OPT-IML: Meta veröffentlicht für Aufgaben optimiertes Open-Source-Sprachmodell
Mit OPT-IML bringt Meta ein auf Sprachaufgaben optimiertes Open-Source-Sprachmodell in der Größenordnung eines GPT-3. Es ist nur für Forschungszwecke verfügbar.
Der "Open-Pre-trained-Transformer - Instruction Meta-Learning" (OPT-IML) basiert auf Metas OPT-Sprachmodell, das Anfang Mai 2022 angekündigt und Ende Mai veröffentlicht wurde. Das größte Modell hat 175 Milliarden Parameter wie OpenAIs GPT-3, soll aber im Training deutlich effizienter gewesen sein und nur ein Siebentel des CO₂-Fußabdrucks von GPT-3 verursacht haben.
Fine-Tuning mit Sprachaufgaben
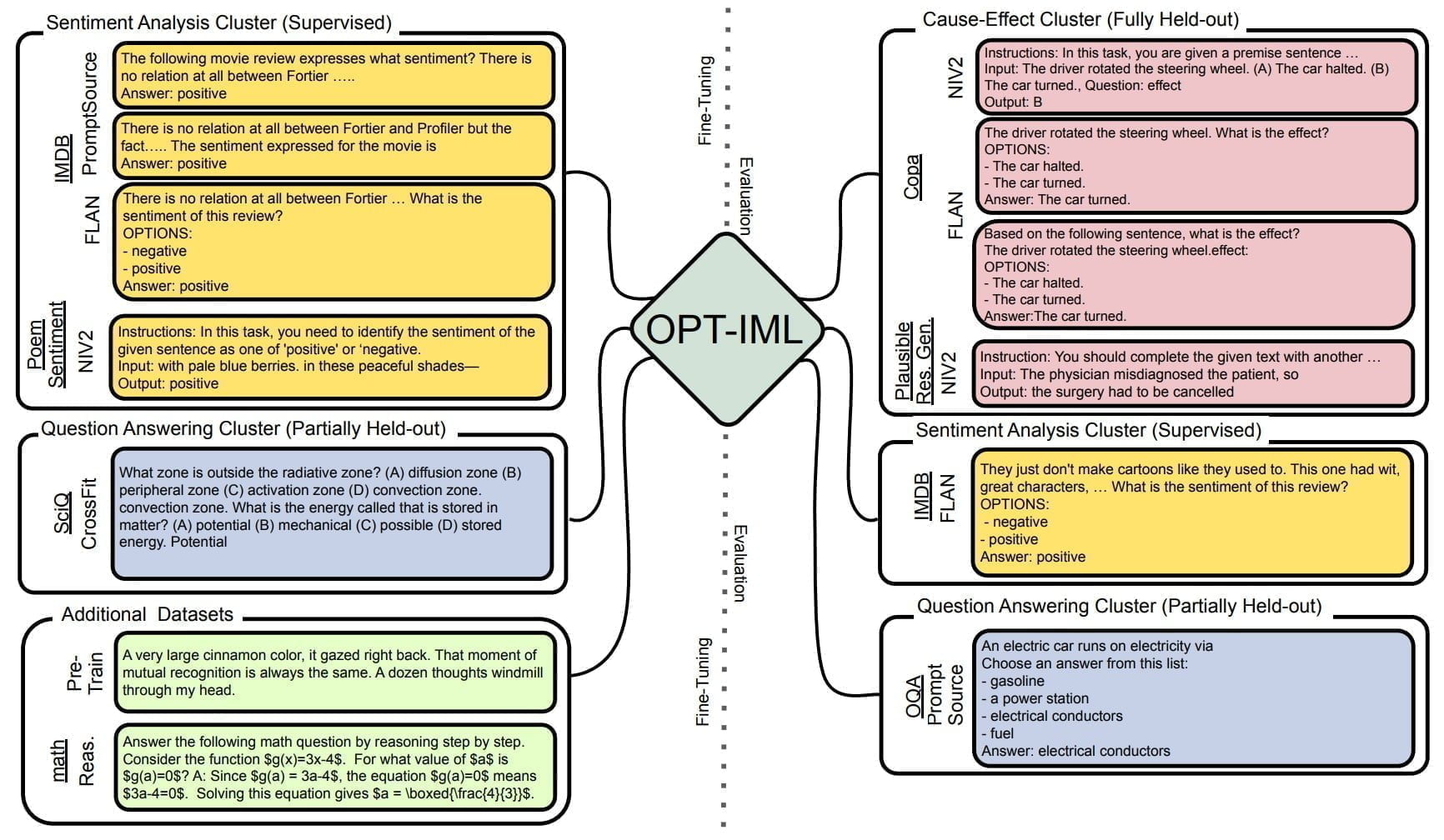
Die jetzt veröffentlichte IML-Version ist laut Meta mit einem Sammlung von bis zu rund 2000 natürlichen Sprachaufgaben auf die Erfüllung ebendieser feingetunt. Typische Sprachaufgaben sind etwa die Beantwortung von Fragen, Textzusammenfassungen und Übersetzungen. Die Aufgaben sind in acht NLP-Benchmarks (OPT-IML Bench) zusammengefasst, die die Forschenden ebenfalls zur Verfügung stellen.
