OpenAI startet KI-Modelle GPT-5.4 Thinking und Pro: Coding, Reasoning und Computer Use in einem Modell

Kurz & Knapp
- OpenAI hat GPT-5.4 vorgestellt, das erstmals Coding, Reasoning, agentische Workflows und native Computerbedienung in einem einzigen Modell vereint.
- Auf dem GDPval-Benchmark für professionelle Wissensarbeit erreicht es 83,0 Prozent gegenüber 70,9 Prozent beim Vorgänger GPT-5.2.
- Eine der technisch bedeutsamsten Neuerungen ist "Tool Search" in der API: Statt alle Tool-Definitionen vollständig in den Prompt zu laden, ruft GPT-5.4 nur bei Bedarf die vollständigen Definitionen ab, was den Token-Verbrauch in Tests um 47 Prozent reduzierte. Die Token-Preise steigen jedoch.
OpenAI stellt mit GPT-5.4 sein bislang leistungsfähigstes Modell vor. Es vereint erstmals Coding, Computerbedienung und Reasoning in einem einzigen Modell.
OpenAI hat GPT-5.4 veröffentlicht, das in ChatGPT als GPT-5.4 Thinking, in der API und in Codex verfügbar ist. Parallel dazu erscheint GPT-5.4 Pro, eine leistungsstärkere Variante für besonders komplexe Aufgaben. Laut OpenAI handelt es sich um das "leistungsfähigste und effizienteste Frontier-Modell" des Unternehmens für professionelle Arbeit.
Das Modell vereint erstmals die Coding-Fähigkeiten des kürzlich erschienenen GPT-5.3-Codex mit verbessertem Reasoning, agentischen Workflows und nativer Computerbedienung (Computer Use). OpenAI bezeichnet GPT-5.4 als erstes "Mainline-Reasoning-Modell", das die Frontier-Coding-Fähigkeiten von GPT-5.3-Codex integriert. Ein 5.3er-Thinking-Modell gab es nicht, nur die Codex-Variante. Die Nummerierung soll diesen Sprung widerspiegeln und die Modellauswahl in Codex vereinfachen.
Künftig sollen sich Instant- und Thinking-Modelle laut OpenAI unterschiedlich schnell weiterentwickeln. OpenAI hatte erst am Dienstag das Modell 5.3 Instant vorgestellt, das derzeit das Standard-Chat-Modell in ChatGPT ist.
Professionelle Wissensarbeit als Verkaufsargument
OpenAI positioniert GPT-5.4 klar als Werkzeug für Büroarbeit. Auf dem hauseigenen GDPval-Benchmark, der Agenten in 44 Berufen aus den neun Branchen mit dem größten Beitrag zum US-BIP testet, erreicht GPT-5.4 eine Quote von 83,0 Prozent, bei der es Branchenprofis erreicht oder übertrifft (GPT-5.2: 70,9 Prozent). Kurioserweise übertrifft das Standard-5.4-Thinking-Modell hier die Pro-Version.
