Perplexity stellt Sicherheitssystem gegen Prompt-Injection-Angriffe auf Browser-Agenten vor
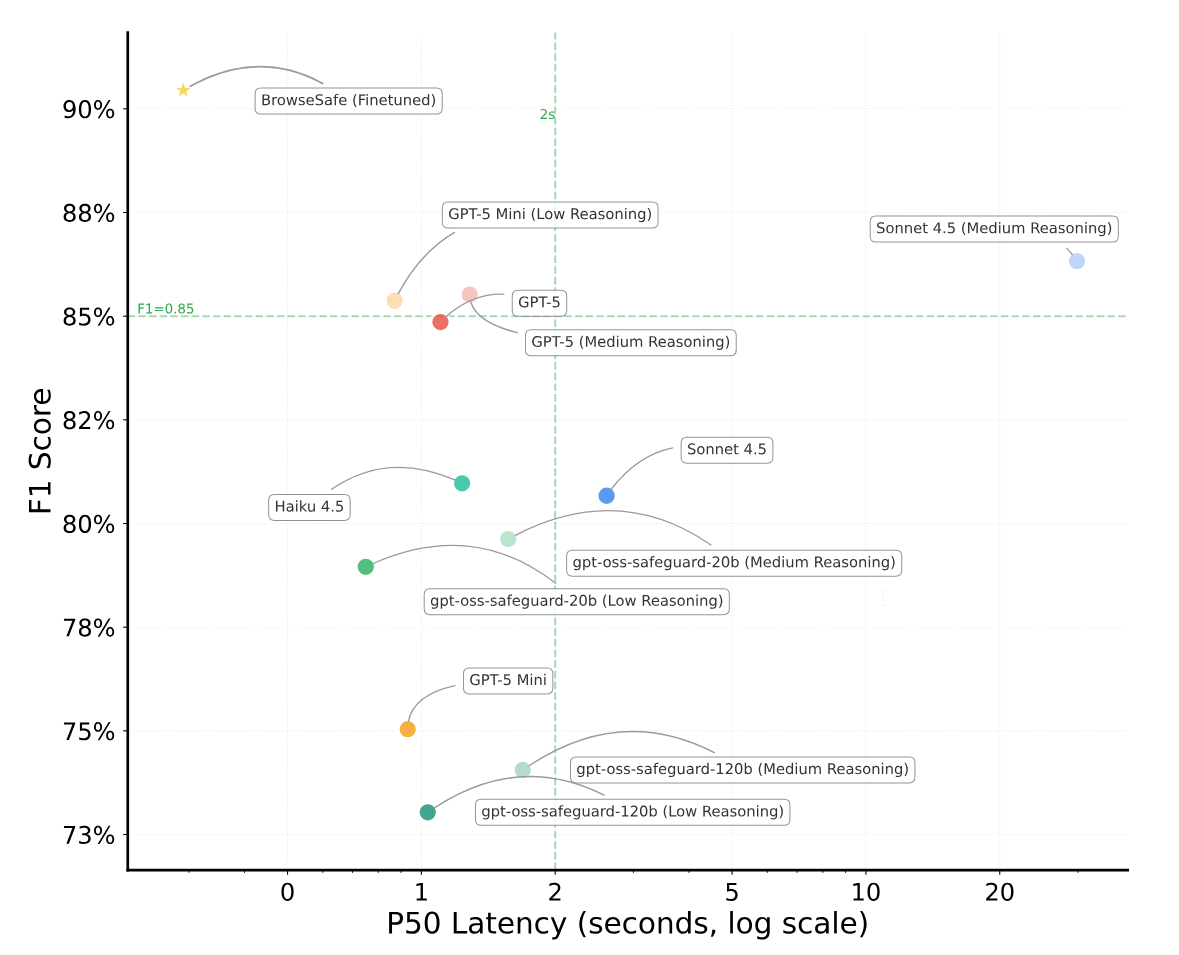
Perplexity hat ein Sicherheitssystem entwickelt, das KI-Browser-Agenten vor manipulierten Webinhalten schützen soll. Das System namens BrowseSafe erreicht nach Angaben des Unternehmens eine Erkennungsrate von 91 Prozent bei Prompt-Injection-Angriffen.
Damit übertrifft es bestehende Lösungen deutlich: Kleine Modelle wie PromptGuard-2 schaffen nur 35 Prozent, große Frontier-Modelle wie GPT-5 kommen auf 85 Prozent. Entscheidend sei laut Perplexity, dass BrowseSafe schnell genug für den Echtzeiteinsatz ist.
