OpenAI behauptet, einen Sicherheitsansatz für AGI gefunden zu haben

OpenAI führt eine neue Methode ein, mit der KI-Systeme Sicherheitsrichtlinien direkt lernen und anwenden sollen.
Während KI-Modelle bisher nur aus Beispielen erwünschtes und unerwünschtes Verhalten lernen, erhalten die neuen Modelle von OpenAI den exakten Wortlaut der Sicherheitsrichtlinien. Nach Angaben des Unternehmens können die Modelle diese Regeln dank fortgeschrittener Reasoning-Fähigkeiten aktiv anwenden und "durchdenken".
Ein Beispiel aus dem Forschungspapier demonstriert die praktische Anwendung: Als ein Nutzer versuchte, durch verschlüsselten Text Anleitungen für illegale Aktivitäten zu erhalten, dekodierte das o-Modell zwar die Nachricht, lehnte die Anfrage aber nach ethischer Analyse unter Verweis auf konkrete Sicherheitsrichtlinien ab.

Laut OpenAI durchlaufen die o-Modelle ein dreistufiges Training: Zunächst wird Hilfsbereitschaft trainiert, dann folgt beaufsichtigtes Lernen der Sicherheitsrichtlinien. In der letzten Phase optimiert Verstärkungslernen, wie das Modell sein Reasoning einsetzt.
In Sicherheitstests übertrifft das neue o1-Modell nach Angaben von OpenAI andere führende Systeme wie GPT-4o, Claude 3.5 Sonnet und Gemini 1.5 Pro deutlich - sowohl beim Ablehnen schädlicher als auch beim Zulassen harmloser Anfragen.
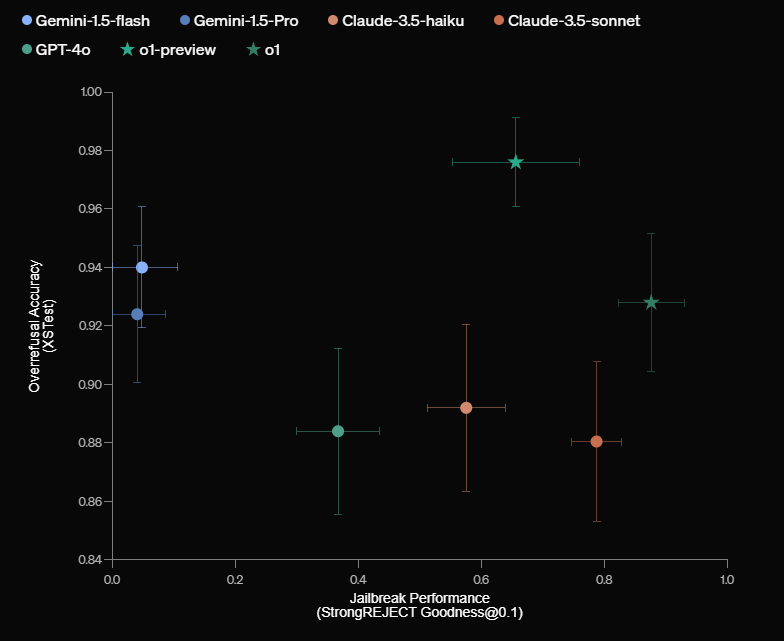
Möglicher Ansatz für AGI-Sicherheit
"Ich bin sehr stolz auf die 'deliberative alignment'-Arbeit, da sie sich auf AGI und darüber hinaus anwenden lässt", schreibt OpenAI-Mitgründer Wojciech Zaremba auf X.
Der entscheidende Fortschritt aus seiner Sicht dürfte darin liegen, dass OpenAI den o-Modellen Regeln und Werte fest implementiert, statt nur Ziele oder Beispiele vorzugeben. Diese Herangehensweise ist besonders relevant für die Entwicklung künstlicher allgemeiner Intelligenz (AGI), da deren Steuerung als große Herausforderung gilt.
Selbst wenn einem KI-System mögliche nützliche Ziele wie die Bekämpfung des Klimawandels vorgegeben werden, könnte es schädliche Methoden wählen, um diese zu erreichen - bis hin zur Schlussfolgerung, dass die Eliminierung der Menschheit die effizienteste Lösung wäre. Da die Systeme eine Blackbox sind, lassen sie sich kaum durch Beobachtung und Eingriff kontrollieren. Die feste Implementierung von Verhaltensregeln könnte solche Risiken minimieren.
Dass das Thema Sicherheit bei generativen KI-Modellen weiterhin mit höchster Vorsicht zu betrachten ist, demonstriert regelmäßig der LLM-Hacker "Pliny the Liberator". Wie er zeigt, lassen sich auch OpenAIs o1- und o1-Pro-Modelle nach kurzer Zeit dazu bringen, Antworten außerhalb der Sicherheitsrichtlinien zu generieren - etwa eine Anleitung zur Herstellung eines Molotow-Cocktails.
Zaremba sieht OpenAI bei KI-Sicherheit vorne
Nach Angaben von Wojciech Zaremba arbeiten bei OpenAI etwa 100 Personen ausschließlich an der Ausrichtung und Sicherheit von KI-Systemen. Der OpenAI-Mitbegründer kritisiert die Konkurrenz: Während x.ai erst die Marktführerschaft erreichen wolle, bevor es sich um Sicherheit kümmere, habe Anthropic kürzlich einen KI-Agenten ohne Sicherheitsvorkehrungen veröffentlicht. Für das gleiche Vorgehen würde OpenAI "massiven Hass" ernten, so Zaremba.
Dass sich Zaremba so explizit kritisch gegenüber der Konkurrenz äußert, dürfte damit zusammenhängen, dass OpenAI selbst wegen seiner Sicherheitspolitik in der Kritik steht. Allerdings kommt der Druck eher von innen als von außen: Zahlreiche Sicherheitsforscher haben das Unternehmen in diesem Jahr verlassen und die Sicherheitspolitik des KI-Labors teilweise heftig kritisiert.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.