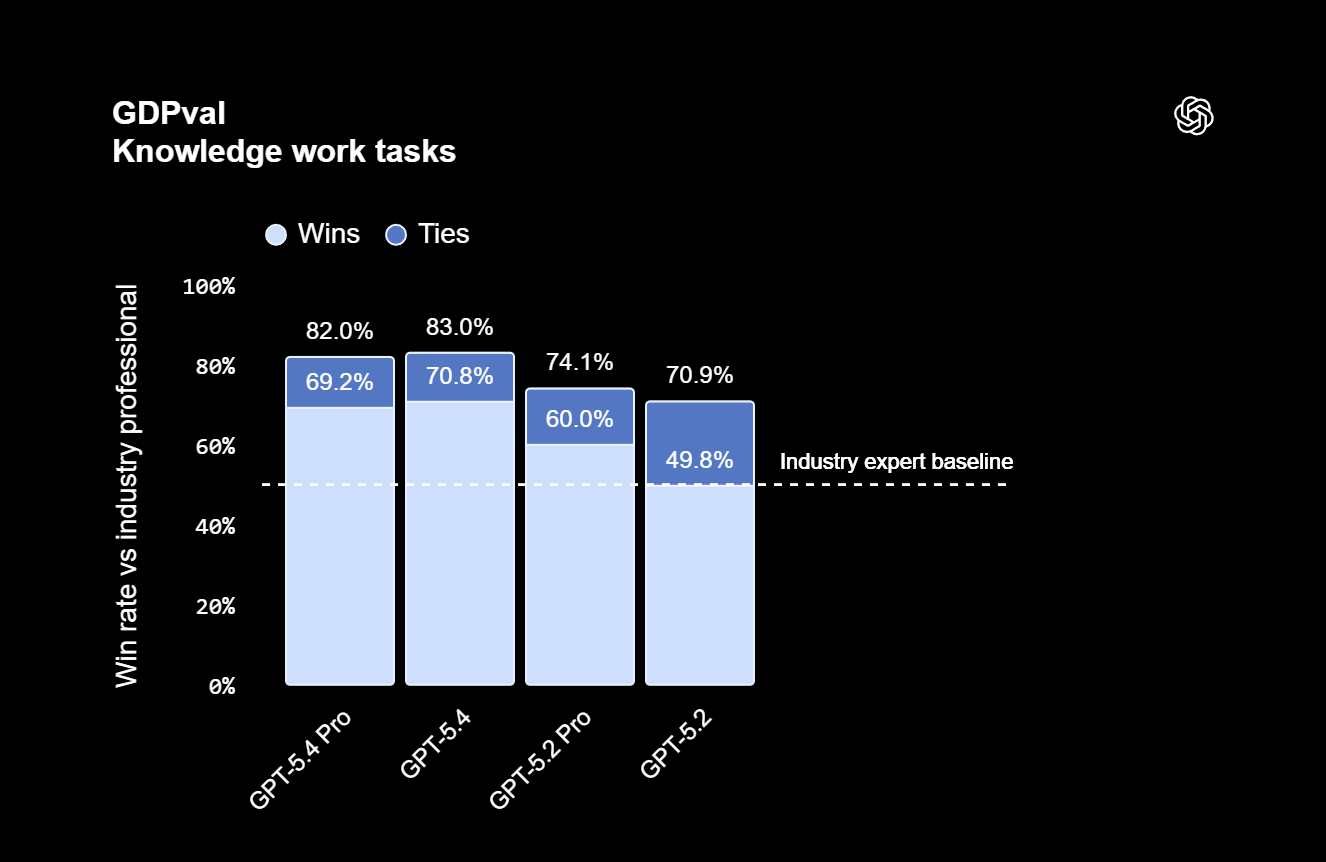
Besonders bei Tabellenkalkulationen zeigt sich laut OpenAI der Sprung: Bei Investment-Banking-Modellierungsaufgaben erzielt GPT-5.4 nach Unternehmensangaben 87,3 Prozent gegenüber 68,4 Prozent beim Vorgänger. Bei Präsentationen bevorzugten menschliche Bewerter die Ergebnisse von GPT-5.4 in 68 Prozent der Fälle wegen besserer Ästhetik und visueller Vielfalt. Passend dazu hat OpenAI ein neues ChatGPT-Add-in für Excel lanciert, das sich an Enterprise-Kunden richtet.
Auch in akademischen Tests legt GPT-5.4 durchweg zu – besonders auffällig beim abstrakten Reasoning: Auf ARC-AGI-2 erreicht GPT-5.4 Pro 83,3 Prozent, GPT-5.2 Pro lag bei 54,2 Prozent.
| Eval | GPT‑5.4 | GPT‑5.4 Pro | GPT‑5.3-Codex | GPT‑5.2 | GPT‑5.2 Pro |
|---|---|---|---|---|---|
| Frontier Science Research | 33.0% | 36.7% | — | 25.2% | — |
| FrontierMath Tier 1–3 | 47.6% | 50.0% | — | 40.7% | — |
| FrontierMath Tier 4 | 27.1% | 38.0% | — | 18.8% | 31.3% |
| GPQA Diamond | 92.8% | 94.4% | 92.6% | 92.4% | 93.2% |
| Humanity's Last Exam (no tools) | 39.8% | 42.7% | — | 34.5% | 36.6% |
| Humanity's Last Exam (with tools) | 52.1% | 58.7% | — | 45.5% | 50.0% |
| ARC-AGI-1 (Verified) | 93.7% | 94.5% | — | 86.2% | 90.5% |
| ARC-AGI-2 (Verified) | 73.3% | 83.3% | — | 52.9% | 54.2% (high) |
OpenAI gibt zudem an, die Halluzinationsrate weiter gesenkt zu haben: Einzelne Behauptungen seien 33 Prozent seltener falsch, vollständige Antworten 18 Prozent seltener fehlerhaft als bei GPT-5.2.
