OpenAI zeigt, wie intern KI-Agenten Datenanalysen übernehmen

Kurz & Knapp
- OpenAI hat einen internen KI-Datenagenten gebaut, der über 70.000 Datensätze und 600 Petabyte Daten durchsuchbar macht.
- Eine Methode namens "Codex Enrichment" gibt dem Agenten Zugang zum Code, der Tabellen erzeugt, und ermöglicht so Unterscheidungen, die reine Metadaten verbergen.
- Der Agent nutzt sechs Kontextebenen und soll Analysen von Tagen auf Minuten beschleunigen.
OpenAI hat einen internen KI-Datenagenten entwickelt, der Mitarbeitern komplexe Datenanalysen in natürlicher Sprache ermöglicht. Eine Schlüsselmethode namens "Codex Enrichment" durchsucht dabei die Codebasis, um Tabellen wirklich zu verstehen.
Bei über 70.000 Datensätzen und 600 Petabyte Daten ist die richtige Tabelle zu finden keine triviale Aufgabe. "Wir haben viele Tabellen, die sich ziemlich ähnlich sind, und ich verbringe sehr viel Zeit damit herauszufinden, wie sie sich unterscheiden", zitiert OpenAI einen internen Nutzer.
In einem technischen Bericht beschreiben die Ingenieure Bonnie Xu, Aravind Suresh und Emma Tang, wie sie dem Agenten ein tieferes Verständnis von Daten beibringen. Der Schlüssel liegt im Code, der die Tabellen erzeugt.
Denn laut OpenAI beschreiben Metadaten und SQL-Abfragen zwar, wie eine Tabelle aussieht und genutzt wird. Was wirklich drin steckt, verraten sie jedoch nicht. OpenAI löst das mit einer Methode, die das Team intern "Codex Enrichment" nennt. Der Agent crawlt die Codebasis mittels Codex und leitet aus dem Code eine tiefere Definition jeder Tabelle ab. Pipeline-Logik erfasst Annahmen, Aktualitätsgarantien und Geschäftsabsichten, die in SQL oder Metadaten nie auftauchen.
Unterschiede erkennen, die Schemas verbergen
Das Problem, das OpenAI damit lösen will, ist Alltag bei großen Datenmengen. Viele Tabellen sehen oberflächlich ähnlich aus, unterscheiden sich aber in kritischen Details. Eine Tabelle enthält nur eingeloggte Nutzer, eine andere auch ausgeloggte. Eine erfasst nur First-Party ChatGPT-Traffic, eine andere alles.
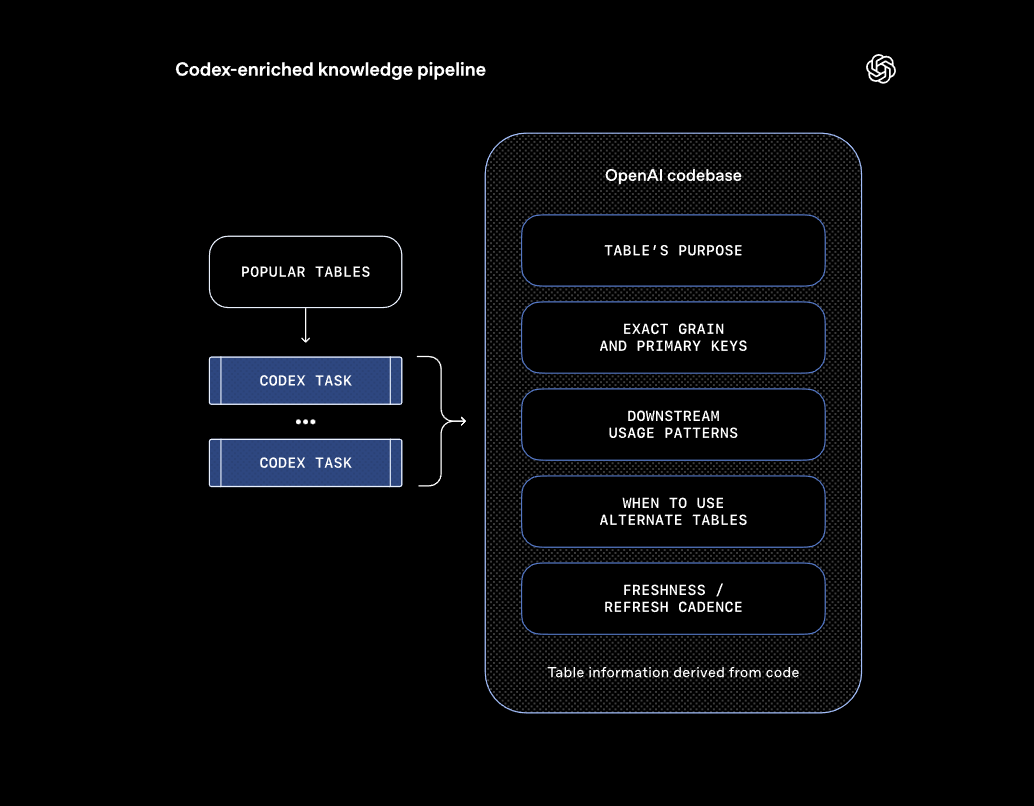
Durch die Code-Level-Analyse kann der Agent diese Unterschiede erkennen. Er versteht, welche Spalten eine Tabelle hat und wie die Daten gefiltert, transformiert und aggregiert wurden. Das ermöglicht ihm laut OpenAI, Fragen wie "Was ist hier drin?" und "Wann kann ich diese Tabelle verwenden?" weitaus genauer zu beantworten als durch bloße Datenbanksignale.
Ein weiterer Vorteil besteht in der automatischen Aktualisierung. Die Codex-Anreicherung passt sich ohne manuelle Wartung an, wenn sich der Code ändert, der eine Tabelle erzeugt.
Teil eines sechsschichtigen Kontextsystems
Codex Enrichment ist eine von sechs Kontextebenen, die OpenAIs Daten-Agent nutzt. Die erste Ebene umfasst Schema-Metadaten wie Spaltennamen und Datentypen sowie historische Abfragen, die zeigen, welche Tabellen typischerweise zusammen verwendet werden. Die zweite Ebene besteht aus kuratierten Beschreibungen von Domain-Experten, die Semantik, Geschäftsbedeutung und bekannte Einschränkungen erfassen. Die dritte Ebene ist Codex Enrichment.
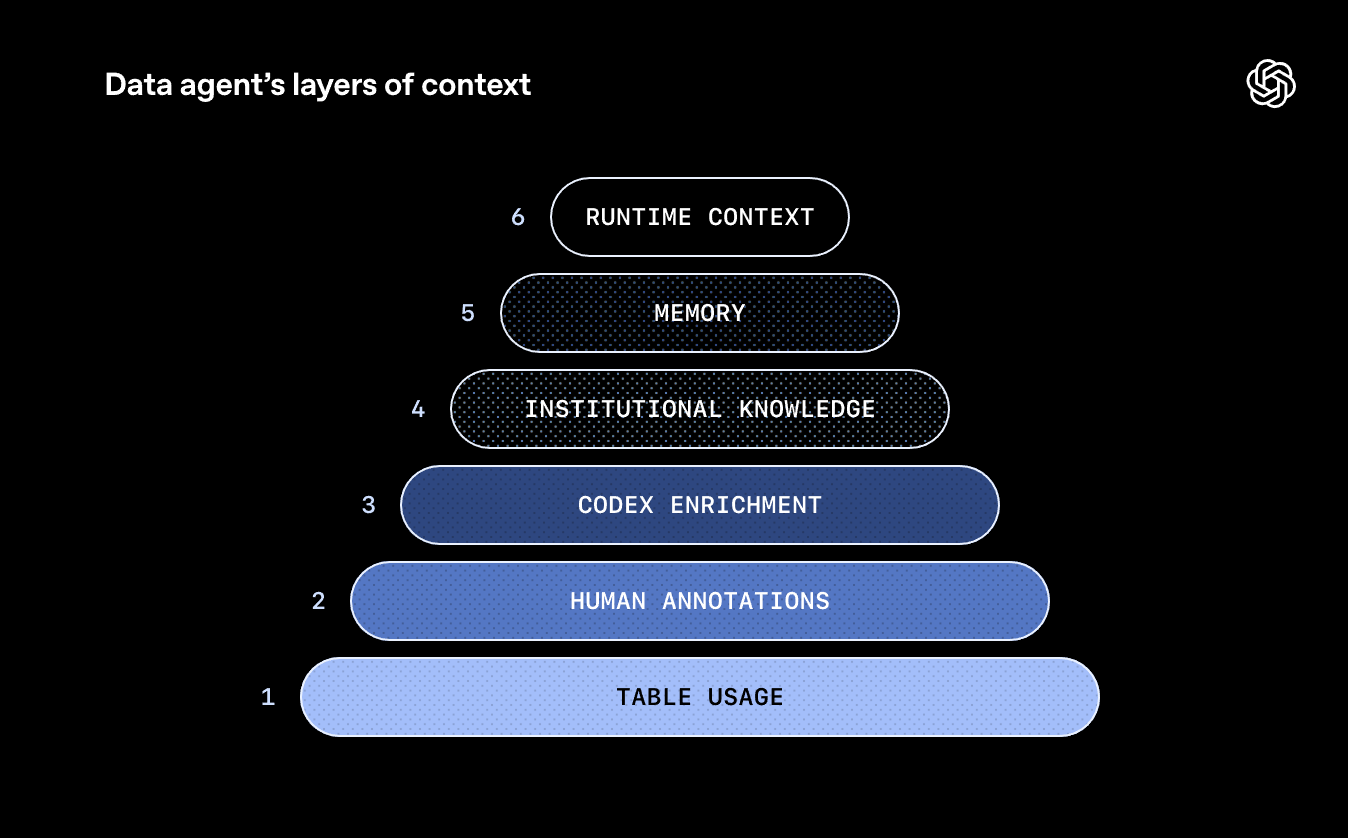
Die vierte Ebene greift auf institutionelles Wissen zu. Der Agent durchsucht Slack-Nachrichten, Google Docs und Notion-Dokumente nach Informationen über Produktlaunches, technische Incidents und kanonische Metrik-Definitionen. Die fünfte Ebene ist ein lernendes Gedächtnis, das Korrekturen und Nuancen aus früheren Gesprächen speichert und bei zukünftigen Anfragen anwendet. Die sechste Ebene ermöglicht Live-Abfragen an das Data Warehouse, wenn keine vorherigen Informationen existieren oder bestehende Daten veraltet sind.
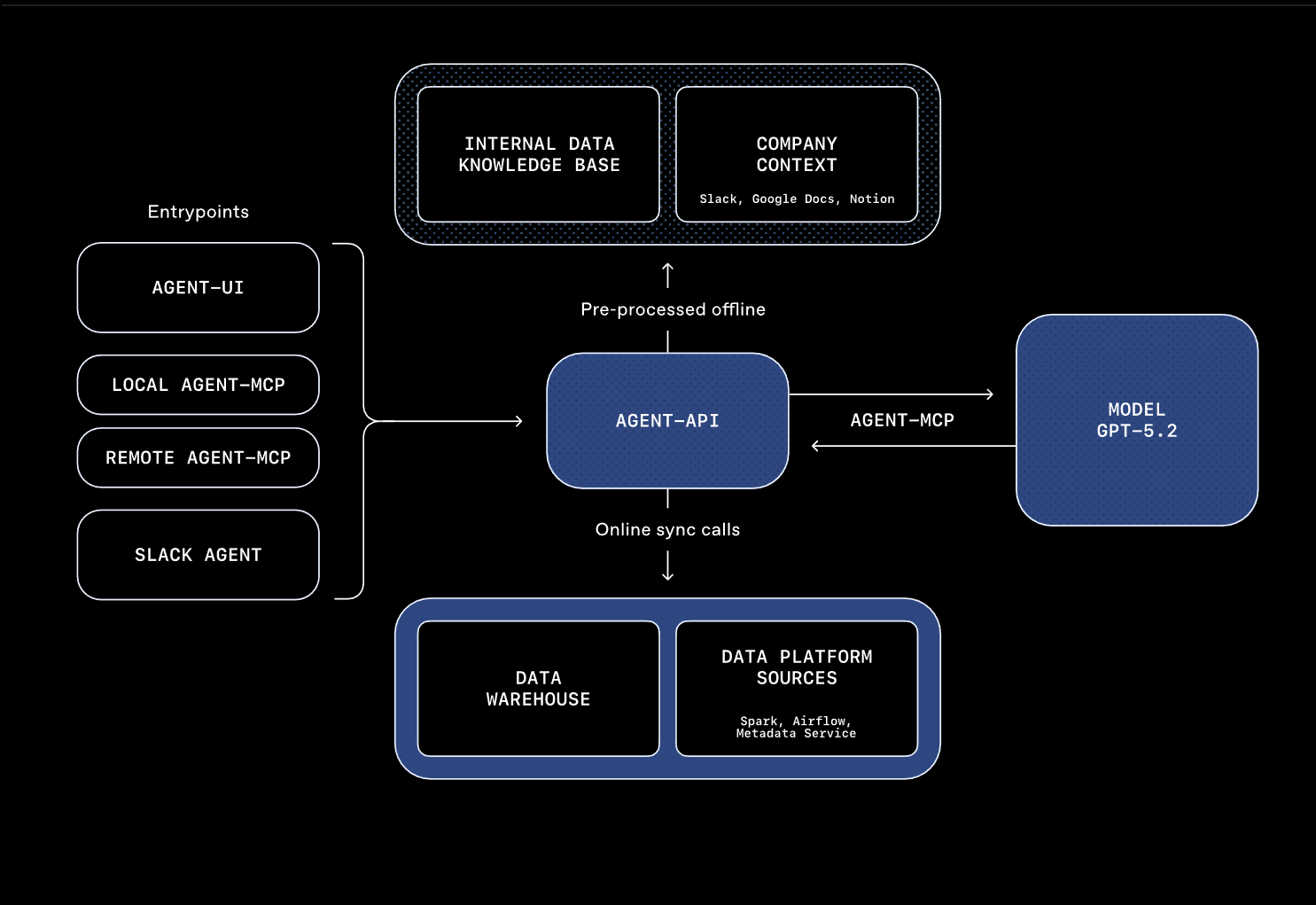
Der Zeitgewinn durch dieses System ist laut OpenAI erheblich: Bei einer einfachen Frage zu den täglichen aktiven Nutzern von ChatGPT Image Gen benötigte der Agent ohne Gedächtnis über 22 Minuten. Mit aktiviertem Memory sank die Zeit auf eine Minute und 22 Sekunden. Die Kombination der sechs Kontextebenen soll das zeitaufwendige Suchen nach der richtigen Tabelle automatisieren und Analysen von Tagen auf Minuten beschleunigen.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnieren