Qualcomm will Reasoning-KI auf Smartphones bringen
Kurz & Knapp
- Qualcomm AI Research hat ein modulares System entwickelt, das Reasoning-fähige Sprachmodelle direkt auf Smartphones bringen soll, ohne auf die Cloud angewiesen zu sein.
- Die wortreichen Denkprozesse solcher Modelle verbrauchen zu viel Speicher und Energie. Per Reinforcement Learning werden die Antworten massiv gekürzt, ohne dass die Genauigkeit spürbar leidet.
- Bislang bleibt lokale KI auf Smartphones aber vor allem eine technische Demo. Für echte Systemintegration mit Zugriff auf Mails, Fotos oder Kalender setzen Anbieter wie Google weiterhin auf Cloud-Modelle.
Qualcomm AI Research hat ein modulares System entwickelt, das Reasoning-fähige Sprachmodelle auf Smartphones bringen soll. Dafür werden die wortreichen Denkprozesse der Modelle um den Faktor 2,4 komprimiert.
Die langen Denkprotokolle aktueller Reasoning-Modelle sind auf mobilen Geräten ein grundsätzliches Problem: Sie erzeugen Unmengen an Tokens, blähen den Speicherbedarf auf und treiben den Energieverbrauch in die Höhe. Das neue Framework soll diese Modelle trotzdem auf Smartphones lauffähig machen.
Die Anwendungsfälle, die das Unternehmen im Blick hat, reichen laut dem Paper von intelligenten persönlichen Assistenten, die mehrstufige Aufgaben planen und eigenständig über Apps hinweg agieren, bis hin zur direkten Interaktion mit Geräte-Oberflächen und externen Diensten. Hinzu kommen strukturelle Vorteile: sensible Daten bleiben auf dem Gerät, die Latenz sinkt, und das System funktioniert auch ohne Internetverbindung.
Ein Basismodell, zwei Modi
Statt ein komplett neues Modell zu trainieren, setzt Qualcomm auf einen modularen Ansatz. Ausgangspunkt ist ein normales Sprachmodell ohne Reasoning-Fähigkeiten (Qwen2.5-7B-Instruct). Dieses wird über sogenannte LoRA-Adapter erweitert: kleine, spezialisierte Zusatzmodule, die bei Bedarf aktiviert oder deaktiviert werden können. Dasselbe Modell kann so wahlweise als schneller Chatbot oder als Reasoning-System arbeiten.
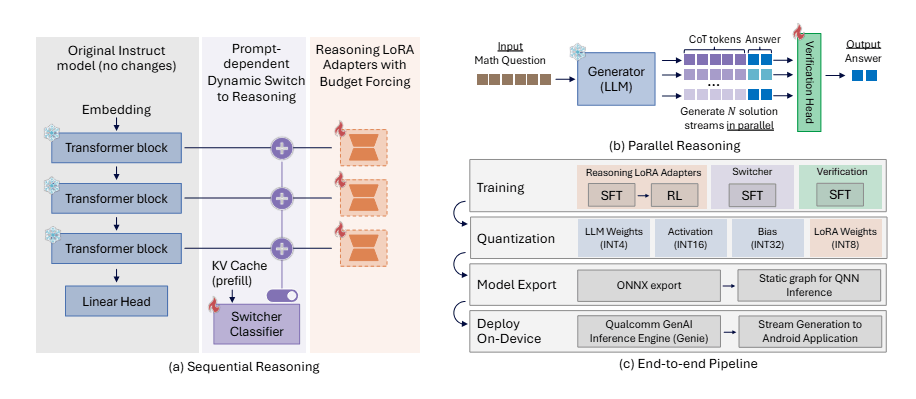
Laut den Forschern müssen dafür nur rund 4 Prozent der Parameter trainiert werden. Trotzdem erreicht das Ergebnis annähernd die Leistung von DeepSeek-R1-Distill-Qwen-7B, einem Modell, das mit deutlich höherem Aufwand trainiert wurde. Ein integrierter Klassifikator entscheidet automatisch für jede Anfrage, ob das aufwändigere Reasoning überhaupt nötig ist, und spart so bei einfachen Fragen Rechenzeit und Energie.
Gezielte Textkompression per Reinforcement Learning
Das größte Problem nach dem initialen Training: Die Modelle werden extrem wortreich. Sie finden oft früh die richtige Lösung, verbringen dann aber Tausende von Tokens damit, ihr eigenes Ergebnis auf verschiedene Arten zu überprüfen. Die Forscher bezeichnen dieses Phänomen als "epistemic hesitation". In vorheriger Forschung ist die übergeordnete Problematik schon länger als "Overthinking" bekannt.
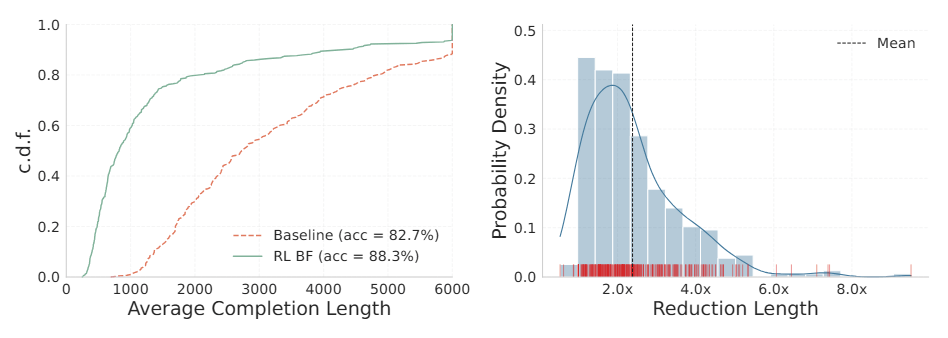
Dagegen setzt das Team Reinforcement Learning ein, das überlange Antworten gezielt bestraft. Die Antworten werden im Schnitt um den Faktor 2,4 kürzer, bei einzelnen Aufgaben sogar um den Faktor 8. Ein Beispiel aus dem Paper: Eine algebraische Vereinfachungsaufgabe, für die das Ausgangsmodell 3.118 Tokens benötigt, löst das optimierte Modell in 810 Tokens. Die Genauigkeit bleibt dabei laut den Forschern weitgehend erhalten.

Ein erster Ansatz für die Längenbeschränkung scheiterte allerdings: Das Modell lernte, seinen Denkblock formal abzuschließen und die ausschweifenden Überlegungen im regulären Antwortteil fortzusetzen. Erst eine angepasste Belohnungsfunktion, die die gesamte Antwortlänge berücksichtigt, unterband dieses Verhalten.
Parallele Lösungswege und 4-Bit-Kompression
Zusätzlich lässt das Framework das Modell mehrere Lösungswege parallel verfolgen. Ein kleiner Bewertungskopf auf dem Basismodell schätzt ein, welche Antwort am wahrscheinlichsten korrekt ist. Bei acht parallelen Durchläufen steigt die Genauigkeit auf dem Mathe-Benchmark MATH500 laut dem Paper um rund 10 Prozent, ohne die Antwortzeit wesentlich zu verlängern. Der Grund: Die Token-Generierung auf Mobilgeräten ist ohnehin durch den Speicherzugriff begrenzt, nicht durch die Rechenleistung. Die parallelen Pfade nutzen so vorhandene, aber brachliegende Kapazitäten.
Für die eigentliche Smartphone-Tauglichkeit komprimiert Qualcomm die Modellgewichte auf 4 Bit. Die Reasoning-Adapter müssen dabei direkt auf dem komprimierten Modell trainiert werden, andernfalls produziert das System laut dem Paper nur Zufallstext. Das finale Modell liegt den Ergebnissen zufolge nur rund 2 Prozent unter der Genauigkeit der unkomprimierten Variante. Videos auf der Projektseite zeigen das System im Betrieb auf Mobilgeräten.
Lokale KI auf dem Smartphone bleibt bislang eine Demo
Qualcomm arbeitet bereits seit Jahren daran, KI-Modelle auf mobile Geräte zu bringen. Das Unternehmen hat unter anderem 80 voroptimierte KI-Modelle für Snapdragon-Geräte veröffentlicht und einen KI-Orchestrator vorgestellt, der als Vermittler zwischen persönlichen Daten, Apps und KI-Modellen auf dem Gerät fungieren soll. Auch Google zeigte mit FunctionGemma und der AI Edge Gallery, wie sich kleine Sprachmodelle lokal auf Android-Geräten einsetzen lassen.
Bislang blieb es bei solchen Demos allerdings weitgehend bei technischen Machbarkeitsnachweisen. Für die tiefe Systemintegration, bei der ein KI-Assistent auf E-Mails, Fotos und Kalender zugreift, setzen Anbieter wie Google stattdessen auf Cloud-Modelle: Die kürzlich vorgestellte Funktion "Personal Intelligence" verbindet Gemini mit Gmail, Google Fotos und der Suche, läuft aber serverseitig.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnieren