Perplexity veröffentlicht speicherschonende Embedding-Modelle als Open Source

Die KI-Suchmaschine Perplexity stellt zwei neue Text-Embedding-Modelle vor, die bei einem Bruchteil des üblichen Speicherbedarfs mit Googles und Alibabas Modellen mithalten oder sie übertreffen sollen. Beide Modelle sind Open Source.
KI-Suchmaschinen stehen vor einem grundlegenden technischen Problem: Bevor ein Sprachmodell eine Antwort formulieren kann, muss aus Milliarden von Webseiten erst eine Handvoll relevanter Dokumente herausgefiltert werden.
Diese erste Filterstufe übernehmen sogenannte Embedding-Modelle. Sie übersetzen Suchanfragen und Dokumente in numerische Vektoren und machen so semantische Ähnlichkeit mathematisch berechenbar. Welche Dokumente überhaupt an nachgelagerte Ranking-Modelle und Sprachmodelle weitergereicht werden, hängt direkt von der Qualität dieser Embeddings ab.
Perplexity hat nun mit pplx-embed-v1 und pplx-embed-context-v1 zwei eigene Embedding-Modelle veröffentlicht. Die erste Variante ist auf klassisches dichtes Text-Retrieval ausgelegt, die zweite bettet Textpassagen zusätzlich im Kontext des umgebenden Dokuments ein, was etwa bei mehrdeutigen Passagen helfen soll. Beide Modelle gibt es mit 0,6 Milliarden und 4 Milliarden Parametern.

Textverständnis in beide Richtungen statt nur vorwärts
Die meisten führenden Embedding-Modelle basieren laut den Forschern auf großen Sprachmodellen, die Text nur in eine Richtung verarbeiten, von links nach rechts. Jedes Wort kann dabei nur die vorhergehenden Wörter "sehen", nicht die nachfolgenden. Für Textgenerierung ist das sinnvoll, für das Verständnis einer Textpassage jedoch eine Einschränkung, weil sich die Bedeutung eines Satzes oft erst aus dem vollständigen Zusammenhang erschließt.
Perplexity wählt einen anderen Ansatz. Als Grundlage dienen vortrainierte Qwen3-Sprachmodelle von Alibaba, die ursprünglich Text nur von links nach rechts verarbeiten. Die Forscher bauen diese Modelle so um, dass sie Text in beide Richtungen lesen können.
Anschließend wird das Modell mit einem Lückenfüllverfahren trainiert, das an das Prinzip hinter Googles BERT erinnert: In Textpassagen werden zufällig Wörter verdeckt, und das Modell muss die fehlenden Stellen aus dem umgebenden Text in beide Richtungen erschließen.
Die Forscher bezeichnen das als Diffusions-Pretraining. Trainiert wurde auf rund 250 Milliarden Token in 30 Sprachen, wobei die Hälfte der Daten aus englischsprachigen Bildungs-Webseiten des FineWebEdu-Datensatzes stammt und die andere Hälfte 29 weitere Sprachen aus FineWeb2 abdeckt. In Ablationsstudien habe der Ansatz etwa einen Prozentpunkt Verbesserung bei Retrieval-Aufgaben gebracht.
Ein weiterer praktischer Unterschied zu vielen Konkurrenzmodellen: Die pplx-embed-Modelle erfordern laut dem Unternehmen keine vorformulierten Aufgabenbeschreibungen, die jedem Input vorangestellt werden müssen. Solche Prefixes können laut Perplexity die Suchqualität verschlechtern, wenn sie zwischen Indexierung und Abfragezeitpunkt nicht übereinstimmen.
Speicherbedarf sinkt um das bis zu 32-Fache
Embedding-Vektoren für Milliarden von Webseiten zu speichern, wird schnell teuer. Üblich sind Gleitkommazahlen mit 32-Bit-Genauigkeit pro Wert (FP32). Perplexity trainiert seine Modelle stattdessen von Beginn an darauf, mit ganzzahligen Werten bei nur 8-Bit-Genauigkeit (INT8) auszukommen, was den Speicherbedarf laut Perplexity um den Faktor 4 senkt, ohne die Leistung zu beeinträchtigen.
