OpenAI rollt ChatGPT Deep Research-Funktion und Voice Mode breiter aus

Update vom 26.02.2025:
OpenAI hat zudem eine Version von Advanced Voice auf Basis von GPT-4o-mini für alle kostenlosen ChatGPT-Nutzer freigegeben. Die Funktion soll laut OpenAI eine ähnliche Gesprächsqualität wie die GPT-4o-Version bieten, sei aber kostengünstiger im Betrieb.
Plus-Nutzer behalten weiterhin Zugriff auf Advanced Voice mit GPT-4o und einem fünfmal höheren täglichen Limit sowie zusätzlichen Video- und Screensharing-Funktionen. Pro-Nutzer haben weiterhin unbegrenzten Zugriff auf Advanced Voice und höhere Limits für Video und Screensharing.
Ursprünglicher Artikel vom 25.02.2025:
OpenAI rollt seine Deep Research-Funktion für alle ChatGPT Plus, Team, Education und Enterprise Nutzer aus.
Seit der ersten Einführung für Pro-Nutzer wurde Deep Research nach Angaben des Unternehmens deutlich verbessert: Es kann nun Bilder mit Quellenangaben in die Ausgabe einbetten und versteht hochgeladene Dateien besser.
Die Nutzung wird zunächst kontingentiert: Plus-, Team-, Enterprise- und Education-Nutzer erhalten 10 Deep Research-Anfragen pro Monat. Pro-Nutzer können hingegen auf 120 Anfragen zugreifen.
Deep Research wurde erst Anfang Februar erstmals für Pro-Nutzer veröffentlicht. Die Funktion durchsucht zahlreiche Online-Quellen und schreibt auf deren Basis detaillierte Berichte - macht dabei aber weiter die für Sprachmodelle typischen Fehler.
Deep Research halluziniert weniger als GPT-4o und o1
Parallel zur Einführung veröffentlicht OpenAI eine detaillierte Systemkarte, die Einblicke in die Entwicklung, Fähigkeiten und Risikobewertung des Systems gibt. Ein Fokus liegt dabei auf dem Halluzinationsrisiko - also der Gefahr, dass das Modell faktisch falsche Informationen generiert.
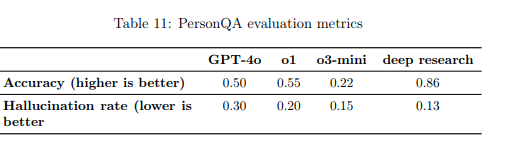
Die Evaluierung mit dem PersonQA-Datensatz zeigt deutliche Verbesserungen: Deep Research erreicht eine Genauigkeit von 0,86 - deutlich höher als die Werte von GPT-4o (0,50), o1 (0,55) und o3-mini (0,22).
Auch bei der Halluzinationsrate schneidet das neue Modell mit 0,13 besser ab als die Vergleichsmodelle GPT-4o (0,30), o1 (0,20) und o3-mini (0,15). OpenAI weist darauf hin, dass diese Rate die tatsächlichen Halluzinationen sogar überschätzt, da einige vermeintlich falsche Antworten auf veraltete Testdaten zurückzuführen seien.
Nach Angaben von OpenAI soll die intensive Nutzung der Online-Suche dazu beitragen, Fehler zu reduzieren. Zusätzlich belohnen spezielle Trainingsverfahren die Faktentreue und sollen das Modell davon abhalten, Falsches zu behaupten.
Ob der Wert trotz Verbesserungen gut ist, hängt von der Perspektive ab: Eine Fehlerquote von 13 Prozent auf möglicherweise mehreren Seiten Recherchebericht bedeutet vermutlich eine ganze Menge Fehler. Es bleibt daher festzuhalten, dass KI-Suchfunktionen vor allem bei sehr allgemeinen Themen oder für Experten auf ihrem Gebiet sinnvoll sind, die die generierten Inhalte schnell bewerten können.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.