Sprachmodelle nutzen eine "probabilistische Version echten Schlussfolgerns"
Eine neue Studie zeigt, dass die Leistung von Sprachmodellen bei Chain-of-Thought Prompts von Wahrscheinlichkeit, Auswendiglernen und verrauschtem Schlussfolgern beeinflusst wird.
Ein Forschungsteam der Princeton University und der Yale University hat untersucht, welche Faktoren die Leistung von Large Language Models (LLMs) bei der Lösung von Aufgaben mit Chain-of-Thought (CoT) Prompts beeinflussen. CoT Prompts regen LLMs dazu an, eine Abfolge von Zwischenschritten zu generieren, bevor sie die endgültige Antwort ausgeben und sind ein zentraler Bestandteil von OpenAIs neuestem o1-Modell.
Die Forschenden führten eine detaillierte Fallstudie zur symbolischen Denkaufgabe der Entschlüsselung von Verschiebechiffren durch. Bei einer Verschiebechiffre wird jeder Buchstabe des Originaltextes um eine bestimmte Anzahl von Stellen im Alphabet verschoben. Beispielsweise bedeutet ROT-13, dass jeder Buchstabe um 13 Stellen nach vorne verschoben wird: Aus A wird N, aus B wird O, und so weiter. Aus dem Originaltext "HALLO" würde so der verschlüsselte Text "UNYYB". Die Aufgabe des Modells besteht darin, diesen verschlüsselten Text wieder zu entschlüsseln, um den Originaltext zu rekonstruieren.
Durch die Konzentration auf eine einzige, relativ einfache Aufgabe konnten sie drei Faktoren identifizieren, die die CoT-Leistung systematisch beeinflussen:
1. Wahrscheinlichkeit (probability): Die Wahrscheinlichkeit des erwarteten Aufgabenergebnisses
2. Auswendiglernen (memorization): Was das Modell während des Pre-Trainings implizit gelernt hat
3. Verrauschtes Schlussfolgern (noisy reasoning): Die Anzahl der an der Schlussfolgerung beteiligten Zwischenschritte
Die Forschenden zeigten, dass diese Faktoren die Genauigkeit bei allen drei untersuchten LLMs - GPT-4, Claude 3 und Llama 3.1 - drastisch beeinflussen können.
Einfaches probabilistisches Modell bildet CoT-Leistung ab
Um ihre Beobachtungen zu überprüfen, verwendeten die Forschenden ein statistisches Verfahren namens logistische Regression. Damit untersuchten sie, wie verschiedene Faktoren die Wahrscheinlichkeit beeinflussen, dass GPT-4 bei einem Beispiel die richtige Antwort gibt.
Sie betrachteten folgende Faktoren:
- Wie wahrscheinlich ist der verschlüsselte Eingabetext?
- Wie wahrscheinlich ist der korrekte entschlüsselte Text? Dieser Faktor soll zeigen, ob die Wahrscheinlichkeit des Ergebnisses eine Rolle spielt.
- Wie häufig kommt die jeweilige Verschiebung (z.B. ROT-13) in echten Texten vor? Je häufiger, desto besser könnte das Modell sie beim Training auswendig gelernt haben.
- Wie viele Schritte sind mindestens nötig, um jeden Buchstaben zu entschlüsseln? Das ist ein Maß für die Schwierigkeit der Aufgabe.
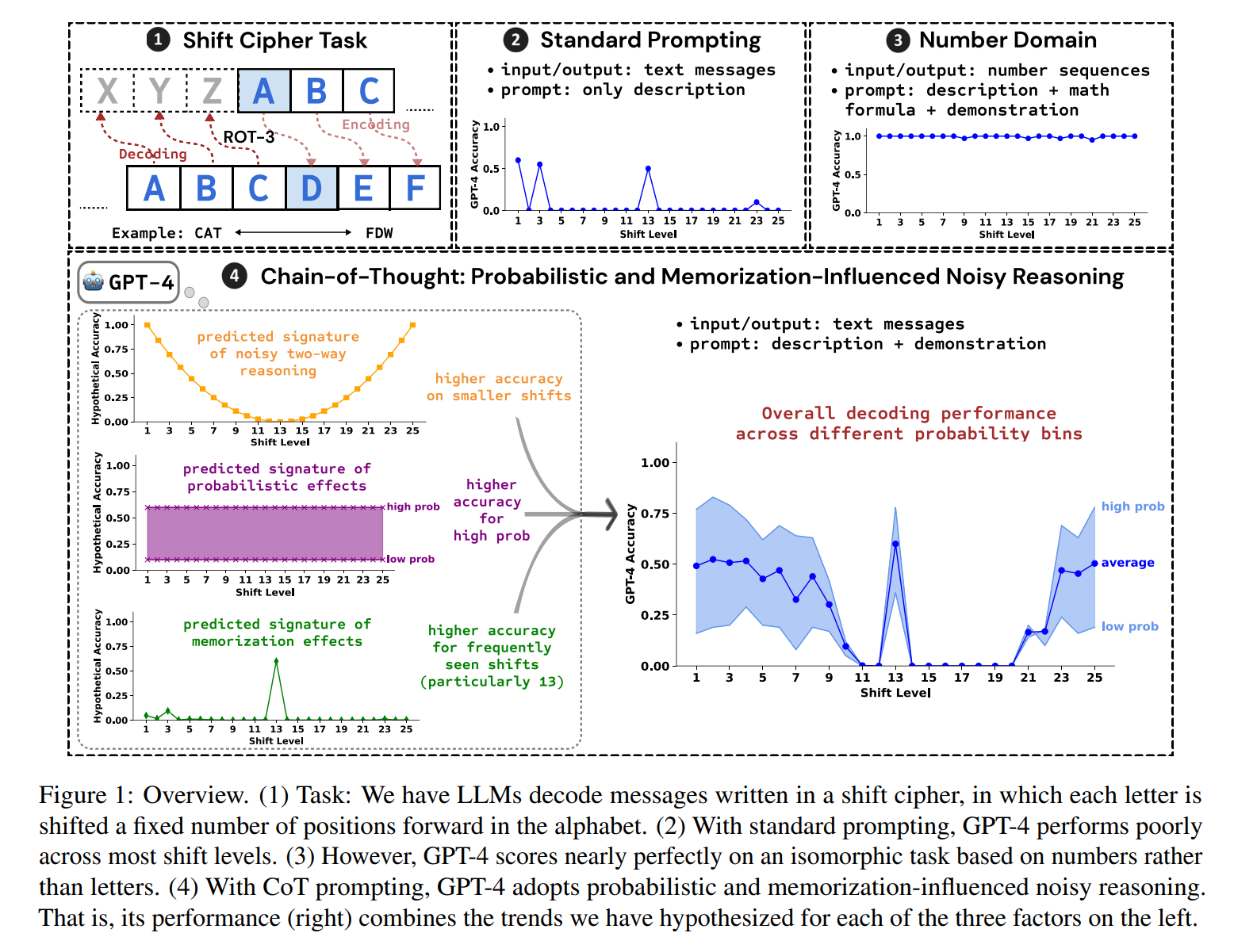
Das Ergebnis: Die Wahrscheinlichkeit des entschlüsselten Textes, die Häufigkeit der Verschiebung und die Anzahl der nötigen Schritte hatten alle einen statistisch bedeutsamen Einfluss auf die Leistung von GPT-4. Laut des Teams stützt das die Vermutung, dass GPT-4 beim Schlussfolgern sowohl Wahrscheinlichkeiten als auch Auswendiggelerntes und eine Art "verrauschte Logik" verwendet. Die Modelle zeigen also Anzeichen von Auswendiglernen, können das Gelernte aber auch auf neue Fälle übertragen.
Besonders interessant ist, dass GPT-4 beim Schlussfolgern offenbar zwei Strategien kombiniert: Es kann die Buchstaben entweder vorwärts oder rückwärts verschieben, je nachdem, was weniger Schritte erfordert. Das führt zwar insgesamt zu guten Ergebnissen, trägt aber auch zum "Rauschen" bei, das die Genauigkeit mit zunehmender Verschiebung sinken lässt.
Außerdem zeigte sich, dass die Zwischenschritte, die GPT-4 in seiner Gedankenkette generiert, entscheidend für die Leistung sind. Sie liefern wichtigen Kontext, auf den sich das Modell beim Erzeugen der Endergebnisse stützt. Allein die Anweisung, "leise nachzudenken", bringt wenig - die Überlegungen müssen explizit als Text ausgegeben werden.
Überraschenderweise spielte es kaum eine Rolle, ob die Gedankenkette im Beispiel-Prompt fehlerfrei war oder nicht. GPT-4 scheint vor allem das Format zu übernehmen, um selbst eine korrekte Kette zu erzeugen. Die inhaltliche Korrektheit der Beispielkette ist weniger wichtig.
Insgesamt kommen die Forschenden zu dem Schluss, dass die Leistung bei CoT Prompts sowohl Auswendiglernen als auch eine probabilistische Version von echtem Schlussfolgern widerspiegelt. Mit "probabilistischer Version von echtem Schlussfolgern" meinen sie, dass das Modell zwar in der Lage ist, logische Schlussfolgerungen zu ziehen, dabei aber auch von Wahrscheinlichkeiten beeinflusst wird. Es handelt sich also nicht um rein symbolisches Schlussfolgern.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.