OpenSeeker will das Datenmonopol bei KI-Suchagenten auflösen
Kurz & Knapp
- OpenSeeker ist ein vollständig offener KI-Suchagent, der eigenständig mehrstufig im Internet recherchiert. Trainingsdaten, Code und Modellgewichte sind frei zugänglich und sollen das Datenmonopol großer Konzerne wie OpenAI oder Alibaba aufbrechen.
- Das Modell lernt anhand von Fragen, die aus der Verlinkungsstruktur des Webs erzeugt und gezielt so verschleiert werden, dass simples Nachschlagen nicht reicht. Ein Lehrer-Schüler-Verfahren trainiert es, aus verrauschten Rohdaten relevante Informationen zu filtern.
- Trotz minimalem Trainingsaufwand hält OpenSeeker mit deutlich ressourcenintensiveren Systemen großer Anbieter mit, bleibt aber hinter den stärksten proprietären Modellen zurück.
Mit nur 11.700 Trainingsdatenpunkten und einem einzigen Trainingsdurchlauf erreicht der KI-Suchagent OpenSeeker Ergebnisse, die mit Lösungen von Alibaba und Co. mithalten. Daten, Code und Modell sind vollständig offen zugänglich.
Leistungsfähige KI-Suchagenten, also Systeme, die eigenständig und über mehrere Schritte im Internet nach Informationen suchen, waren bislang eine Angelegenheit großer Technologiekonzerne. OpenAI, Google oder Alibaba halten ihre Trainingsdaten unter Verschluss. Selbst Projekte, die ihre Modellgewichte veröffentlichen, schweigen über die Daten dahinter.
Dieses Datenmonopol habe die offene Forschungsgemeinschaft fast ein Jahr lang ausgebremst, schreiben die Forschenden der Shanghai Jiao Tong University. Mit OpenSeeker will das akademische Team den Zustand beenden: Sämtliche Trainingsdaten (unter MIT-Lizenz), der Code und die Modellgewichte liegen offen vor.
Fragen aus der Linkstruktur des Internets statt aus dem Sprachmodell
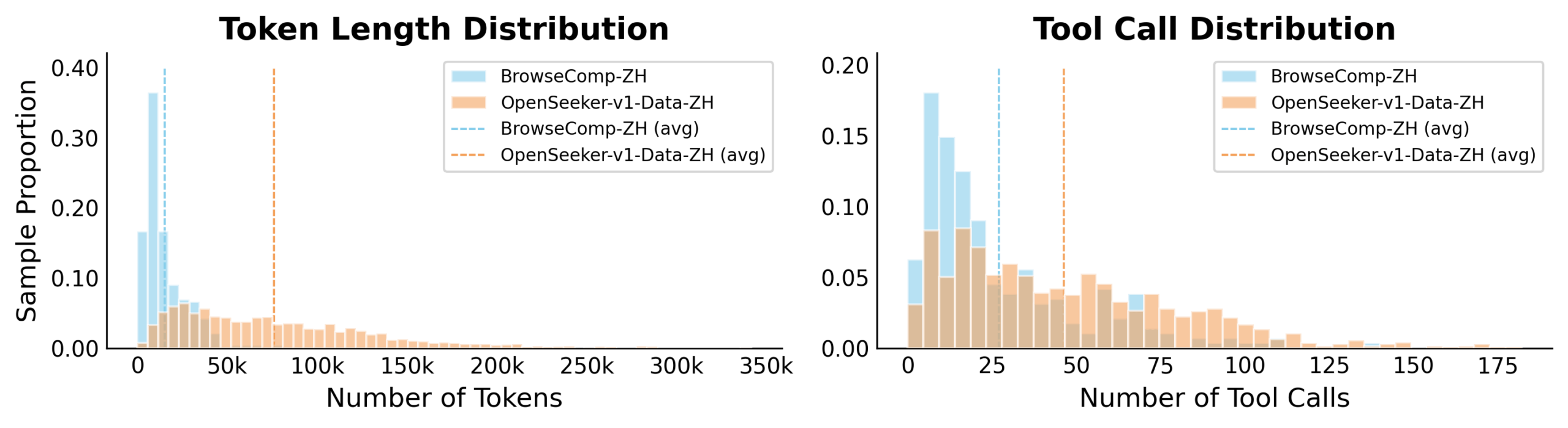
Hinter OpenSeeker stecken zwei Ideen zur Datenerzeugung. Für die Frage-Antwort-Paare nutzt das Team die reale Verlinkungsstruktur des Webs als Grundlage und lässt darauf aufbauend Fragen generieren. Ausgehend von zufällig gewählten Startseiten innerhalb eines Webkorpus (rund 68 GB englische und 9 GB chinesische Daten) folgt das System den Hyperlinks zu verwandten Seiten und extrahiert die wichtigsten Informationen.
