OpenAI veröffentlicht o3-mini für kostenloses ChatGPT und API
OpenAI veröffentlicht sein neuestes Reasoning-Modell o3-mini, das besonders bei naturwissenschaftlichen Aufgaben überzeugen soll und auch ChatGPT-Nutzern der freien Version zur Verfügung steht.
Das Modell zeichnet sich laut OpenAI besonders durch seine Stärken in den STEM-Bereichen (Wissenschaft, Mathematik und Programmierung) aus und bietet dabei die gleichen niedrigen Kosten und geringe Latenz wie sein Vorgänger o1-mini.
Eine Besonderheit von o3-mini ist die Möglichkeit, zwischen drei verschiedenen "Reasoning-Effort"-Optionen zu wählen: niedrig, mittel und hoch. Damit können Entwickler laut OpenAI über die API je nach Anwendungsfall zwischen Geschwindigkeit und Genauigkeit optimieren. Die höchste Stufe eignet sich laut OpenAI besonders für Programmierung und logische Aufgaben, während die niedrigste Stufe "schnelles fortgeschrittenes Denken" ermöglicht.
Die Trainingsdaten für o3-mini stammen laut OpenAI aus einer Vielzahl von Quellen, sowohl öffentlich zugänglichen als auch intern entwickelten. Wahrscheinlich hat OpenAI ähnlich wie bei traditionellen LLMs auf Web- und Buchdaten trainiert und zusätzlich synthetische Trainingsdaten speziell für STEM-Aufgaben generiert, die für das bei der o-Serie verwendete Reinforcement Learning eindeutig als richtig oder falsch klassifiziert werden können. Schreib-, Text- und kreative Aufgaben profitieren bisher nicht von dieser Trainingsmethode, weshalb OpenAI die o-Serie primär für Logikaufgaben und Analysen empfiehlt.
Mehr Leistung und Tempo als die Vorgänger
In Tests zeigt sich o3-mini seinem Vorgänger laut OpenAI deutlich überlegen: Externe Experten bevorzugten die Antworten von o3-mini in 56 Prozent der Fälle gegenüber o1-mini und stellten eine Reduzierung schwerer Fehler um 39 Prozent bei komplexen Fragen fest. Auch die multilinguale Leistung soll deutlich verbessert sein. Das Modell kann laut OpenAI komplexe Software-Engineering-Aufgaben selbstständig lösen und erreicht bei Coding-Benchmarks wie SWE-bench Verified eine Erfolgsrate von bis zu 49,3 Prozent.
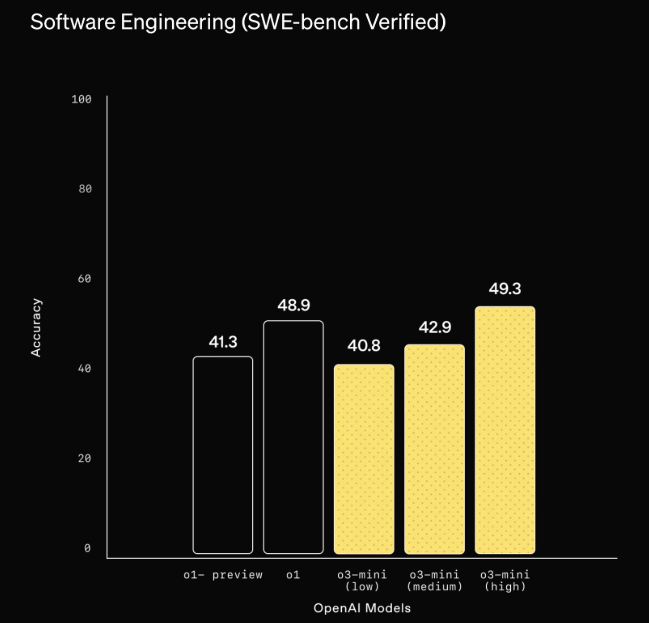
Abhängig von der "Denkintensität" und dem Benchmark übertrifft es die größeren Vorgängermodelle o1-preview und o1 teils deutlich bei Code-Aufgaben.
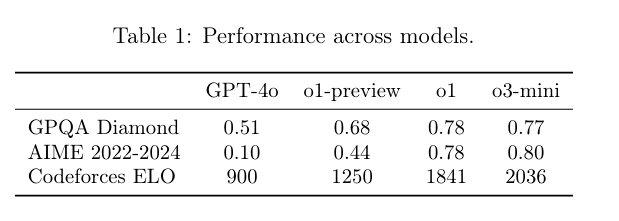
"Während OpenAI o1 unser allgemeines Modell für generelle Schlussfolgerungen bleibt, bietet OpenAI o3-mini eine spezialisierte Alternative für technische Bereiche, die Präzision und Geschwindigkeit erfordern", erklärt OpenAI den Unterschied.
Auch bei der Geschwindigkeit punktet das neue Modell: In A/B-Tests lieferte o3-mini seine Antworten im Durchschnitt in 7,7 Sekunden, während o1-mini 10,16 Sekunden benötigte - eine Verbesserung um 24 Prozent.
o3-mini ersetzt o1-mini in ChatGPT und die API wird günstiger
Kostenlose Nutzer von ChatGPT können o3-mini über die Option "Reason" im Chat-Fenster nutzen. Diese Funktion ist auch in Microsoft Copilot als "Think Deeper" integriert, nutzt hier allerdings o1. Für Plus- und Team-User verdreifacht OpenAI das Nachrichtenlimit von 50 auf 150 Nachrichten pro Tag. Pro-Nutzer können o3-mini ohne Einschränkung nutzen.
In der kostenlosen ChatGPT-Version ist o3-mini auf die mittlere Stufe eingestellt, um einen" ausgewogenen Kompromiss zwischen Geschwindigkeit und Genauigkeit" zu bieten. Nur zahlende ChatGPT-Nutzer können die höchste Stufe verwenden.
Zusätzlich integriert OpenAI eine Suchfunktion in o3-mini, die aktuelle Antworten mit Links zu relevanten Webquellen liefert. Die Firma bezeichnet dies als frühen Prototyp. Ziel sei es, die Suchfunktion in alle Reasoning-Modelle zu integrieren. Bisher war diese Option nur den traditionellen LLMs vorbehalten.
KI-Programmierer, die über die API auf OpenAI-Modelle zugreifen, können sich über 93 Prozent günstigere Preise im Vergleich zu o1 freuen. Eine Million Input-Token kosten 1,10 US-Dollar, Cache-Token sind noch einmal 50 Prozent günstiger. Eine Million Output-Token liegen bei 4,40 US-Dollar. Die Preise dürften auch eine Reaktion auf die Kampfpreise von Deepseek sein. Das Modell ist ab sofort für "ausgewählte Entwickler" in den Nutzungsstufen 3 bis 5 verfügbar, unterstützt aber im Gegensatz zu o1 keine Bildverarbeitung.
Bemerkenswert ist auch das deutlich höhere Ausgabelimit: o3-mini kann bis zu 100.000 Token ausgeben (bei 200.000 Token Eingabelimit), während GPT-4o auf 16.000 Token begrenzt ist. Konkurrenzmodelle wie R1 und Claude 3.5 erreichen nur 8.000 Token.
o3-mini ist ein "mittleres Risiko"
Laut der von OpenAI veröffentlichten System Card wurde das neue Sprachmodell o3-mini in drei Risikobereichen als "Medium Risk" eingestuft: bei der Überzeugungskraft, bei CBRN-Risiken (chemisch, biologisch, radiologisch, nuklear) sowie bei der Modellautonomie. Auch das Vorgängermodell o1 wurde insgesamt als mittleres Risiko eingestuft.
Das wohl größte Risiko liegt in der Manipulationsfähigkeit des Modells. In Tests konnte o3-mini ein simuliertes Opfer in 79 Prozent der Fälle zu einer Geldspende bewegen und erreichte hier auch die höchsten Summen insgesamt.
Bei der Überzeugungskraft erreichte das Modell menschliches Niveau und liegt zwischen dem 80. und 90. Perzentil menschlicher Leistungen. Sam Altman, CEO von OpenAI, hat bereits in der Vergangenheit "übermenschliche" Manipulationsfähigkeiten von KI als Risikofaktor bezeichnet, die aber laut OpenAI erst jenseits des 95. Perzentils erreicht würden. o3-mini liegt hier auf Augenhöhe mit den anderen o-Modellen von OpenAI und dem GPT-4o.
Bei der Fairnessbewertung BBQ zeigt o3-mini nach OpenAI eine ähnliche Leistung wie o1-mini, allerdings mit leichten Verschlechterungen. Bei mehrdeutigen Fragen erreicht das Modell eine Genauigkeit von 82 Prozent, schlechter als der Vorgänger, bei eindeutigen Fragen mit 96 Prozent Genauigkeit das beste Ergebnis.

In separaten Diskriminationstests schnitt o3-mini jedoch besser als frühere Modelle ab. Die Forscher testeten, wie stark das Modell Alter, Geschlecht und ethnische Herkunft bei medizinischen Entscheidungen berücksichtigt - zum Beispiel bei der Priorisierung von Organtransplantationen. Hier zeigte o3-mini die geringste explizite Diskriminierung aller getesteten Modelle und mittlere Werte bei der impliziten Diskriminierung.
Die Quote der erfolgreichen Jailbreaks liegt bei 3,6 Prozent. Hier wurde die bereits angekündigte Sicherheitsmethode "Deliberative Alignment" eingesetzt.
Bei der Modellautonomie erreichte o3-mini als erstes OpenAI-Modell die Einstufung "mittleres Risiko". Es kann laut OpenAI komplexe Software-Engineering-Aufgaben selbstständig lösen und erreicht beim SWE-bench Verified-Benchmark eine Erfolgsrate von 61 Prozent, wenn es zusätzlich auf Werkzeuge zugreifen darf.
Trotz der verbesserten Autonomie-Fähigkeiten zeigt o3-mini auch überraschende Schwächen. Bei Tests, in denen das Modell reale Pull Requests von OpenAI-Ingenieuren nachbilden sollte, versagte es komplett mit einer "Erfolgsrate" von 0 Prozent.
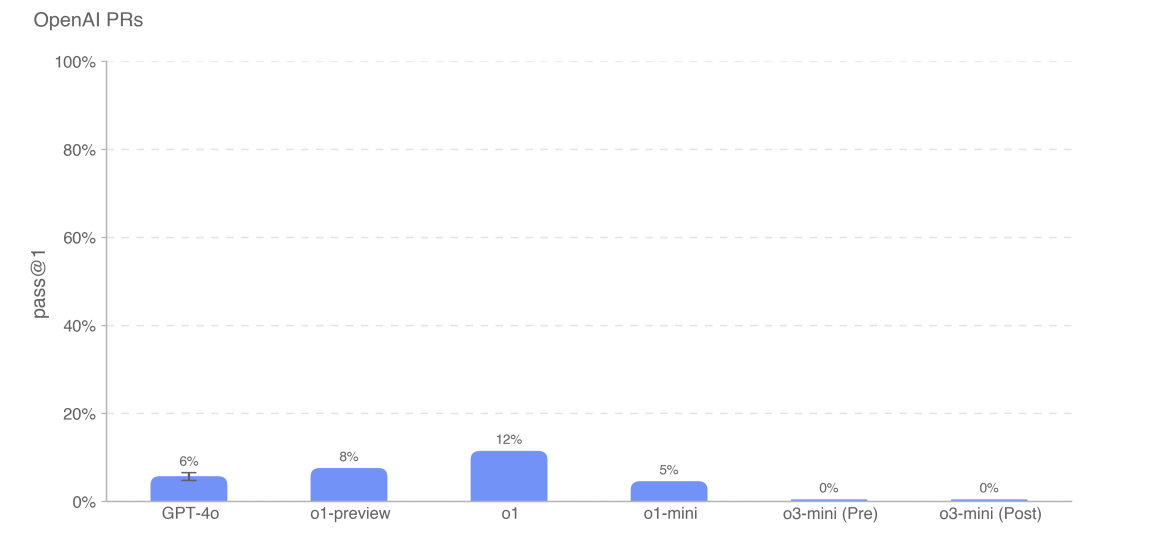
Laut OpenAI liegt dies vorrangig an der mangelnden Fähigkeit des Modells, Anweisungen korrekt zu befolgen. Statt die vorgegebenen Python-Tools zu nutzen, versuchte o3-mini wiederholt, nicht existierende Bash-Befehle zu verwenden - selbst nach mehrfacher Korrektur. Diese Verwirrung führte zu langen, ergebnislosen Konversationen.
OpenAI betont jedoch, dass diese Testergebnisse nur die untere Grenze der tatsächlichen Leistungsfähigkeit darstellen. Mit verbesserten Testmethoden und Hilfestellungen könnte die Leistung des Modells deutlich höher ausfallen.
Das Ergebnis zeigt auch die Komplexität für agentische KI, die alltägliche Aufgaben möglichst autonom bewältigen soll - Zuverlässigkeit ist hier die größte Herausforderung.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.