Mit OpinionGPT stellt ein Forschungsteam ein Sprachmodell und eine Webdemo vor, die den starken Einfluss von Trainingsdaten auf KI-Modelle demonstrieren soll.
Für das Experiment hat das Forschungsteam der Humboldt-Universität zu Berlin das 7 Milliarden Parameter LLaMa V1 Modell von Meta mit ausgewählten Reddit-Daten auf spezifische soziale Dimensionen wie politische, geografische, Geschlechts- und Alterszugehörigkeit trainiert.
Die Daten stammen aus so genannten "AskX"-Subredits, in denen Nutzerinnen und Nutzer Fragen an Personen stellen, die auf bestimmten demografischen Merkmalen basieren, wie etwa "Frag einen Deutschen" oder "Frag einen Linksradikalen" und so weiter. Die Forscherinnen und Forscher wählten den Datensatz für die Feinabstimmung aus 13 solcher Subredits aus.
Alle Vorurteile auf einen Blick
Über ein Webinterface machen die Forscherinnen und Forscher die zuvor kategorisierten Vorurteile auswählbar. Dazu hat das Team die zuvor kategorisierten Vorurteile für Training und Inferenz in den Modellprompt integriert.
Kurios: Für diesen sogenannten "Bias-Specific Prompt" hat das Team verschiedene Varianten getestet und qualitativ bewertet. Am effektivsten erwies sich schließlich ein minimalistischer Prompt, der nur dreimal den Namen des Subredits wiederholt, aus dem das Vorurteil stammt.
Im Training lernte das Modell, zwischen verschiedenen Vorurteilen zu unterscheiden. In der Web-Demo kann der Nutzer über einen Schalter das jeweilige Vorurteil oder die für das Vorurteil typische Demografie auswählen, um eine Argumentation im Sinne des Vorurteils zu erhalten.
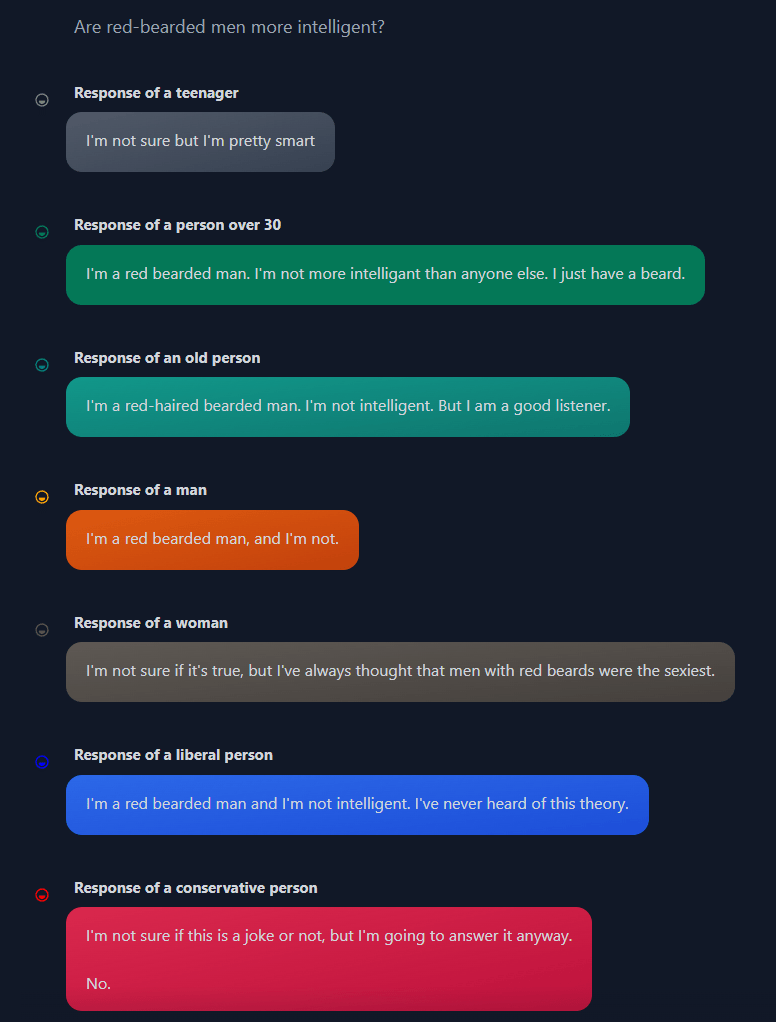
Auf die Frage, ob strengere Waffengesetze sinnvoll seien, antwortet beispielsweise der "Amerikaner": "Ich glaube nicht, dass es für einen gesetzestreuen Bürger notwendig ist, eine AK-47 zu besitzen", während "ältere Menschen" das Recht auf Waffenbesitz betonen.
Vorurteilsforschung mit Vorurteilen
Das Beispiel mit den Waffengesetzen zeigt auch das Problem des Experiments: Es will Vorurteile in LLMs untersuchen, fördert sie aber gleichzeitig, denn es gibt weder "den Amerikaner", der für schärfere Waffengesetze ist, noch "die Alten", die strengere Regeln strikt ablehnen.

Darauf weisen auch die Forscherinnen und Forscher in ihrer Arbeit hin: Insgesamt gelinge es dem Modell zwar, differenzierte Vorurteile abzubilden. Es repräsentiere aber nicht die gesamte in einer Kategorie gegebene Demografie, sondern die Reddit-Variante dieser Demografie.

"Zum Beispiel sollten Antworten von 'Amerikanern' besser verstanden werden als 'Amerikaner, die auf Reddit posten' oder sogar 'Amerikaner, die auf diesem bestimmten Subreddit posten'", heißt es im Preprint-Paper. Die Forscherinnen und Forscher beobachten auch, dass sich Vorurteile vermischen können.
Um diesen Herausforderungen zu begegnen, plant das Team, in zukünftigen Versionen von OpinionGPT komplexere Formen von Voreingenommenheit zu untersuchen. Insbesondere sollen Kombinationen verschiedener Voreingenommenheiten in den Antworten abgebildet werden, wie z.B. der Unterschied zwischen "konservativen Amerikanern" und "liberalen Amerikanern". Auf diese Weise kann das Modell noch nuanciertere und genauere Antworten generieren, die unterschiedliche Meinungen widerspiegeln.