Anschließend werden konkrete Namen und Begriffe gezielt durch vage Umschreibungen ersetzt, sodass ein Suchagent die Antwort nicht per simpler Stichwortsuche finden kann. Das erzwingt echtes mehrstufiges Suchen und Schlussfolgern.

Ein zweistufiger Filter sortiert unbrauchbare Fragen aus: Ein starkes Basismodell darf sie ohne Werkzeuge nicht beantworten können, muss sie aber mit vollständigem Kontext lösen können. Scheitert eine der beiden Bedingungen, wird die Frage verworfen.
Die zweite Idee betrifft die Suchpfade, an denen das Modell lernt. Webseiten enthalten viel Überflüssiges, das die Qualität der aufgezeichneten Lösungswege drückt. Während der Datenerzeugung erhält daher ein Lehrermodell eine bereinigte Zusammenfassung der bisherigen Suchergebnisse und trifft auf dieser Grundlage bessere Entscheidungen.
Im Training bekommt das Schülermodell dann die unbereinigten Rohdaten vorgesetzt und soll trotzdem die hochwertigen Entscheidungen des Lehrers reproduzieren. Das zwingt es, eigenständig zu lernen, Relevantes von Irrelevantem zu trennen.
11.700 Datenpunkte gegen 147.000: Qualität schlägt Quantität
OpenSeeker basiert auf Qwen3-30B-A3B und wurde mit lediglich 11.700 so erzeugten Datenpunkten in einem einzigen Durchlauf per überwachtem Feintuning trainiert, ohne Reinforcement Learning und ohne wiederholtes Nachjustieren.
Auf dem chinesischsprachigen BrowseComp-ZH-Benchmark erreicht das Modell laut dem Paper 48,4 Prozent und übertrifft damit Alibabas Tongyi DeepResearch mit 46,7 Prozent. Letzteres wurde mit einem dreistufigen Verfahren aus erweitertem Vortraining, überwachtem Feintuning und Reinforcement Learning trainiert.
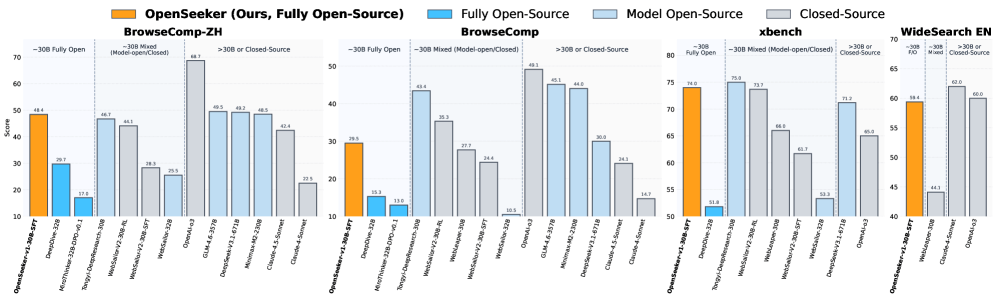
Auf dem englischsprachigen BrowseComp von OpenAI kommt OpenSeeker auf 29,5 Prozent, fast doppelt so viel wie DeepDive mit 15,3 Prozent, der bisherige Spitzenreiter unter den vollständig offenen Agenten.
Wie stark Datenqualität die reine Menge überwiegt, zeigt der Vergleich mit MiroThinker: Jenes Modell wurde mit 147.000 Trainingsbeispielen gefüttert und erreicht auf BrowseComp-ZH nur 13,8 Prozent. OpenSeeker schafft mit weniger als einem Zwölftel der Datenmenge das 3,5-Fache.
Im Vergleich mit den stärksten proprietären Systemen bleibt jedoch eine Lücke: OpenAIs GPT-5-High erreicht auf BrowseComp 54,9 Prozent, DeepSeek-V3.2 mit 671 Milliarden Parametern 51,4 Prozent. OpenSeeker operiert mit einem Bruchteil der Modellgröße und des Trainingsaufwands.
Die Frage, wer Zugang zu hochwertigen Trainingsdaten hat, beschäftigt die KI-Branche seit Langem. Bereits im vergangenen Jahr veröffentlichte ein Forschungsteam mit dem Common Pile einen 8 TB großen Textdatensatz aus offen lizenzierten Quellen. An der Vormachtstellung kommerzieller Modelle konnte das bislang wenig ändern.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnieren