Probe3D: Studie untersucht, wie gut KI-Modelle die dritte Dimension verstehen

Eine neue Studie untersucht, ob und wie gut multimodale KI-Modelle die 3D-Struktur von Szenen und Objekten verstehen.
Forscher der University of Michigan und von Google Research haben das "3D-Bewusstsein" multimodaler Modelle untersucht. Ziel war es, zu verstehen, wie gut die von diesen Modellen erlernten Darstellungen die 3D-Struktur unserer Welt erfassen.
Dem Team zufolge kann das 3D-Bewusstsein anhand von zwei Schlüsselfähigkeiten gemessen werden: Können die Modelle die sichtbare 3D-Oberfläche aus einem einzelnen Bild rekonstruieren, also Tiefen- und Oberflächeninformationen ableiten? Sind die Darstellungen über mehrere Blickwinkel auf dasselbe Objekt oder dieselbe Szene hinweg konsistent?
Die Ergebnisse zeigen, dass die Modelle teilweise in der Lage sind, Tiefen- und Oberflächeninformationen zu kodieren, ohne explizit darauf trainiert worden zu sein. Insbesondere die selbstüberwachenden Modelle DINO und DINOv2 sowie das textgetriebene Diffusionsmodell StableDiffusion schnitten hier gut ab. Eine Ausnahme bildeten Modelle, die mit Vision-Language-Pretraining wie CLIP trainiert wurden. Diese erfassten kaum 3D-Informationen.
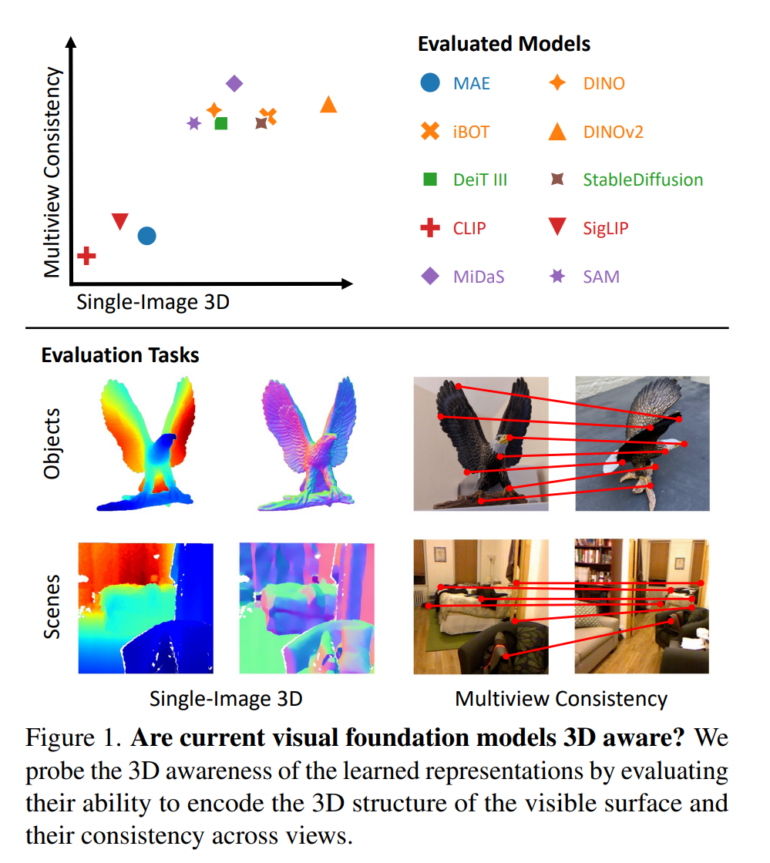
Multimodale Modelle lernen wohl keine echten 3D-konsistente Repräsentationen
Hinsichtlich der Konsistenz über mehrere Blickwinkel zeigten alle getesteten Modelle Schwächen. Während sie bei kleinen Blickwinkeländerungen noch genaue Zuordnungen zwischen Bildregionen herstellen konnten, brach die Leistung bei größeren Blickwinkeländerungen stark ein.
Die Forscher kommen zu dem Schluss, dass die untersuchten Modelle eher blickwinkelabhängige (2.5D) als echte 3D-konsistente Repräsentationen lernen - was generell die Frage aufwirft, ob mit Bildern trainierte generative KI 3D-Strukturen lernen kann oder nicht. Die Forscher hoffen, dass ihre Ergebnisse mehr Interesse an diesem Thema wecken, insbesondere angesichts der beeindruckenden Fortschritte bei der fotorealistischen Bild- und Videosynthese durch generative KI-Modelle wie OpenAIs Sora. Denn zum 3D-Verständnis gehört auch die Fähigkeit, Schlussfolgerungen über räumliche Beziehungen zu ziehen und Vorhersagen über Verformung und Dynamik zu treffen - ob Sora diese Fähigkeiten besitzt, muss in einer zukünftigen Arbeit untersucht werden.
Der Code und Ergebnisse sind auf GitHub verfügbar.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.