Meta bietet OPT-IML in zwei Versionen an: OPT-IML selbst wurde mit 1500 Aufgaben trainiert, weitere 500 Aufgaben wurden für die Evaluation zurückgehalten. OPT-IML-Max wurde mit allen 2000 verfügbaren Aufgaben trainiert.
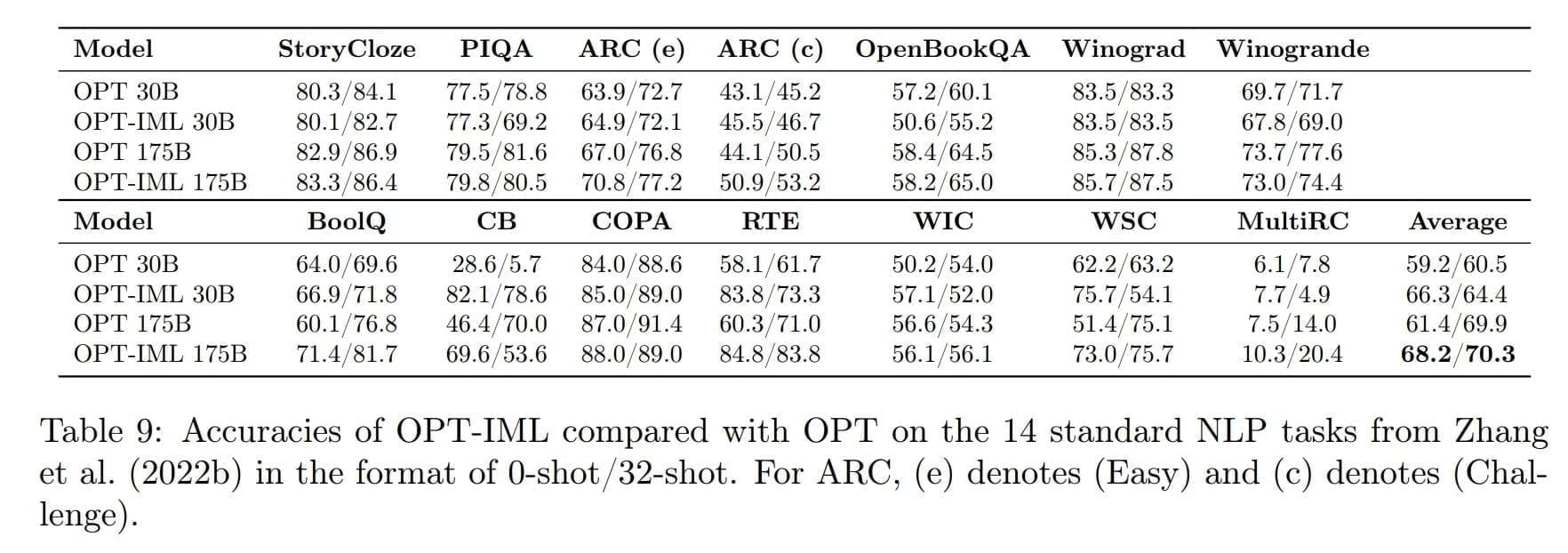
Im Durchschnitt verbessert OPT-IML die 0-Shot-Genauigkeit sowohl beim 30B- als auch beim 175B-Modell gegenüber OPT um etwa 6-7 %. Bei der 32-Shot-Genauigkeit sehen wir signifikante Verbesserungen beim 30B-Modell und geringere Verbesserungen beim 175B-Modell. Während die Verbesserungen bei bestimmten Aufgaben wie RTE, WSC, BoolQ, ARC, CB und WiC signifikant sind, verbessert unser Instruktionstuning die Leistung bei anderen Aufgaben wie StoryCloze, PIQA, Winograd und Winogrande nicht.
Aus dem Paper
In ihrem Paper stellen die Forschenden zudem strategische Evaluierungssplits für ihren Benchmark vor, um drei verschiedene Arten von Modellgeneralisierungsfähigkeiten zu evaluieren: 1) vollständig überwachte Leistung, 2) Leistung bei ungesehenen Aufgaben aus gesehenen Aufgabenkategorien und 3) Leistung bei Aufgaben aus vollständig ausgelassenen Kategorien. Mithilfe dieser Evaluierungssuite stellen sie Kompromisse und empfohlene Vorgehensweisen für viele Aspekte des Instruktionstunings vor.
Keine kommerzielle Nutzung
Meta veröffentlicht das 30-Milliarden-Parameter-Modell in beiden Versionen direkt bei Github als Download. Das OPT-IML-175B-Modell soll demnächst auf Bewerbung zur Verfügung gestellt werden. Das Antragsformular wird ebenfalls bei Github online gehen.
Anders als etwa GPT-3 via API darf OPT-IML nicht für kommerzielle Zwecke verwendet werden. Die bereitgestellte OPT-Lizenz gilt ausschließlich für nicht kommerzielle Forschungszwecke. Die Lizenz ist an die Empfangsperson gebunden und darf nicht weitergegeben werden.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.