"Wir sehen keine Wand, und erwarten, dass sich KI-Fähigkeiten dieses Jahr weiter dramatisch steigern werden", schreibt OpenAI-Forscher Noam Brown, einer der Köpfe hinter OpenAIs Reasoning-Modell-Durchbruch.
Erstes allgemeines Reasoning-Modell mit nativer Computerbedienung
GPT-5.4 ist laut OpenAI das erste allgemeine Modell des Unternehmens, das nativ Computer bedienen kann. Agenten können über Screenshots, Maus- und Tastatureingaben Websites und Software-Systeme steuern, um komplexe Aufgaben zu erledigen. Bislang gab es diese Funktion in ChatGPT nur über den sogenannten Agenten-Modus, allerdings funktionierte sie unzuverlässig und wurde fast nicht genutzt.
Das soll sich jetzt ändern: Auf dem OSWorld-Verified-Benchmark, der die Navigation in Desktop-Umgebungen misst, erreicht GPT-5.4 eine Erfolgsrate von 75,0 Prozent. GPT-5.2 lag bei 47,3 Prozent, die menschliche Vergleichsgruppe bei 72,4 Prozent – damit übertrifft das Modell erstmals menschliche Leistung in diesem Test.
Die visuelle Wahrnehmung wurde ebenfalls verbessert. OpenAI führt einen neuen Original-Bilddetail-Modus ein, der Bilder mit bis zu 10,24 Millionen Pixeln in voller Auflösung verarbeiten kann. Auf dem Dokumentenparsing-Benchmark OmniDocBench sinkt die durchschnittliche Fehlerrate von 0,140 auf 0,109.
Coding: Marginal besser, aber schneller
Beim Coding erreicht GPT-5.4 auf dem SWE-Bench Pro 57,7 Prozent und liegt damit knapp über GPT-5.3-Codex (56,8 Prozent) und GPT-5.2 (55,6 Prozent). Der eigentliche Vorteil liegt laut OpenAI in der Geschwindigkeit: Ein neuer "/fast"-Modus in Codex soll die Token-Geschwindigkeit um das 1,5-Fache steigern, ohne die Modellqualität zu verändern.
Ebenso wurde die agentische Websuche verbessert. Auf dem BrowseComp-Benchmark, der misst, wie gut KI-Agenten schwer auffindbare Informationen im Web finden, erreicht GPT-5.4 82,7 Prozent, GPT-5.4 Pro sogar 89,3 Prozent (GPT-5.2: 65,8 Prozent).
GPT-5.4 |
GPT-5.3-Codex | GPT-5.2 | |
| GDPval (wins or ties) | 83.0% | 70.9% | 70.9% |
| SWE-Bench Pro (Public) | 57.7% | 56.8% | 55.6% |
| OSWorld-Verified | 75.0% | 74.0%* | 47.3% |
| Toolathlon | 54.6% | 51.9% | 46.3% |
| BrowseComp | 82.7% | 77.3% | 65.8% |
Als Demonstration der kombinierten Coding- und Computer-Use-Fähigkeiten veröffentlicht OpenAI einen experimentellen Codex-Skill namens "Playwright (Interactive)", mit dem Codex Web- und Electron-Apps visuell debuggen kann. In einer Demo erzeugte GPT-5.4 aus einem einzigen Prompt ein isometrisches Freizeitpark-Simulationsspiel mit Pfadplatzierung, Gäste-Pathfinding und Warteschlangen.
Tool Search in der API soll Token-Verbrauch drastisch senken
Eine der technisch interessantesten Neuerungen ist "Tool Search" in der API. Bisher wurden alle Tool-Definitionen vollständig in den Prompt geladen, was bei großen Tool-Ökosystemen Tausende zusätzlicher Tokens verbrauchte. GPT-5.4 erhält stattdessen nur eine leichtgewichtige Liste verfügbarer Tools und ruft deren vollständige Definitionen erst bei Bedarf ab.