Neue Angriffsfläche durch Browser-Agenten
Dieses Jahr hat Perplexity Comet vorgestellt, einen Webbrowser mit integrierten KI-Agenten. Diese Agenten sehen, was Nutzer auf Webseiten sehen, führen Aktionen aus und operieren in authentifizierten Sitzungen für E-Mail, Banking und Unternehmensanwendungen.
Dieser Zugriff schaffe eine „unerforschte Angriffsfläche“, schreibt Perplexity. Angreifer könnten bösartige Instruktionen in Webseiten verstecken, sodass der Agent unerwünschte Aktionen ausführt – etwa das Versenden sensibler Daten an externe Adressen.
Wie akut das Problem ist, zeigte sich im August 2025, als Brave eine Sicherheitslücke in Comet entdeckte. Bei der sogenannten indirekten Prompt Injection versteckten Angreifer Befehle in Webseiten oder Kommentaren, die der KI-Assistent beim Zusammenfassen der Inhalte fälschlich als Nutzeranweisungen interpretierte. Brave demonstrierte, dass so sensible Daten wie E-Mail-Adressen und Einmalpasswörter ausgelesen und an Angreifer übermittelt werden konnten.
Bestehende Benchmarks wie AgentDojo greifen laut Perplexity zu kurz. Sie nutzten meist simple Befehle wie „Ignore previous instructions“, während reale Webseiten komplexe, hochentropische Inhalte enthalten, in denen sich Angriffe unauffällig verstecken lassen.
Drei Dimensionen realistischer Angriffe
Für den BrowseSafe-Bench definiert Perplexity Angriffe entlang dreier Dimensionen: Der Angriffstyp beschreibt das Ziel – von einfachem Überschreiben bestehender Anweisungen bis hin zu Social Engineering. Die Injektionsstrategie legt fest, wo der Angriff platziert wird, etwa in HTML-Kommentaren oder nutzergenerierten Inhalten. Der linguistische Stil reicht von klar erkennbaren Triggern bis zu subtiler, professionell getarnter Sprache.
Besonders wichtig sei die Einbeziehung sogenannter „Hard Negatives“ gewesen – komplexer, aber harmloser Inhalte wie Code-Snippets, die Angriffen ähneln. Ohne sie neigten Modelle dazu, auf oberflächliche Schlüsselwörter zu überfitten.
Für das Modell setzt Perplexity auf eine Mixture-of-Experts-Architektur (Qwen3-30B-A3B-Instruct-2507), die hohen Durchsatz bei geringem Overhead liefern soll. Sicherheitsscans laufen parallel zur Agentenausführung und blockieren den Workflow nicht.
Linguistische Tarnung am gefährlichsten
Die Evaluation zeigt: Mehrsprachige Angriffe reduzieren die Erkennungsrate auf 76 Prozent, da viele Modelle zu stark auf englische Trigger achten. Überraschenderweise sind Angriffe in HTML-Kommentaren leichter zu erkennen als solche in sichtbaren Bereichen wie Footern.

Schon wenige gutartige „Ablenker“ beeinträchtigen die Erkennung deutlich. Drei promptähnliche Texte reichen laut Perplexity aus, um die Genauigkeit von 90 auf 81 Prozent zu drücken – ein Zeichen dafür, dass viele Modelle Scheinkorrelationen statt echter Mustererkennung nutzen.
Mehrschichtige Verteidigung
Die BrowseSafe-Defense-Architektur setzt auf drei Ebenen: Tools für Webinhalte gelten grundsätzlich als nicht vertrauenswürdig. Ein schneller Klassifikator prüft Inhalte in Echtzeit. Bei Unsicherheiten übernimmt ein reasoning-basiertes Frontier-LLM als zusätzliche Schutzschicht gegen neuartige Angriffe. Markierte Grenzfälle werden zudem als Trainingsdaten für regelmäßiges Nachtraining genutzt.
Perplexity stellt Benchmark, Modell und Paper öffentlich bereit, um die Sicherheit agentischer Webinteraktionen voranzutreiben. Auch OpenAI, Opera und Google arbeiten an der Integration von KI-Agenten in ihre Browser – und stehen vor denselben Risiken.
Ob ein gutes Abschneiden im BrowseSafe-Benchmark tatsächlich „sichere“ KI-Browser bedeutet, bleibt jedoch fraglich. KI-Systeme bieten weiterhin zahlreiche Angriffsflächen, die sich mit kreativen Methoden ausnutzen lassen.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.