In einer noch kompakteren Variante mit nur einem Bit pro Wert (Binary) schrumpft der Bedarf sogar um den Faktor 32. Beim 4B-Modell liege der Qualitätsverlust dabei unter 1,6 Prozentpunkten, da dessen größerer Embedding-Vektor mit 2.560 Dimensionen mehr Informationen bewahre als die 1.024 Dimensionen des kleineren Modells.
Öffentliche Benchmarks zeigen Gleichstand mit der Konkurrenz
Auf dem MTEB-Retrieval-Benchmark (Multilingual, v2) erreicht pplx-embed-v1-4B einen nDCG@10 von 69,66 Prozent. Das entspricht laut Perplexity Alibabas Qwen3-Embedding-4B (69,60 Prozent) und übertrifft Googles gemini-embedding-001 (67,71 Prozent) bei gleichzeitig deutlich geringerem Speicherverbrauch. Beim kontextuellen Retrieval setzt pplx-embed-context-v1-4B laut Perplexity einen neuen Bestwert auf dem ConTEB-Benchmark mit 81,96 Prozent, gegenüber 79,45 Prozent für Voyages voyage-context-3 und 72,4 Prozent für Anthropics kontextuelles Modell.
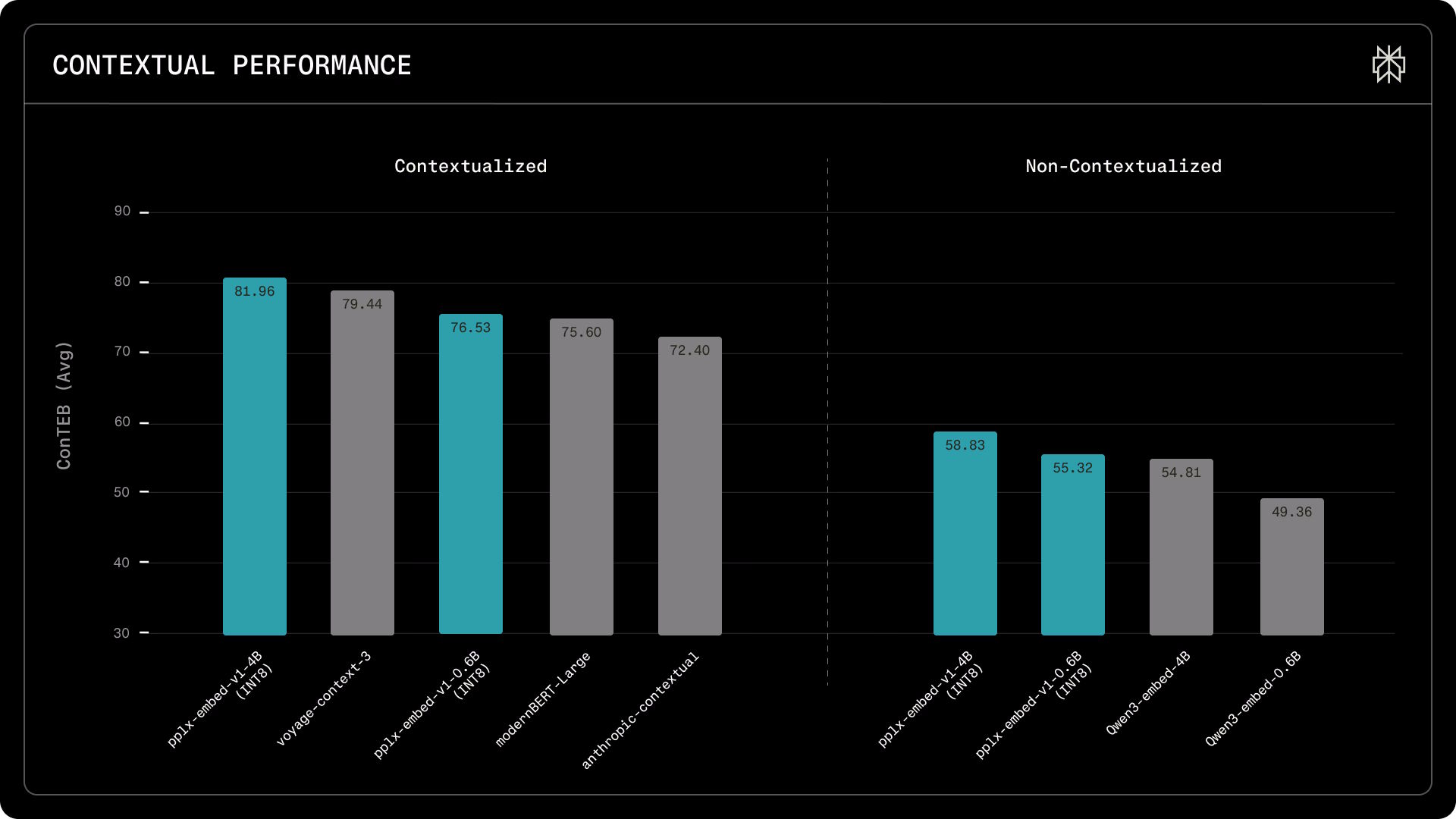