Laut OpenAI reduzierte dieser Ansatz den Token-Verbrauch in einem Test mit 250 Aufgaben aus dem MCP-Atlas-Benchmark um 47 Prozent bei gleichbleibender Genauigkeit. Für MCP-Server mit Zehntausenden Tokens an Tool-Definitionen sollen die Einsparungen erheblich sein.
Auch der Reasoning-Prozess soll effizienter werden: In ChatGPT zeigt GPT-5.4 Thinking bei komplexen Anfragen eine Vorschau seines geplanten Vorgehens. Nutzer können daraufhin Anweisungen hinzufügen oder die Richtung ändern, bevor das Modell seine Antwort abschließt. Das soll die Zahl der nötigen Nachfragen reduzieren. Die Funktion ist auf chatgpt.com und Android verfügbar, iOS soll folgen.
Zudem unterstützt GPT-5.4 in Codex experimentell ein Kontextfenster von bis zu einer Million Tokens, was besonders für langfristige Planungs- und Ausführungsaufgaben relevant sein dürfte.
Preise steigen, Token-Effizienz soll kompensieren
GPT-5.4 ist teurer als sein Vorgänger. OpenAI argumentiert, dass das Modell als "token-effizientestes Reasoning-Modell" deutlich weniger Tokens für dieselben Aufgaben benötige, was die höheren Tokenpreise relativieren soll.
| API model | Input price | Cached input price | Output price |
|---|---|---|---|
| gpt-5.2 | $1.75 / M tokens | $0.175 / M tokens | $14 / M tokens |
| gpt-5.4 | $2.50 / M tokens | $0.25 / M tokens | $15 / M tokens |
| gpt-5.2-pro | $21 / M tokens | - | $168 / M tokens |
| gpt-5.4-pro | $30 / M tokens | - | $180 / M tokens |
In ChatGPT ist GPT-5.4 Thinking ab sofort für Plus-, Team- und Pro-Nutzer verfügbar und ersetzt GPT-5.2 Thinking. Das Vorgängermodell bleibt noch drei Monate unter "Legacy Models" zugänglich und wird am 5. Juni 2026 eingestellt. Enterprise- und Edu-Nutzer können den Zugang über Admin-Einstellungen aktivieren. GPT-5.4 Pro steht Pro- und Enterprise-Plänen zur Verfügung.
Höhere Einstufung bei der Cybersicherheit
Im Bereich der Sicherheit hat sich laut Model Card vor allem die Cybersicherheits-Einstufung als zentrale Neuerung herauskristallisiert. Das Modell wird – wie zuvor bereits das spezialisierte Coding-Modell GPT-5.3 Codex – als "High Capability" im Bereich Cybersicherheit eingestuft. GPT-5.4 Thinking ist damit jedoch das erste allgemeine Reasoning-Modell mit dieser Klassifikation, was die Reichweite und potenzielle Angriffsfläche deutlich vergrößert.
Die Stufe "Hoch" bedeutet laut OpenAIs Preparedness-Framework, dass ein Modell bestehende Hürden für Cyberangriffe beseitigen kann – etwa durch die Automatisierung von End-to-End-Angriffen auf geschützte Ziele oder das automatische Auffinden und Ausnutzen operativ relevanter Sicherheitslücken. Darüber liegt nur noch die Stufe "Critical", in der ein Modell ohne menschliches Zutun Zero-Day-Exploits in gehärteten Systemen finden und eigenständig neuartige Angriffsstrategien entwickeln könnte.
OpenAI hat für 5.4 ein neues Schutzkonzept implementiert: Statt verdächtige Nutzer auf ein schwächeres Modell herunterzustufen, kommen nun Echtzeit-Blocker auf Nachrichtenebene zum Einsatz, ergänzt durch ein zweistufiges Überwachungssystem aus thematischem Klassifikator und KI-gestütztem Sicherheitsanalysten. Bei den klassischen Sicherheitsbenchmarks schneidet das Modell weitgehend auf dem Niveau von GPT-5.2 Thinking ab, die Jailbreak-Resistenz hat sich gegenüber GPT-5.1 Thinking deutlich verbessert.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnieren