Qwen-Image-2.0 beherrscht präzises Text-Rendering und komplexe chinesische Kalligraphie

Kurz & Knapp
- Alibabas Qwen-Team hat mit Qwen-Image-2.0 ein 7-Milliarden-Parameter-Modell vorgestellt, das Bildgenerierung und Bildbearbeitung in einem einzigen, deutlich kleineren Modell vereint.
- Besonders stark ist das präzise Text-Rendering: Das Modell kann Infografiken, Poster oder Comics mit korrekter Typografie auf verschiedenen Oberflächen und in komplexen chinesischen Kalligraphie-Stilen erzeugen.
- Offene Modellgewichte gibt es bisher nicht, die Community rechnet aber mit einer baldigen Veröffentlichung. Die kompakte Größe macht das Modell besonders für den lokalen Betrieb auf Consumer-Hardware interessant.
Alibabas Qwen-Team hat mit Qwen-Image-2.0 ein kompaktes Bildmodell vorgestellt, das Bilder erzeugen und bearbeiten kann. Besondere Fähigkeiten zeigt es zudem bei präzisem Text-Rendering.
Das Qwen-Team von Alibaba hat Qwen-Image-2.0 veröffentlicht. Das Modell soll mit 7 Milliarden Parametern und nativer 2K-Auflösung (2048 × 2048) sowohl Bilder aus Textbeschreibungen erzeugen als auch bestehende Bilder bearbeiten können. Bisher brauchte es bei Alibaba dafür zwei separate Modelle; der Vorgänger kam zudem noch auf 20 Milliarden Parameter. Das Modell auf ein Drittel der Größe zu schrumpfen, sei laut dem Qwen-Team das Ergebnis einer monatelangen Zusammenführung der zuvor getrennten Entwicklungspfade.
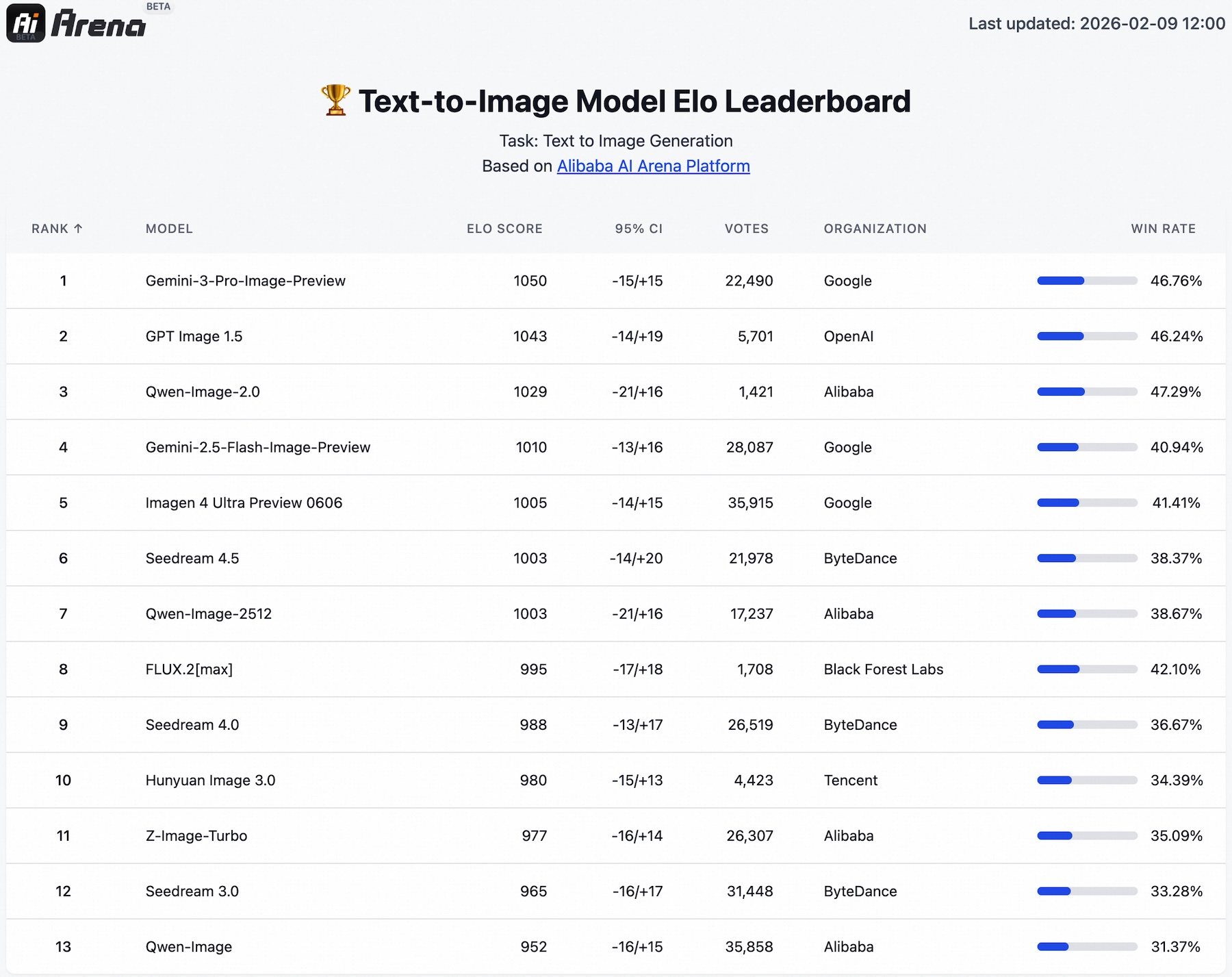
Bei Blindtests auf einer hauseigenen Arena-Plattform soll das Modell laut Alibaba sowohl bei Text-zu-Bild- als auch bei Bild-zu-Bild-Aufgaben überlegen abschneiden, obwohl es als vereintes Modell gegen spezialisierte Systeme antritt, und landet in einer Rangliste knapp hinter den OpenAIs und Googles aktuelle Modelle GPT-Image-1.5 und Nano Banana Pro. Im Vergleich der Bildbearbeitungsmodelle klettert Qwen-Image-2.0 auf Platz zwei zwischen Nano Banana Pro und Seedream 4.5 von Bytedance.
Beinahe perfekte Schriftdarstellung
Die wohl auffälligste Fähigkeit von Qwen-Image-2.0 dürfte das Rendern von Text innerhalb generierter Bilder sein. Das Qwen-Team beschreibt fünf Kerneigenschaften: Präzision, Komplexität, Ästhetik, Realismus und Ausrichtung.
Das Modell unterstützt Prompts von bis zu 1000 Token. Damit ließen sich laut dem Qwen-Team direkt Infografiken, Präsentationsfolien, Poster und sogar mehrseitige Comics generieren. In einem Beispiel erzeugt das Modell eine Powerpoint-Folie mit einer Timeline, die sämtlichen Text korrekt darstellt und eingebettete Bilder innerhalb der Folie rendert, eine Art "Bild-im-Bild"-Komposition.

Besonders ambitioniert wirken die Kalligraphie-Demonstrationen: Qwen-Image-2.0 soll verschiedene chinesische Schriftstile beherrschen, darunter die "Schlankes-Gold-Schrift" von Kaiser Huizong der Song-Dynastie und Standard-Schreibschrift. In einem Beispiel rendert das Modell nach Angaben des Teams nahezu den gesamten Text des "Vorworts zum Orchideen-Pavillon" in Standard-Schreibschrift, mit nur wenigen fehlerhaften Zeichen.

Das Modell soll zudem Text auf unterschiedlichen Oberflächen korrekt darstellen können: auf Glas-Whiteboards, Kleidung und Zeitschriftencovern, jeweils mit passender Beleuchtung, Reflexion und Perspektive. Ein Filmplakat-Beispiel soll zeigen, wie fotorealistische Szenen und dicht gesetzte Typografie in einem einzigen Bild zusammenspielen.
Bildbearbeitung profitiert vom vereinten Ansatz
Jenseits der Textfähigkeiten soll Qwen-Image-2.0 auch bei rein visuellen Aufgaben zulegen. Das Qwen-Team zeigt unter anderem eine Waldszene, in der das Modell über 23 verschiedene Grüntöne mit unterschiedlichen Texturen differenziere, von wachsartigen Blattoberflächen bis zu samtigen Moospolstern.

Weil Generierung und Bearbeitung im selben Modell stattfinden, sollen Fortschritte auf der Generierungsseite direkt auf die Bearbeitungsqualität durchschlagen. Das Modell könne Gedichte auf bestehende Fotos schreiben, aus einem einzelnen Porträt ein Neun-Raster mit verschiedenen Posen erzeugen oder Personen aus zwei verschiedenen Fotos zu einem natürlich wirkenden Gruppenbild zusammenführen. Auch dimensionsübergreifende Bearbeitung sei möglich, etwa das Einfügen von Cartoon-Figuren in reale Stadtfotos.


Noch kein Open Source, aber die Community rechnet damit
Derzeit ist Qwen-Image-2.0 nur über eine API auf Alibaba Cloud im Rahmen einer Einladungs-Beta sowie als kostenlose Demo auf Qwen Chat verfügbar. Offene Modellgewichte gibt es bislang nicht.
In der LocalLLaMA-Community auf Reddit wird das Modell dennoch mit Interesse aufgenommen. Die 7B-Größe sei besonders relevant für Nutzer, die Modelle lokal auf Consumer-Hardware ausführen wollen. Dass die Gewichte vorerst geschlossen bleiben, überrascht die Community offenbar wenig. Bei der ersten Version von Qwen-Image seien die Gewichte etwa einen Monat nach dem Launch unter der Apache-2.0-Lizenz veröffentlicht worden. Viele Nutzer rechnen mit einem ähnlichen Verlauf. Auch ein Paper zur Architektur steht bislang noch aus.
Qwen-Image-2.0 reiht sich in einen Trend unter chinesischen Bildmodellen ein, die verstärkt auf präzise Textdarstellung setzen. Im Dezember hatte Meituan mit dem 6-Milliarden-Parameter-Modell LongCat-Image vorgelegt, im Januar folgte Zhipu AI mit GLM-Image und 16 Milliarden Parametern unter MIT-Lizenz.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnieren