerb unter chinesischen KI-Laboren verschärft sich: Während Moonshot AI mit Kimi K2.5 auf parallel arbeitende Agenten-Schwärme setzt, fällt Deepseek-V3.2 in mehreren Benchmarks hinter GLM-5 und Kimi K2.5 zurück.
Mit GLM-5 stellt das chinesische KI-Unternehmen Zhipu AI ein Open-Source-Modell vor, das bei Coding und agentenbasierten Aufgaben mit Claude Opus 4.5 und GPT-5.2 mithalten soll.
GLM-5 kommt auf 744 Milliarden Parameter, von denen 40 Milliarden gleichzeitig aktiv sind. Die Mixture-of-Experts-Architektur ist damit fast doppelt so groß wie beim Vorgänger GLM-4.5 mit seinen 355 Milliarden Parametern. Auch die Trainingsmenge wuchs deutlich von 23 auf 28,5 Billionen Token. Das Modell integriert laut Z.ai Deepseek Sparse Attention (DSA), um die Deployment-Kosten zu senken, ohne die Leistung bei langen Kontexten einzubüßen.
Zhipu AI formuliert den eigenen Anspruch so: Foundation Models bewegen sich von "Chat" zu "Arbeit". GLM-5 soll statt "nur" zu chatten komplexe Systeme bauen und langfristig planen können. Ähnlich positionieren auch die großen westlichen KI-Labore ihre neuen KI-Modelle. Die Modellgewichte stehen unter der MIT-Lizenz, einer der freizügigsten Open-Source-Lizenzen überhaupt.
Simulierter Automatenbetrieb als Agenten-Prüfstein
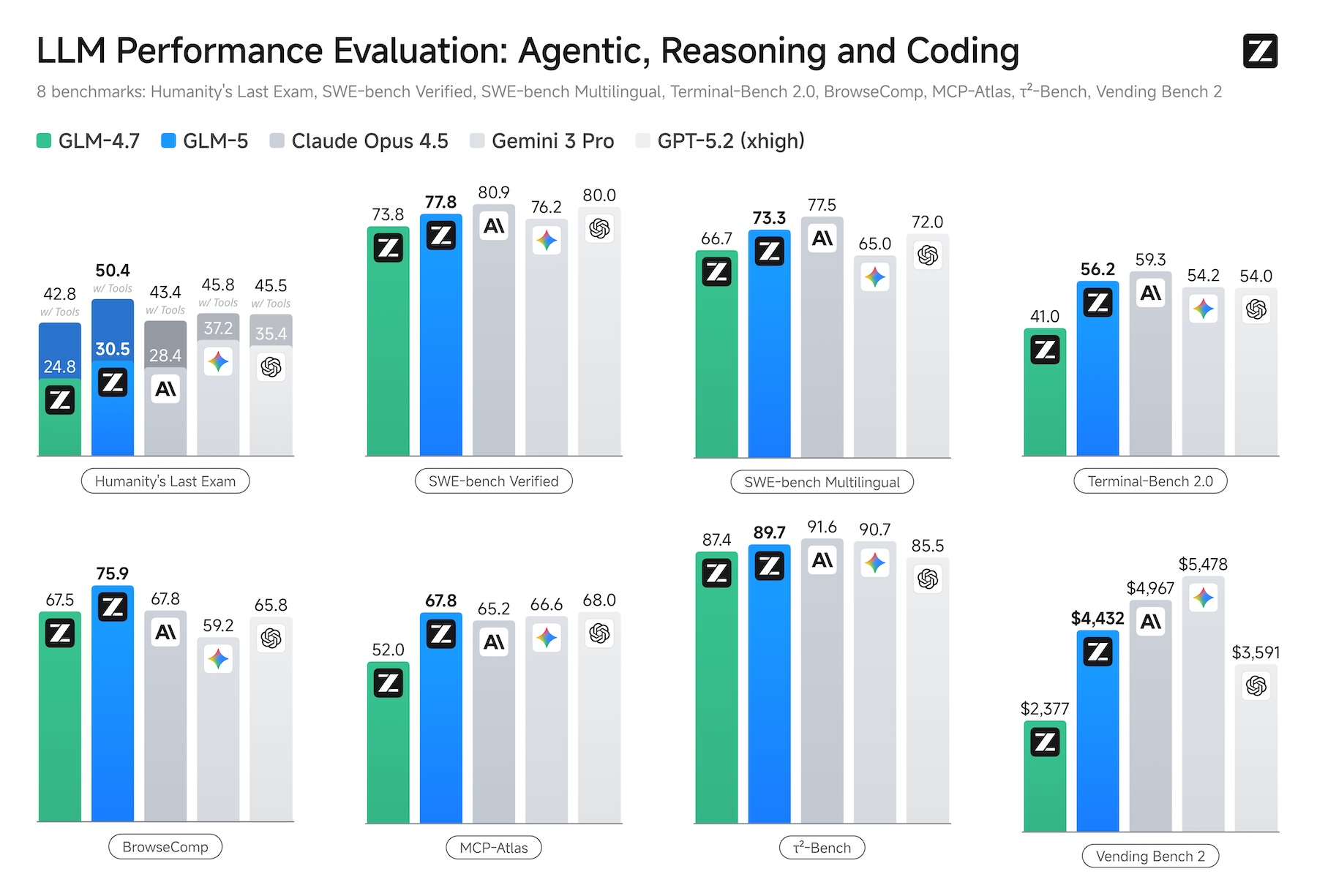
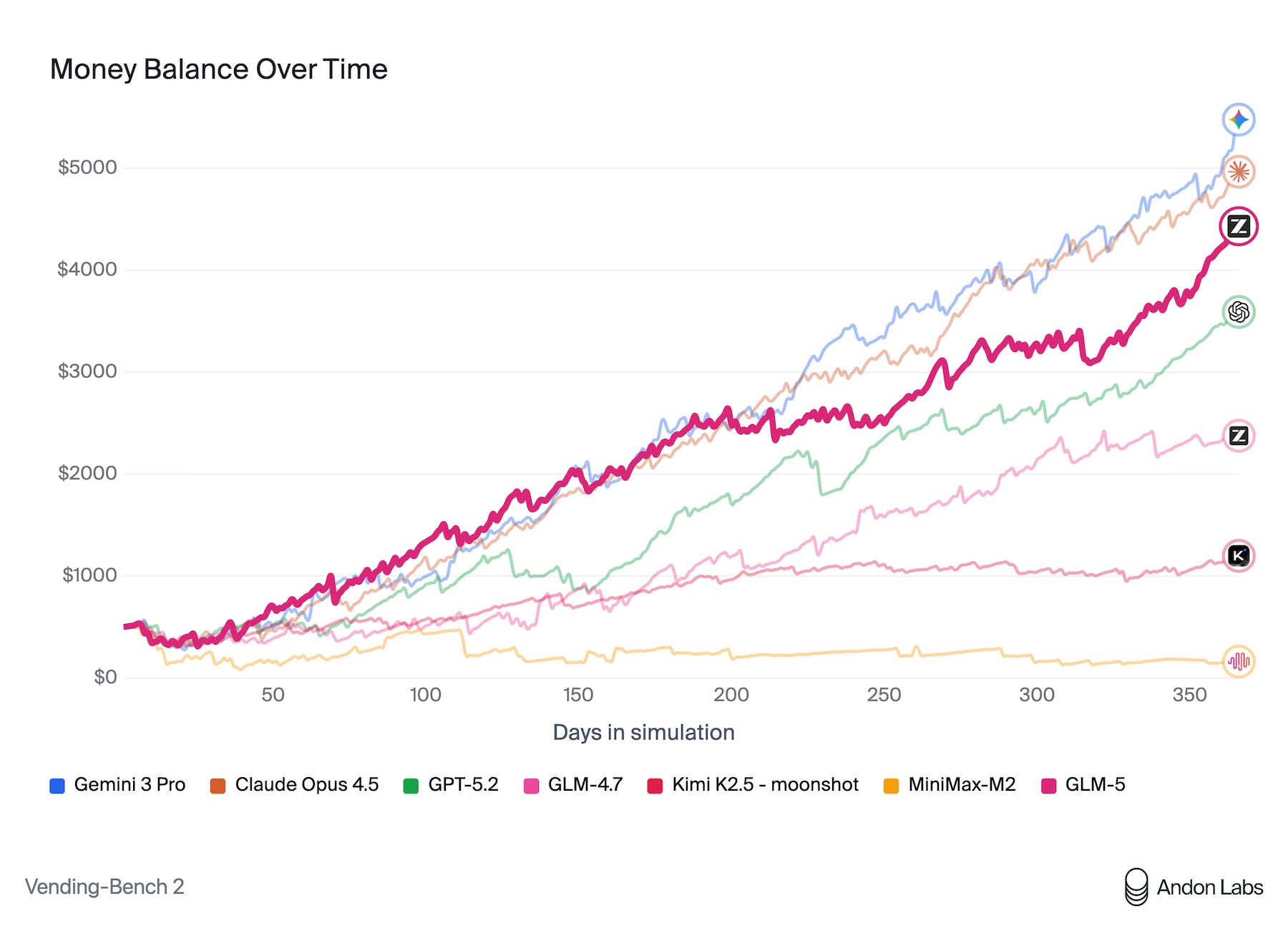
In den vom Hersteller veröffentlichten Benchmarks erzielt GLM-5 nach eigenen Angaben unter allen Open-Source-Modellen die besten Ergebnisse bei Reasoning, Coding und agentenbasierten Aufgaben. Besonders aufschlussreich ist der Vending Bench 2, bei dem ein Modell ein simuliertes Automatengeschäft über ein ganzes Jahr betreiben muss.