Im BERGEN-Benchmark, der die End-to-End-Leistung in RAG-Szenarien misst, also den Weg von der Dokumentensuche bis zur generierten Antwort, übertrifft das kleine pplx-embed-v1-0.6B laut Perplexity das deutlich größere Qwen3-Embedding-4B in drei von fünf Aufgaben. Das kleinere Modell könnte damit eine interessante Option für Anwendungsfälle sein, in denen Latenz und Rechenkosten entscheidend sind.
Interne Tests mit echtem Suchverkehr fallen deutlicher aus
Öffentliche Benchmarks bilden die Herausforderungen realer Websuche laut Perplexity nur unvollständig ab, weil ungewöhnliche Suchanfragen, verrauschte Dokumente und Verteilungsverschiebungen dort weitgehend fehlten. Deshalb hat das Unternehmen zwei interne Benchmarks mit bis zu 115.000 realen Suchanfragen gegen mehr als 30 Millionen Dokumente aus über einer Milliarde Webseiten entwickelt.
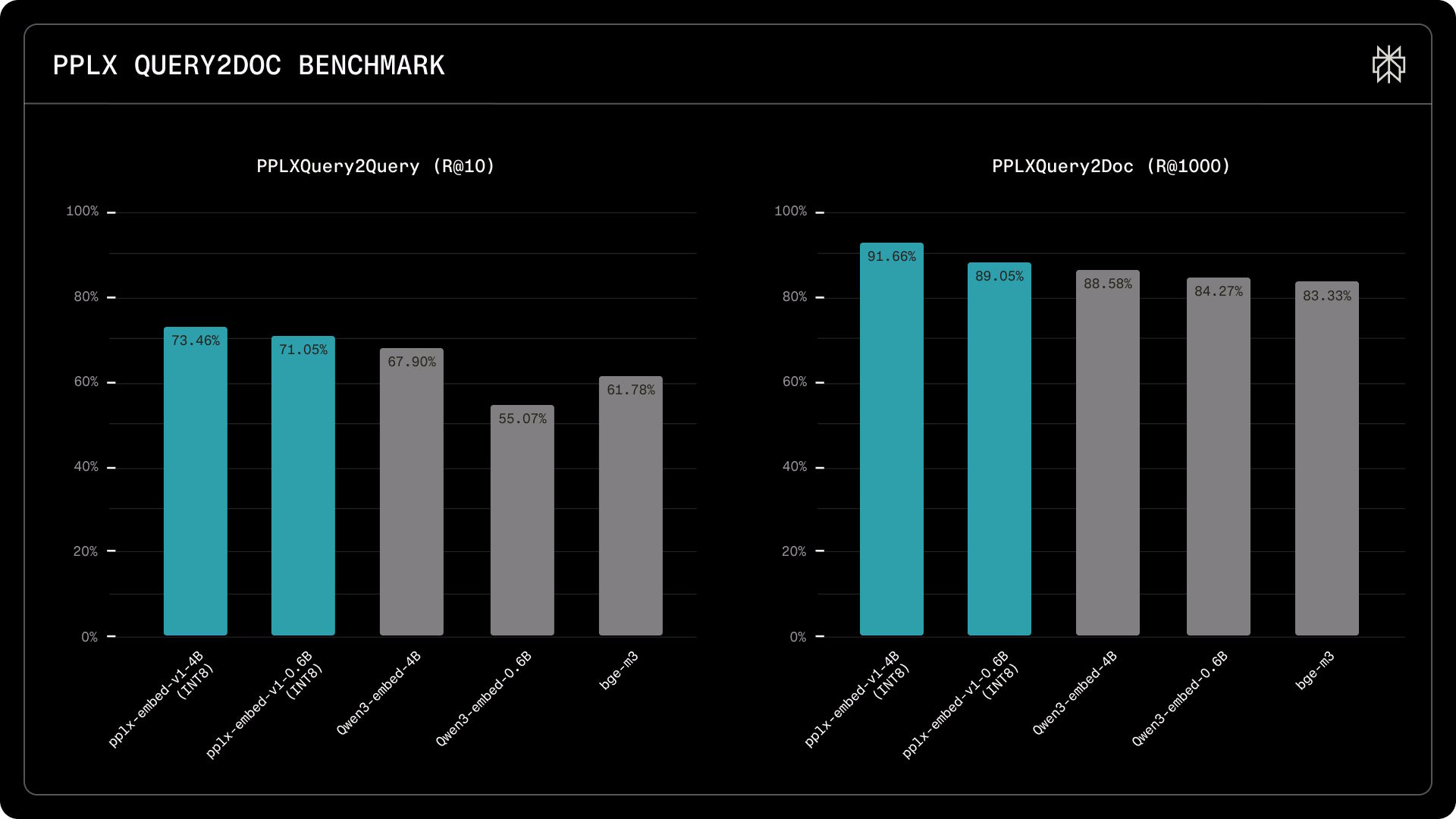
Die Abstände fallen hier größer aus als auf öffentlichen Tests. Beim PPLXQuery2Query-Benchmark, der misst, ob ein Modell bedeutungsgleiche Suchanfragen erkennt, findet pplx-embed-v1-4B 73,5 Prozent der relevanten Treffer unter den ersten zehn Ergebnissen, gegenüber 67,9 Prozent für Qwen3-Embedding-4B. Das 0,6B-Modell kommt auf 71,1 Prozent und übertrifft damit Qwen3-Embedding-0.6B (55,1 Prozent) und BGE-M3 (61,8 Prozent) deutlich. Beim PPLXQuery2Doc-Test, der die Dokumentensuche in einem Korpus von 30 Millionen Seiten prüft, findet das 4B-Modell 91,7 Prozent der relevanten Dokumente unter den ersten 1.000 Ergebnissen, gegenüber 88,6 Prozent für Qwen3.
Für Embedding-Modelle, die als erste Filterstufe arbeiten, kommt es laut Perplexity vor allem darauf an, möglichst viele relevante Dokumente in die engere Auswahl zu holen. Was in dieser ersten Runde nicht gefunden wird, kann auch von nachgelagerten Ranking-Modellen nicht mehr berücksichtigt werden.
Alle vier Modelle sind auf Hugging Face unter der MIT-Lizenz verfügbar und können über die Perplexity-API sowie gängige Inference-Frameworks wie Transformers, SentenceTransformers und ONNX genutzt werden. Einen technischen Bericht mit vollständigen Evaluierungsergebnissen hat das Unternehmen ebenfalls veröffentlicht.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.