OpenAIs o3 ist weniger AGI als ursprünglich angekündigt

Eine Analyse der ARC Prize Foundation zeigt, dass OpenAIs neues o3-Modell bei strengen Reasoning-Tests deutlich schlechter abschneidet als die zuvor getestete o3-Preview-Version.
Die ARC Prize Foundation versteht sich als Non-Profit-Organisation, die mit offenen Benchmarks wie ARC-AGI die Lücke zwischen menschlichen Fähigkeiten und dem Stand der Künstlichen Intelligenz aufzeigen will. Jede Modell-Evaluation soll dabei das Verständnis der Community für den aktuellen Stand der Technik erweitern.
Das Benchmark-Design konzentriert sich bewusst auf Aufgaben, die symbolisches Denken, mehrstufige Komposition und kontextabhängige Regelanwendung erfordern – Fähigkeiten, die Menschen oft ohne spezielles Training mitbringen, die aktuelle KI-Systeme aber nur eingeschränkt beherrschen.
Die Tests wurden auf den Reasoning-Stufen "low", "medium" und "high" durchgeführt. Diese Stufen steuern die Tiefe der Modell-Überlegungen: "low" bevorzugt Geschwindigkeit und minimalen Token-Verbrauch, während "high" zu umfassenderen Denkprozessen anregen soll. Insgesamt wurden für die Analyse zwei Modelle (o3 und o4-mini) auf drei Reasoning-Stufen über 740 Aufgaben aus ARC-AGI-1 und ARC-AGI-2 getestet, was zu 4.400 Datenpunkten führte.
Mehr Leistung für weniger Geld: o3 übertrifft o1
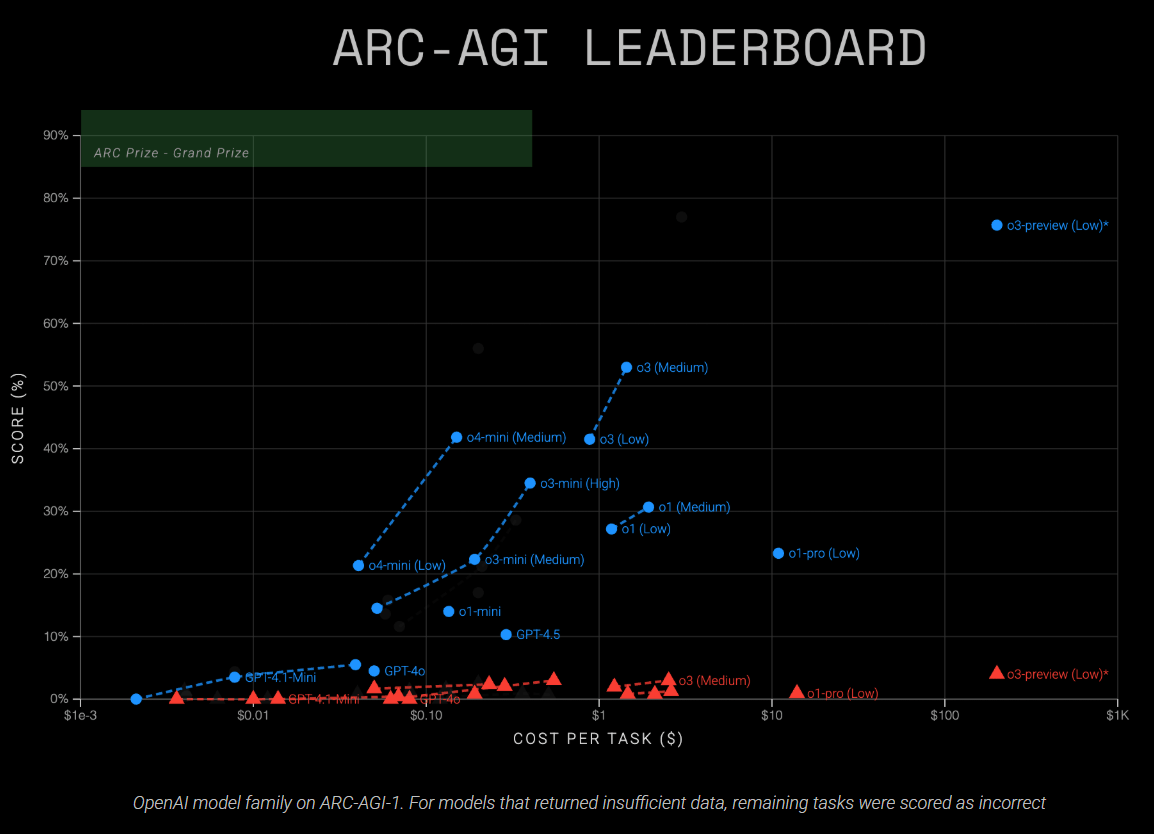
Laut der Analyse erreichte das o3-Modell 41 Prozent (low compute) und 53 Prozent (medium compute) im AGI-Benchmark-Test ARC-AGI-1. Auf dem schwierigeren ARC-AGI-2-Set blieb die Leistung jedoch unter drei Prozent.
Das kleinere o4-mini-Modell erzielte 21 Prozent (low compute) und 42 Prozent (medium compute) auf ARC-AGI-1, lag aber ebenfalls bei unter drei Prozent auf ARC-AGI-2.
Bei Tests mit erhöhtem Reasoning-Aufwand ("high" compute) konnten beide Modelle viele Aufgaben nicht abschließen. Die Analyse deutete zudem darauf hin, dass die Modelle bevorzugt Aufgaben beantworteten, die sie leichter lösen konnten, während schwierige Aufgaben häufiger unbeantwortet blieben. Eine Auswertung nur der erfolgreichen Antworten hätte daher das tatsächliche Leistungsniveau verzerrt. Deswegen wurden diese Teilergebnisse nicht für die offiziellen Leaderboards verwendet.
| Modell | Reasoning-Einstellung | Semi Private Eval V1 | Semi Private Eval V2 | Kosten pro Aufgabe (V2) |
|---|---|---|---|---|
| o3 | Low | 41 % | 1,9 % | 1,22 US-Dollar |
| o3 | Medium | 53 % | 2,9 % | 2,52 US-Dollar |
| o3 | High | — | — | — |
| o4-mini | Low | 21 % | 1,6 % | 0,05 US-Dollar |
| o4-mini | Medium | 42 % | 2,3 % | 0,23 US-Dollar |
| o4-mini | High | — | — | — |
Zudem zeigte sich, dass ein höherer Reasoning-Aufwand nicht automatisch zu besseren Ergebnissen führt, sondern oft nur zu höheren Kosten. Speziell o3-high verbraucht deutlich mehr Tokens, ohne bei einfacheren Aufgaben einen nennenswerten Genauigkeitsgewinn zu erzielen. Dies wirft Fragen nach der Skalierbarkeit des aktuellen Reasoning-Ansatzes auf.
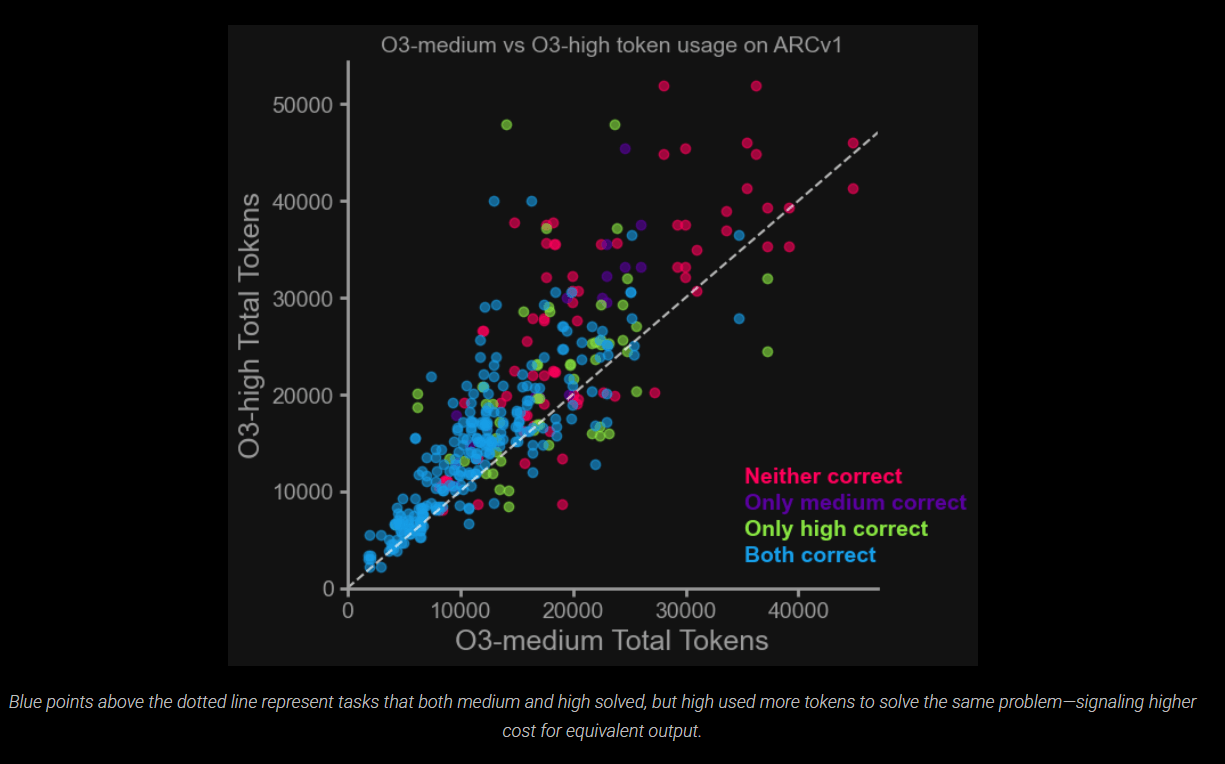
Für kostenbewusste Anwendungen empfiehlt die ARC Prize Foundation daher, standardmäßig o3-medium zu verwenden. Die Einstellung "high-reasoning" sei nur dann sinnvoll, wenn es auf maximale Genauigkeit ankommt und die Kosten eine untergeordnete Rolle spielen.
Die Stiftung betont generell, dass mit zunehmender Leistungsfähigkeit von KI-Modellen die Effizienz – also wie schnell, zu welchen Kosten und mit wie wenigen Tokens Probleme gelöst werden – zum entscheidenden Unterscheidungsmerkmal wird.
Besonders hervorzuheben sei hier die Effizienz von o4-mini: Es erreicht 21 Prozent Genauigkeit auf ARC-AGI-1 bei nur etwa fünf Cent Kosten pro Aufgabe. Zum Vergleich: Ältere Modelle wie o1-pro benötigen für ähnliche Leistungen etwa elf Dollar pro Aufgabe.
OpenAIs o3 ist weniger AGI als o3-preview
Die aktuelle o3-Version unterscheidet sich deutlich von der o3-Preview-Version, die im Dezember 2024 getestet wurde. Während o3-Preview damals im Textmodus beeindruckende 76 Prozent (low compute) und 88 Prozent (high compute) auf ARC-AGI-1 erreichte, liefert das nun veröffentlichte o3 mit 41 Prozent (low) bzw. 53 Prozent (medium) deutlich schwächere Ergebnisse.
OpenAI bestätigte gegenüber ARC, dass das veröffentlichte o3-Produktionsmodell mehrere Unterschiede aufweist: Es hat eine andere, kleinere Architektur als o3-preview, arbeitet multimodal (Text und Bild) und verfügt über geringere Compute-Ressourcen als die im Dezember getestete Preview-Version.
Bezüglich der Trainingsdaten gibt OpenAI an, dass das Training von o3-preview 75 Prozent des ARC-AGI-1-Datensatzes umfasste. Das veröffentlichte o3-Modell hingegen wurde laut OpenAI nicht direkt auf ARC-AGI-Daten trainiert, auch nicht auf dem Trainingsdatensatz. Eine indirekte Exposition durch die öffentliche Verfügbarkeit des Benchmarks sei jedoch möglich.
Eine weitere Änderung: Das veröffentlichte o3-Modell wurde für Chat- und Produktanwendungen verfeinert, was laut ARC Prize sowohl Stärken als auch Schwächen bei der Anwendung auf den ARC-AGI-Benchmark mit sich bringt. Das zeigt, dass Benchmark-Ergebnisse, insbesondere bei unveröffentlichten KI-Modellen, stets kritisch betrachtet werden sollten.
Fortschritt mit Einschränkungen
Das Modell o3-medium ist derzeit das leistungsstärkste öffentlich getestete Modell der ARC Prize Foundation auf ARC-AGI-1 und verdoppelt die typische Leistung früherer Chain-of-Thought-Modelle.
Dennoch bleibt insbesondere der kürzlich vorgestellte Benchmark ARC-AGI-2 für beide neuen Modelle weitgehend unlösbar. Während Menschen ohne spezielles Training durchschnittlich 60 Prozent der Aufgaben lösen, erreicht das stärkste Reasoning-Modell von OpenAI derzeit nur etwa drei Prozent. Das zeigt, dass trotz des technologischen Fortschritts nach wie vor eine große Lücke zwischen der Problemlösungsfähigkeit von Menschen und Maschinen klafft.
Eine kürzlich veröffentlichte Analyse deutet zudem darauf hin, dass sogenannte Reasoning-Modelle wie o3 vermutlich keine neuen Fähigkeiten besitzen, die über die ihrer zugrundeliegenden Basis-Sprachmodelle hinausgehen. Vielmehr sind sie darauf optimiert, bei bestimmten Aufgaben schneller zur richtigen Lösung zu gelangen – insbesondere bei Aufgaben, auf die sie durch gezieltes Reinforcement Learning trainiert wurden.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.