GLM-5 erwirtschaftet dort einen Kontostand von 4.432 Dollar und liegt damit nahe an Claude Opus 4.5 mit 4.967 Dollar. Durchgeführt wurde der Benchmark von Andon Labs, die auch an Anthropics realem Kiosk-Experiment "Project Vend" beteiligt waren, bei dem Claude Sonnet 3.7 einen echten Selbstbedienungsladen führte und dabei wirtschaftlich scheiterte.
Beim SWE-bench Verified für Software-Engineering kommt GLM-5 auf 77,8 Prozent und übertrifft damit Deepseek-V3.2 und Kimi K2.5, liegt aber weiterhin knapp hinter Claude Opus 4.5 mit 80,9 Prozent. Bei BrowseComp, einem Test für agentenbasierte Websuche mit Kontextmanagement, übertrifft GLM-5 laut Zhipu AI alle getesteten proprietären Modelle. Unabhängige Evaluierungen stehen allerdings noch aus.
Laut einer Stanford-Analyse hinken chinesische KI-Modelle ihren US-Pendants im Schnitt sieben Monate hinterher. GLM-5 erscheint nun rund drei Monate nach den aktuellen Flaggschiffen von Anthropic, Google und OpenAI und unterschreitet diesen Durchschnitt damit deutlich.
Dokumente statt Dialoge
GLM-5 kann laut Zhipu AI Texte und andere Quellen direkt in fertige .docx-, .pdf- und .xlsx-Dateien umwandeln. Die offizielle Anwendung Z.ai bietet dafür einen Agent Mode mit integrierten Skills für Dokumentenerstellung, etwa für Sponsoring-Vorschläge oder Finanzberichte.
Daneben unterstützt GLM-5 OpenClaw, ein junges, kontroverses Framework für applikations- und geräteübergreifendes Arbeiten, sowie gängige Coding-Agenten wie Claude Code, OpenCode und Roo Code.
GLM-5 läuft auf Nvidia-GPUs und zudem auf Chips von Huawei Ascend, Moore Threads, Cambricon und weiteren chinesischen Herstellern. Durch Kernel-Optimierung und Modellquantisierung soll ein "angemessener Durchsatz" möglich sein.
Für den chinesischen Markt, wo US-Exportbeschränkungen den Zugang zu Nvidia-Hardware erschweren, ist das ein wesentlicher Punkt. Für lokales Deployment unterstützt GLM-5 die Inferenz-Frameworks vLLM und SGLang, Anleitungen stellt Z.ai im GitHub-Repository bereit.
Neben dem Modell selbst hat Zhipu AI das Reinforcement-Learning-Framework slime veröffentlicht, mit dem GLM-5 nachtrainiert wurde. Das Problem, das slime adressiert: Reinforcement Learning auf große Sprachmodelle anzuwenden, bleibt ineffizient. Slime setzt auf eine asynchrone Architektur und verbindet das Trainings-Framework Megatron mit der Inferenz-Engine SGLang. Das Framework unterstützt neben Zhipu-Modellen auch Qwen3, Deepseek V3 und Llama 3.
Wettlauf der chinesischen KI-Labore geht weiter
Erst vor Kurzem hatte das Unternehmen den direkten Vorgänger GLM-4.7 mit einer "Preserved Thinking"-Funktion vorgestellt, die Gedankengänge über lange Dialoge hinweg speichert. GLM-5 steigert den SWE-bench-Wert dieses Vorgängers von 73,8 auf 77,8 Prozent.
Gleichzeitig hat der chinesische Konkurrent Moonshot AI mit Kimi K2.5 ein Modell veröffentlicht, das mit "Agent Swarms" bis zu 100 parallel arbeitende Sub-Agenten koordiniert und bei agentenbasierten Benchmarks ebenfalls Spitzenwerte erreicht. Beide Modelle nutzen eine Mixture-of-Experts-Architektur und zielen auf denselben Markt: autonome, langfristig planende KI-Agenten.
In den aktuellen Benchmarks von GLM-5 und Kimi K2.5 fällt auf, dass Deepseek zunehmend ins Hintertreffen gerät: Deepseek-V3.2 landet bei mehreren Agenten- und Coding-Tests deutlich hinter beiden Modellen. Laut einem Bericht der South China Morning Post verzögert sich das nächste große Deepseek-Modell mit einer Billion Parametern wegen der wachsenden Modellgröße.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnieren