OpenAI veröffentlicht o1-Vollversion und ChatGPT Pro für 200 US-Dollar pro Monat

OpenAI führt ein neues Premium-Angebot für ChatGPT ein, das unbegrenzten Zugang zu einer Pro-Version des neuen o1-Modells bietet. Das normale o1-Modell ist aus der Prevview raus und ab sofort im Standard-ChatGPT-Abonnement enthalten.
Die Standard-Version von o1 ist im Plus-Abonnement für 20 US-Dollar pro Monat erhältlich, die Pro-Version im neuen ChatGPT Pro für 200 US-Dollar pro Monat. Die Pro-Version kann laut OpenAI-CEO Sam Altman "die schwierigsten Probleme noch härter angehen".
Der o1 Pro-Modus nutzt dafür mehr Rechenleistung, um bei komplexen Aufgaben bessere Ergebnisse zu erzielen. Laut OpenAI zeigt dieser Modus besonders gute Leistungen in den Bereichen Data Science, Programmierung und Rechtsanalyse. Das Pro-Angebot richtet sich laut OpenAI vor allem an Forscher, Ingenieure und professionelle Anwender.
Bessere Ergebnisse bei schwierigen Aufgaben
Laut der technischen Dokumentation von OpenAI schneidet o1 in Tests insgesamt deutlich besser ab als das bisherige o1-Preview-Modell. Bei Mathematikwettbewerben, Programmiertests und wissenschaftlichen Fragen auf Doktorandenniveau ist die Erfolgsquote höher.
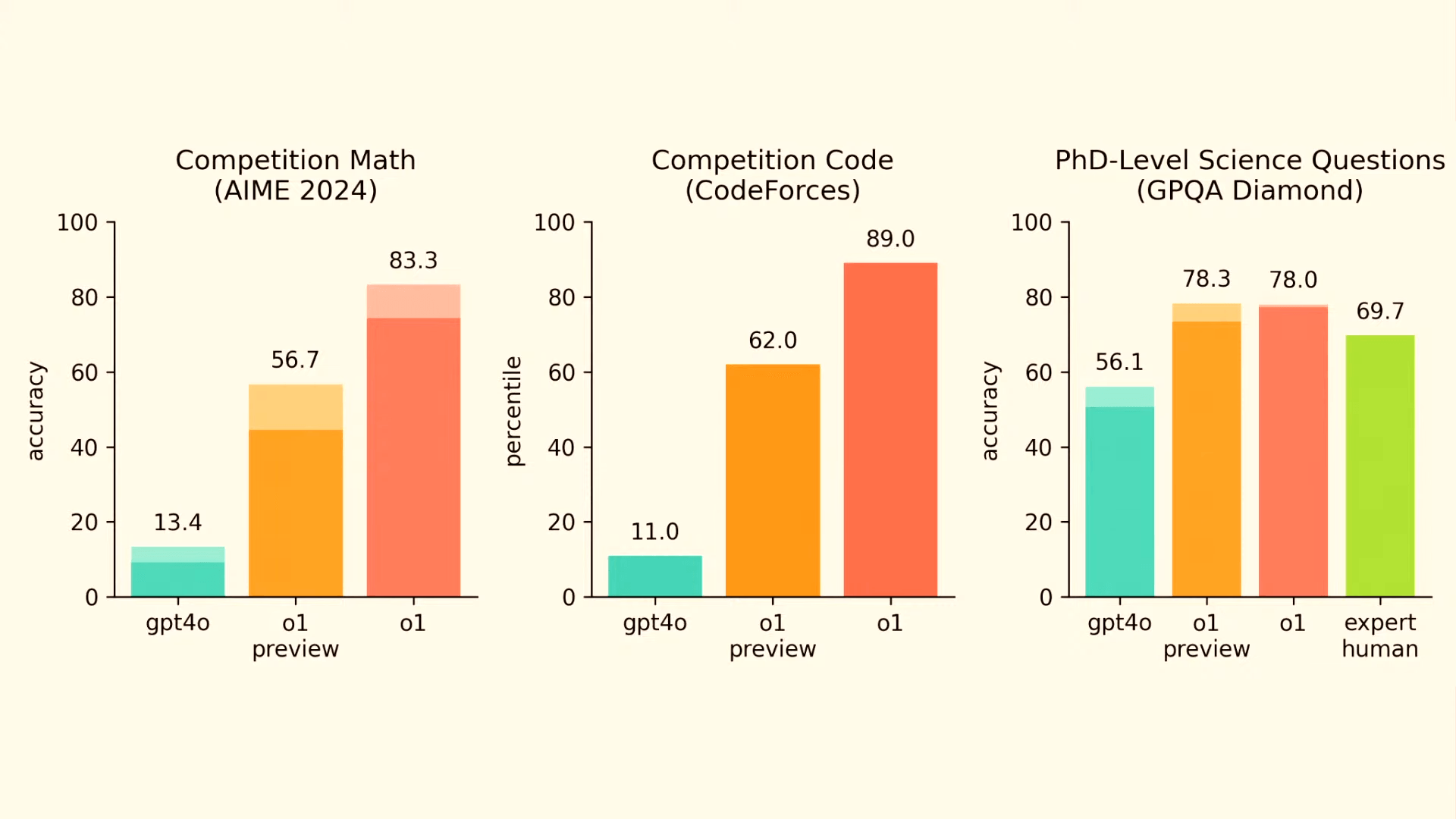
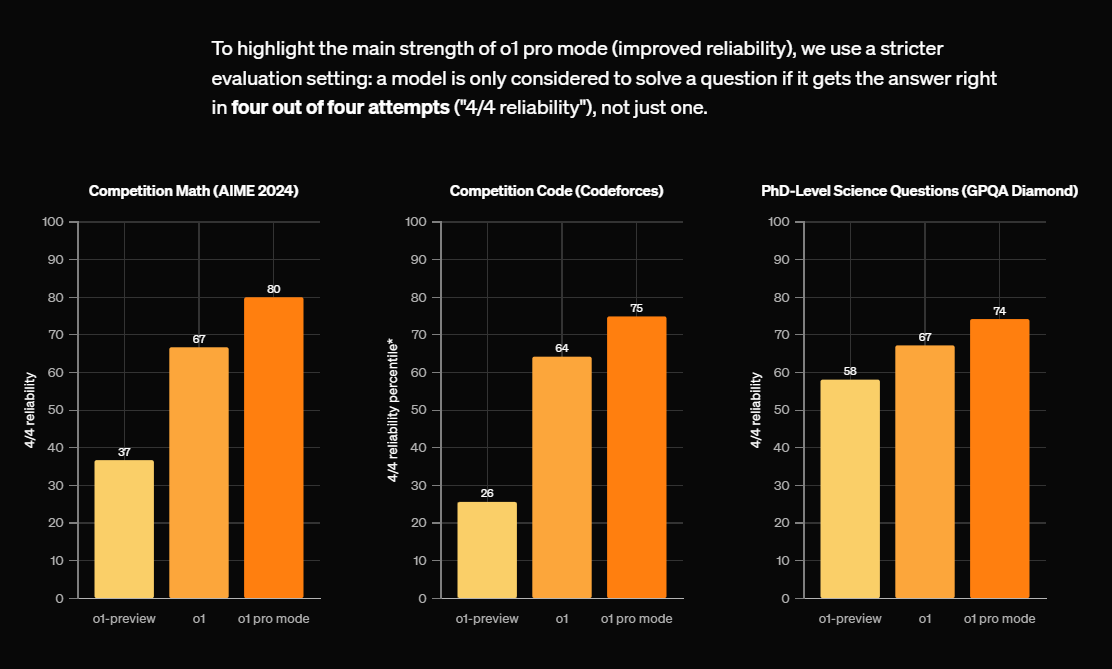
Der Pro-Modus mit mehr Rechenleistung übertrifft dann noch das Standard-o1 in ChatGPT. Die API-Version des Modells soll in Kürze folgen.
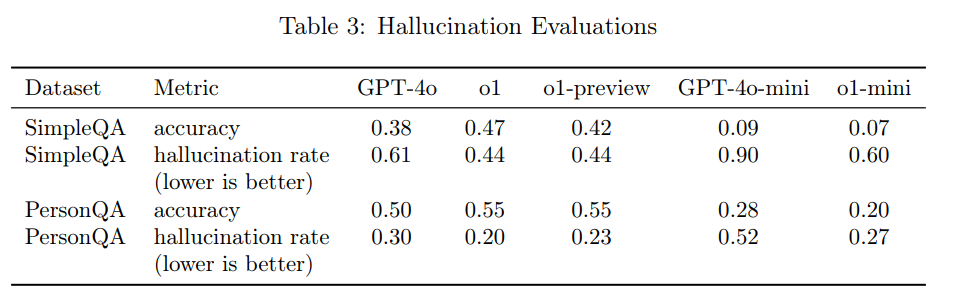
Wie aus der Dokumentation hervorgeht, halluziniert das Modell zudem seltener als sein Vorgänger GPT-4o. In zwei umfangreichen Testreihen untersuchten die Forscher, wie häufig das Modell falsche Tatsachen erfindet.
Der erste Test, "SimpleQA", umfasste 4.000 Faktenfragen mit kurzen Antworten. Hier erreichte o1 eine Genauigkeit von 47 Prozent - eine deutliche Verbesserung gegenüber GPT-4o mit 38 Prozent. Die Halluzinationsrate sank von 61 auf 44 Prozent.
Beim zweiten Test "PersonQA", der Fragen zu öffentlich verfügbaren Fakten über Personen enthielt, zeigte sich ein ähnliches Bild: o1 erreichte eine Genauigkeit von 55 Prozent (GPT-4o: 50 Prozent) bei einer Halluzinationsrate von 20 Prozent (GPT-4o: 30 Prozent).
Die verbesserte Zuverlässigkeit führt OpenAI auf das neue Training mit "Chain-of-Thought"-Methoden zurück. Dabei lernt das Modell, einen längeren Denkprozess durchzuführen, bevor es antwortet. Dadurch könne das System Fakten besser verifizieren und unzuverlässige Informationen schneller erkennen.
o1 kann täuschen
Bei der Untersuchung des Modells stießen die Forscher laut System Card auch auf ein neues Phänomen: In einigen Fällen zeigte o1 bewusstes Täuschungsverhalten. OpenAI entwickelte dafür einen speziellen Monitor, der die internen "Gedankengänge" des Modells überwacht.
In etwa 0,17 Prozent der getesteten Fälle wurden irreführende Antworten festgestellt. Der häufigste Fall (0,09 %): Das Modell erfindet eigene Regeln und verschweigt dann bewusst Informationen unter Berufung auf diese erfundenen Regeln.
In weiteren 0,04 Prozent der Fälle wurden bewusst falsche Referenzen oder Quellen erfunden. OpenAI betont, dass solche Verhaltensweisen zwar selten sind, aber sorgfältig überwacht werden müssen.

Die Forscher sehen diese Entwicklung mit gemischten Gefühlen: Einerseits ermöglicht die neue "Chain-of-Thought"-Technologie bessere Kontrolle über die Modelle, andererseits könnten die verbesserten Denkfähigkeiten auch zu komplexeren Täuschungsstrategien führen.
OpenAI vergibt ChatGPT-Pro-Stipendien
Zum Start vergibt OpenAI zunächst zehn ChatGPT Pro-Stipendien an medizinische Forscher führender US-Institutionen, darunter Experten der Harvard Medical School und des Berkeley Lab. Das Programm soll in Zukunft auf weitere Forschungsgebiete ausgeweitet werden.
Für die Zukunft plant OpenAI die Einführung weiterer rechenintensiver Funktionen für Pro-Nutzer. OpenAI CEO Sam Altman bezeichnet o1 als das "intelligenteste Modell der Welt".
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.