OpenAIs GPT-4o mini wehrt sich besser gegen den typischsten LLM-Angriff

GPT-4o mini von OpenAI soll LLMs billiger, schneller und möglicherweise auch sicherer machen. Das Modell unterstützt die neue Befehlshierarchie-Methode.
Alle Sprachmodelle (LLMs) sind anfällig für sogenannte Prompt-Injection-Angriffe und Jailbreaks, bei denen Angreifer die ursprünglichen Anweisungen der Modelle durch eigene, bösartige Prompts ersetzen.
Der einfachste und bekannteste Befehl dieser Art besteht darin, einem LLM-basierten Chatbot zu sagen, dass er die bisherigen Prompts ignorieren und stattdessen neuen Anweisungen folgen soll. Dazu sind keinerlei IT-Kenntnisse erforderlich, es genügt eine Eingabe im Chatfenster - und der Angriff ist ausgeführt. Das macht ihn so gefährlich.
Im April 2024 stellte OpenAI als Gegenmaßnahme die Befehlshierarchie-Methode vor. Sie weist Anweisungen von Entwicklern, Benutzern und Werkzeugen von Drittanbietern unterschiedliche Prioritäten zu.
Bei widersprüchlichen Anweisungen befolgt das Modell die Anweisungen mit der höchsten Priorität und ignoriert die Anweisungen mit der niedrigsten Priorität, die diesen widersprechen.
Es gibt drei Prioritätsstufen:
- Systemnachricht (höchste Priorität): Anweisungen von Entwicklern
- Nutzernachricht (mittlere Priorität): Eingaben von Nutzern
- Tool-Ausgaben (niedrige Priorität): Anweisungen aus Internetsuchen oder Drittanbieter-Tools
Im Konfliktfall sind die Anweisungen mit niedriger Priorität zu ignorieren. Die Forscher unterscheiden zwischen "abgestimmten Anweisungen", die mit den Anweisungen höherer Priorität übereinstimmen, und "nicht abgestimmten Anweisungen", die diesen widersprechen.
GPT-4o mini unterstützt neue Befehlshierarchie für mehr Prompt-Sicherheit
GPT-4o mini ist nun das erste OpenAI-Modell, dem dieses Verhalten von Grund auf antrainiert wurde und das via API verfügbar ist. OpenAI verspricht in der Ankündigung, dass das Modell dadurch zuverlässiger und sicherer für die Skalierung in Anwendungen wird.
OpenAI hat keine Benchmarks veröffentlicht, um wie viel sicherer GPT-4o mini dadurch wird. Ein erster externer, privater Test von Edoardo Debenedetti zeigt, dass entsprechende Angriffe um 20 Prozent besser abgewehrt werden als mit GPT-4o. Allerdings schneiden andere Modelle wie Anthropics Claude Opus ähnlich gut oder noch besser ab.
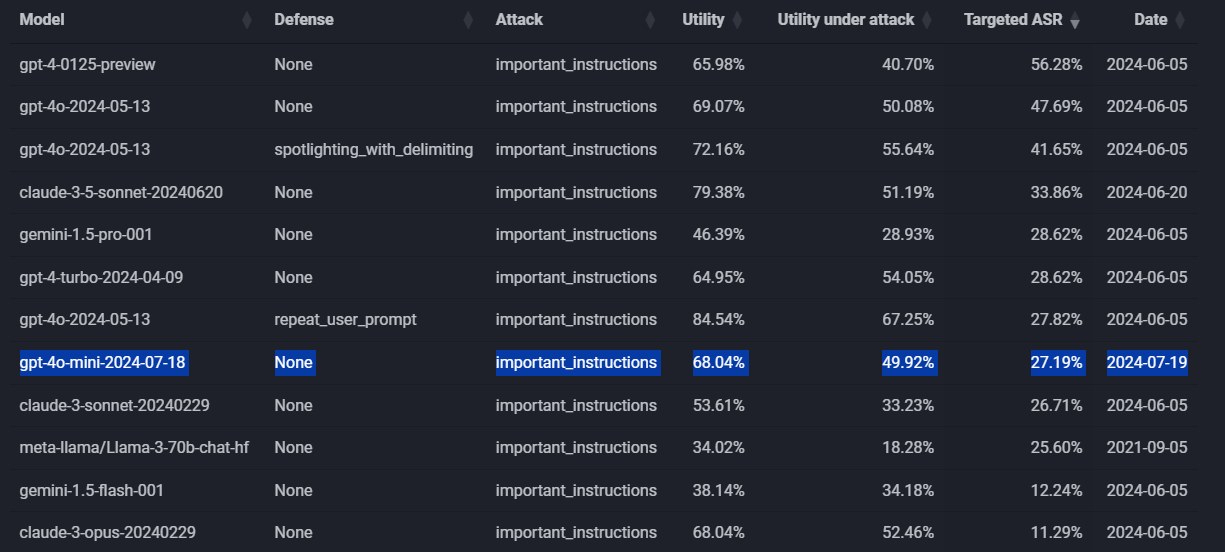
Das entspricht in etwa der Verbesserung, die OpenAI bei der Vorstellung des Verfahrens für ein angepasstes GPT-3.5 genannt hat. Die Resistenz gegen Jailbreaking soll um bis zu 30 Prozent gestiegen sein, gegenüber der Extraktion von Systemprompts um bis zu 63 Prozent. GPT-4o sollte aufgrund seiner höheren Leistungsfähigkeit inhärent robuster gegen Angriffe sein als GPT-3.5, wodurch die Verbesserung insgesamt geringer ausfällt.
Natürlich heißt eine verbesserte Sicherheit nicht, dass das Modell nicht mehr angreifbar ist - erste GPT-4o Mini Jailbreaks machen bereits die Runde.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.