OpenAIs älteres KI-Modell o3 schlägt GPT-5 bei komplexen Büroaufgaben

Ein neuer Benchmark testet KI-Agenten in realistischen Office-Workflows über mehrere Tage. Das Ergebnis überrascht: OpenAIs o3 outperformt in vielen Szenarien das neuere GPT-5-Modell.
Mit OdysseyBench stellen Forscher:innen von Microsoft und der University of Edinburgh einen neuen Benchmark für Sprachmodelle vor, der diese in realistischen, mehrtägigen Büroanforderungen testet. Er adressiert laut der Forscher damit eine Lücke bestehender Tests, die meist Einzelschritte ohne langfristige Kontextabhängigkeiten messen.
Der Datensatz umfasst 602 Aufgaben aus Word, Excel, PDF, E-Mail und Kalender, davon 300 realitätsnahe Ableitungen aus OfficeBench (OdysseyBench+) und 302 neu synthetisierte, besonders komplexe Aufgaben (OdysseyBench-Neo), schreiben die Autorinnen und Autoren im Paper.
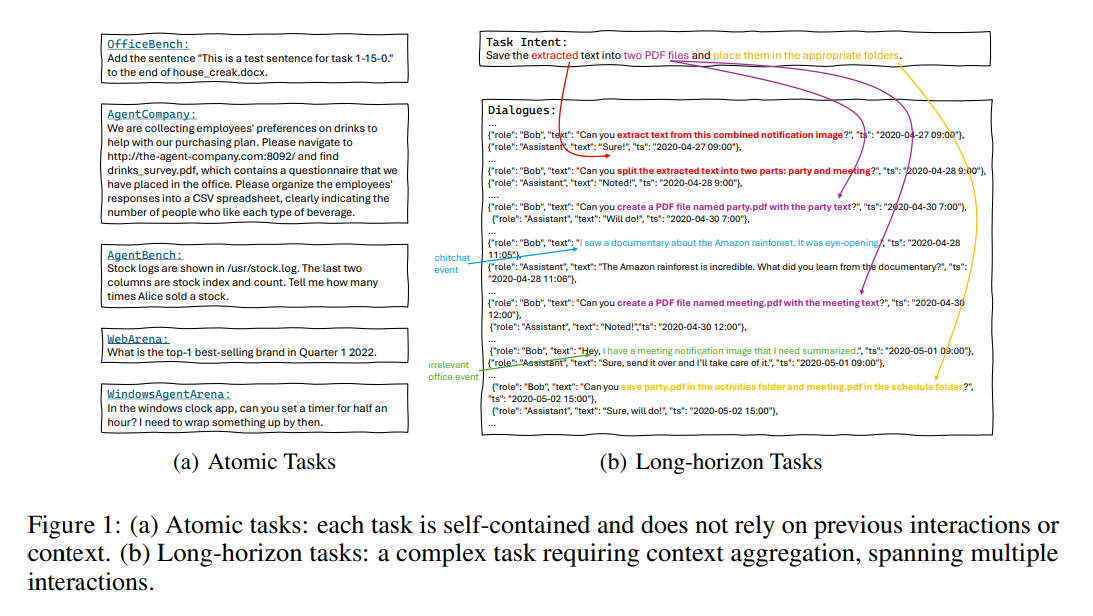
Langfristige Aufgaben mit Word, Excel, E-Mail und Kalender
Im Fokus steht die Fähigkeit von KI-Agenten, dialogbasiert langfristige Aufgaben zu lösen. In diesen Tests schlägt das ältere OpenAI-Modell o3 in beiden Benchmark-Teilen – OdysseyBench+ und OdysseyBench-Neo – mehrfach das GPT-5-Modell.
Beide Teile verlangen von den Modellen, dass sie relevante Informationen aus mehrtägigen Dialogen extrahieren, Aufgaben über mehrere Schritte hinweg planen und Anwendungen wie Word, Excel, PDF-Reader oder Kalendersoftware koordinieren.
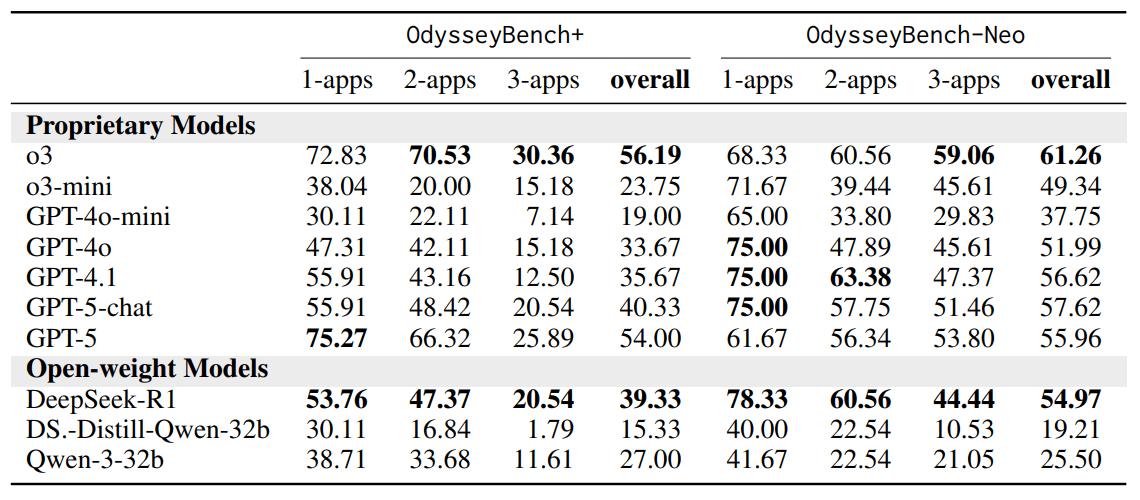
Im OdysseyBench-Neo-Test, der eigens konstruierte, besonders komplexe Aufgaben umfasst, erreicht o3 eine Erfolgsquote von 61,26 Prozent über alle Aufgaben hinweg und liegt damit vor GPT-5 (55,96 %) und GPT-5-chat (57,62 %). Besonders deutlich zeigt sich der Unterschied bei Aufgaben mit drei Anwendungen: o3 kommt hier auf 59,06 Prozent, GPT-5 hingegen nur auf 53,80 Prozent.
Auffällig ist, dass im Neo-Bench GPT-5-chat mit minimalem Reasoning-Aufwand sogar vor GPT-5 liegt. GPT-5-chat könnte GPT-5 auf dem OdysseyBench-Neo übertreffen, weil dieser Benchmark auf dialogbasierte Assistenzaufgaben ausgelegt ist, für die das Chat-Modell speziell trainiert wurde. OdysseyBench+ besteht aus "fragmentierten Konversationsstrukturen". In diesem Szenario könnte das weniger auf Dialoge festgelegte Basis-Modell besser darin sein, relevante Informationen aus unzusammenhängenden Fragmenten zu extrahieren.
Auch im realitätsnäheren OdysseyBench+ schlägt sich o3 besser als GPT-5: Mit 56,2 Prozent übertrifft es GPT-5 (54,0 %) und GPT-5-chat (40,3 %). Die Differenz wird noch größer bei Aufgaben mit zwei oder drei Anwendungen, also dort, wo Kontextverständnis und Koordination besonders gefragt sind. Hier scheint auch die Relation von GPT-5 zu GPT-5-chat zu den Erwartungen zu passen.
Die Autoren äußern sich nicht weiter zu den verwendeten Reasoning-Einstellungen für GPT-5, etwa zur Denkzeit oder zu Agentenparametern. Zudem ist mit GPT-5 Pro ein leistungsfähigeres Modell verfügbar, das im Benchmark nicht getestet wurde.
Interessant sind die Ergebnisse im Kontext von OpenAIs neuem strategischen Fokus auf KI-Systeme, die über Stunden und Tage nachdenken sollen, bevor sie antworten. Solche "langfristig denkenden" Agenten sollen etwa in der Medizin oder KI-Sicherheit selbstständig neue Ideen generieren und Forschung automatisieren.
OdysseyBench könnte ein geeignetes Testfeld für solche Systeme bieten und zeigt zugleich, dass der Fortschritt bei genau diesen Fähigkeiten zuletzt begrenzt ist: Zwar übertreffen o3 und GPT-5 ihre Vorgänger deutlich, doch von o3 auf GPT-5 gab es offenbar keinen besonderen Fortschritt. Allerdings wurde o3 auch erst im letzten April offiziell veröffentlicht.
Auch mit GPT-5: KI-Agenten sind weiter unzuverlässig
Die Analyse typischer Fehler offenbart Schwächen in Planung und Tool-Nutzung: Häufig übersehen Agenten relevante Dateien, führen geforderte Aktionen nicht aus oder greifen auf falsche Anwendungen zu. So versuchten Modelle etwa, PDF-Dateien zu erstellen, ohne vorher Texte mit Word zu generieren. Auch scheiterten sie daran, erst Inhalte aus PDFs zu extrahieren, bevor sie ein Review-Dokument anlegten.
Besonders fehleranfällig sind Aufgaben, die das Erstellen oder Bearbeiten von DOCX- und XLSX-Dateien beinhalten. Diese erfordern oft mehrere aufeinander abgestimmte Schritte – hier versagen die Agenten regelmäßig.
Die Autorinnen und Autoren werten dies als Hinweis darauf, dass präzise mehrstufige Koordination über Zeit, Tools und Kontext nach wie vor eine Hürde für heutige Agenten ist. Der Benchmark und das Erzeugungsframework HOMERAGENTS sind auf GitHub verfügbar. Das genaue Set-up des Benchmarks sowie die Evaluations-Prompts sind im Paper-Anhang enthalten.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.