Qwen3-VL analysiert zweistündige Videos und findet fast jedes Detail

Wenige Monate nach der Veröffentlichung legt Alibaba nun den detaillierten technischen Bericht zu Qwen3-VL vor. Das offene, multimodale KI-Modell zeigt in Tests überlegene Leistungen bei mathematischen Aufgaben mit Bildern und kann stundenlange Videos analysieren.
Das System kann gleichzeitig riesige Datenmengen verarbeiten, etwa zweistündige Videos oder hunderte Dokumentenseiten mit insgesamt bis zu 256.000 Token Kontextlänge.
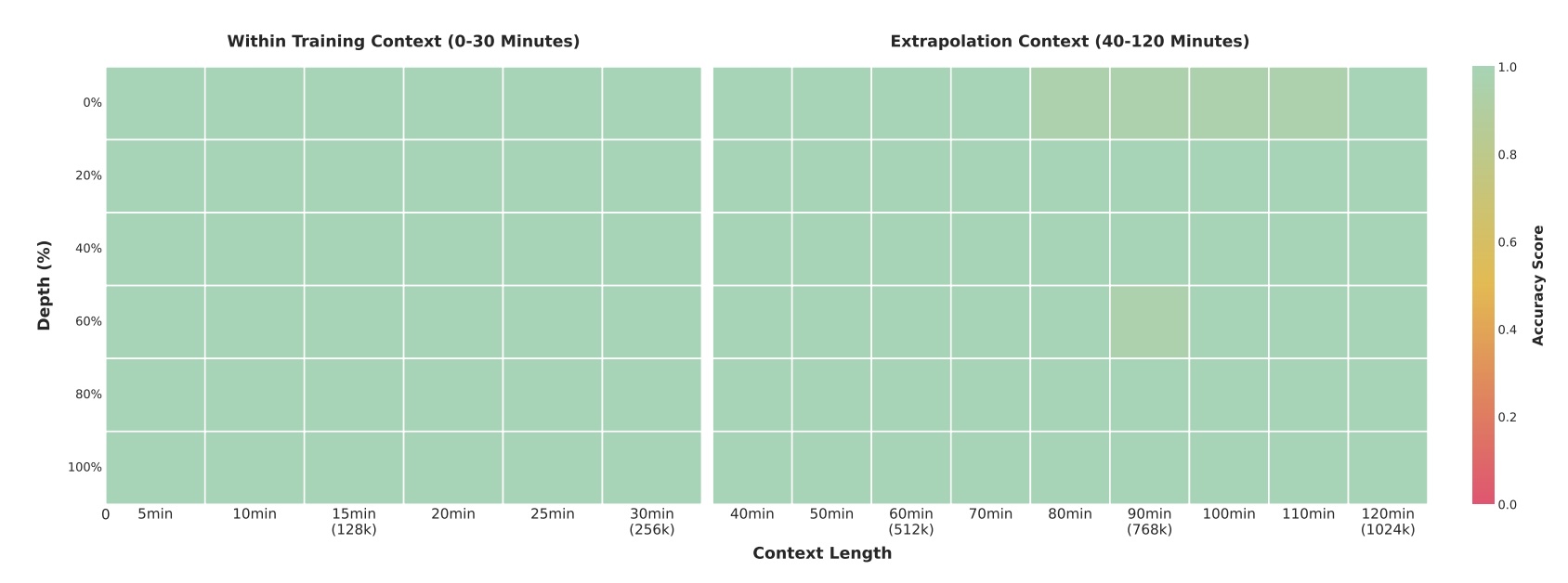
Im sogenannten Needle-in-a-Haystack-Test kann das Flaggschiffmodell mit 235 Milliarden Parametern in 30-minütigen Videos einzelne relevante Frames mit 100-prozentiger Genauigkeit wiederfinden. Selbst bei zweistündigen Videos mit etwa einer Million Token bleibt die Treffsicherheit bei 99,5 Prozent. Dabei wird ein semantisch wichtiger "Needle"-Frame an verschiedenen Positionen in lange Videos eingefügt, den das System dann lokalisieren und analysieren muss.
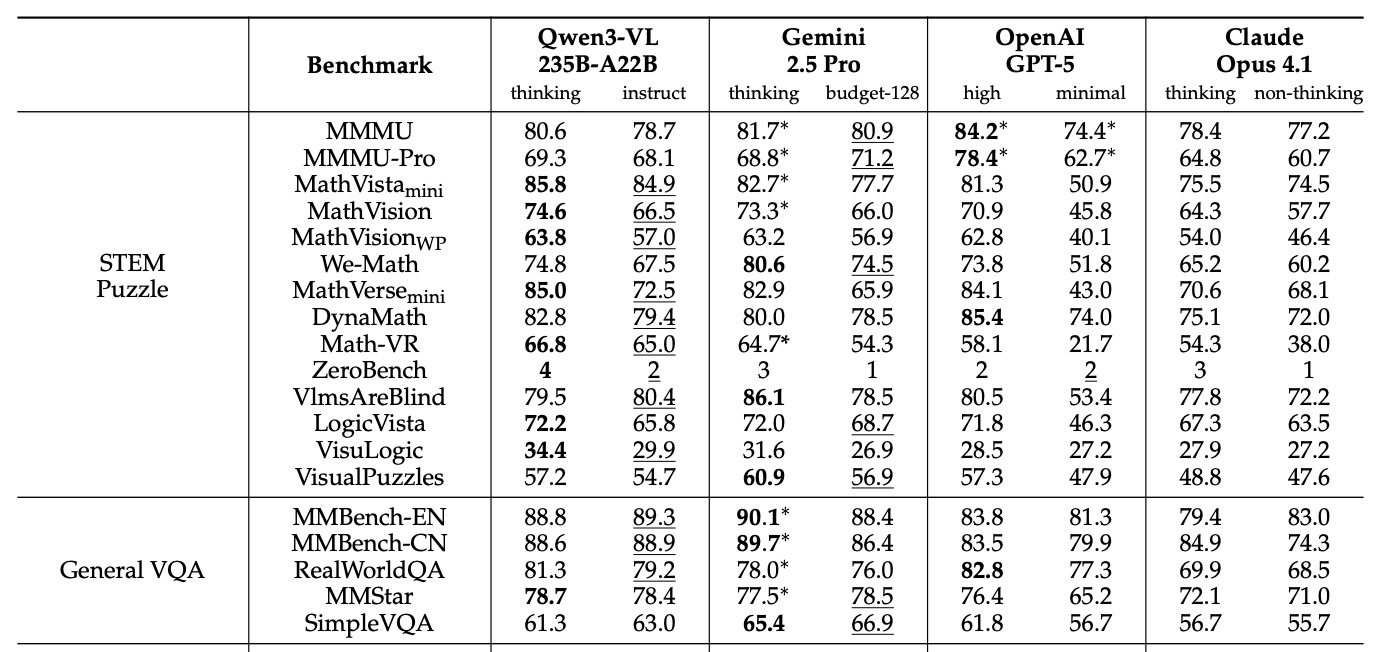
In vielen der veröffentlichten Tests zeigt Qwen3-VL-235B-A22B die beste Leistung im Vergleich mit Gemini 2.5 Pro, OpenAI GPT-5 und Claude Opus 4.1, auch bei aktiviertem Reasoning oder hohen Thinking-Budgets. Bei mathematischen Aufgaben mit visuellen Elementen übertrifft Qwen3-VL etablierte Konkurrenten deutlich. Auf MathVista erreicht es 85,8 Prozent gegenüber GPT-5s 81,3 Prozent. Bei MathVision führt es mit 74,6 Prozent vor Gemini-2.5-Pro mit 73,3 Prozent und GPT-5 mit 65,8 Prozent.
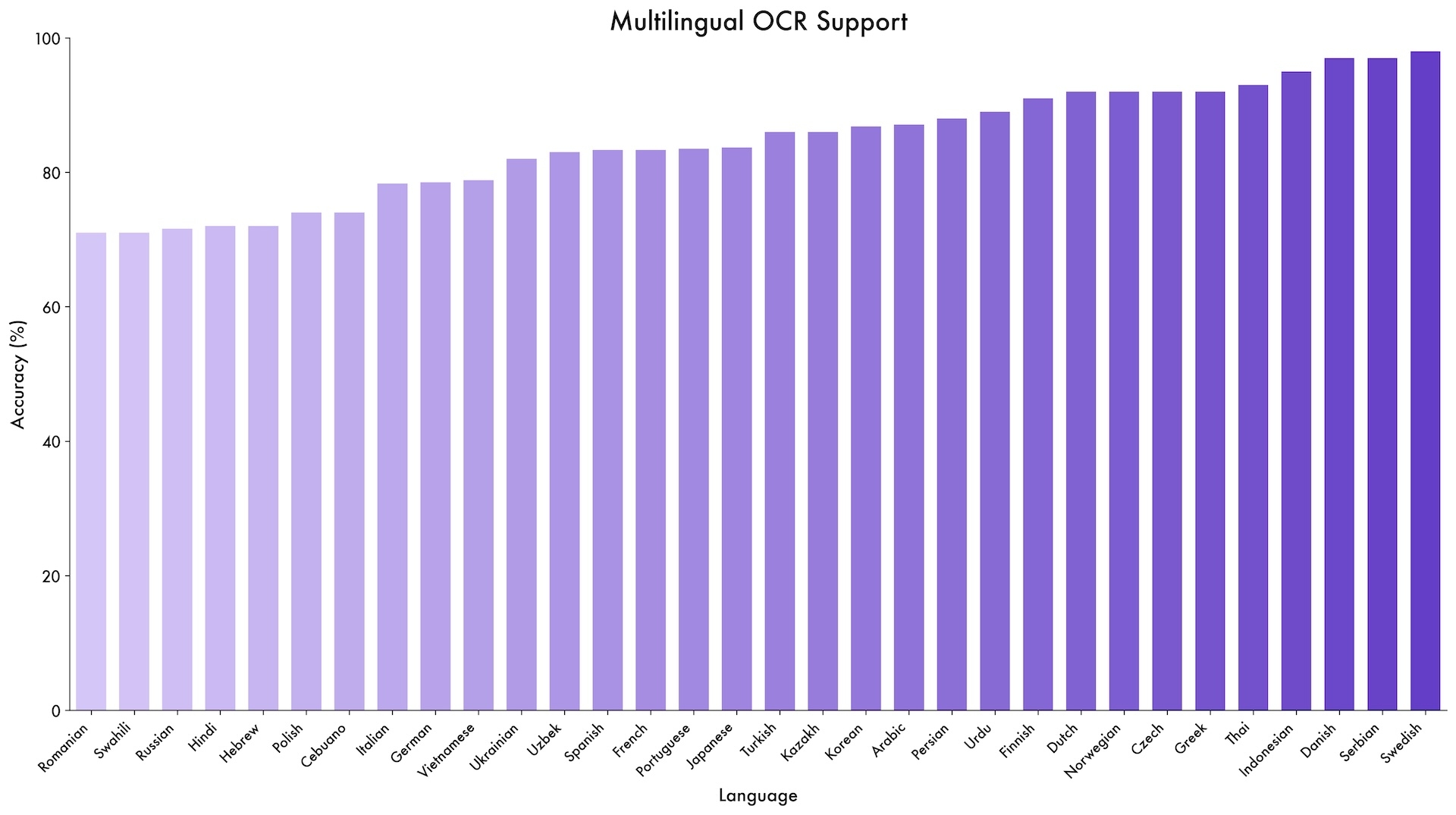
Das Modell zeigt seine Vielseitigkeit in verschiedenen spezialisierten Benchmarks. Bei DocVQA, einem Test für Dokumentenverständnis, erreicht es 96,5 Prozent Genauigkeit. Auf OCRBench erzielt es 875 Punkte und unterstützt dabei OCR-Aufgaben in 39 Sprachen - fast eine Vervierfachung gegenüber Qwen2.5-VLs zehn Sprachen.
Eine neue Fähigkeit demonstriert das System bei GUI-Agent-Aufgaben. Auf ScreenSpot Pro, einem Test für die Navigation in grafischen Benutzeroberflächen, erreicht es 61,8 Prozent Genauigkeit. Bei AndroidWorld, wo das System selbstständig Android-Apps bedienen muss, erzielt Qwen3-VL-32B 63,7 Prozent.
Das Modell kann auch komplexe, mehrseitige PDF-Dokumente verstehen. Auf MMLongBench-Doc, einem Test für lange Dokumentenanalyse, erreicht es 56,2 Prozent Genauigkeit. Bei der CharXiv-Benchmark für wissenschaftliche Charts erzielt es 90,5 Prozent bei Beschreibungsaufgaben und 66,2 Prozent bei komplexeren Reasoning-Fragen.
Im direkten Vergleich mit Gemini-2.5-Pro, GPT-5 und Claude-Opus-4.1 zeigt sich jedoch ein differenziertes Bild. Bei MMMU-Pro, einem anspruchsvollen Multi-Disziplin-Test, liegt Qwen3-VL jedoch mit 69,3 Prozent hinter den 78,4 Prozent von GPT-5 zurück. Auch bei den meisten Benchmarks zur Fragebeantwortung in Videos haben die kommerziellen Konkurrenten die Nase vorn. Die Ergebnisse zeigen, dass Qwen3-VL besonders bei visuell-mathematischen Aufgaben und Dokumentenverständnis stark ist, bei allgemeinem Reasoning aber noch Aufholbedarf hat.
Drei technische Durchbrüche für multimodale Verarbeitung
Der Technical Report beschreibt drei zentrale architektonische Verbesserungen. Erstens ersetzt das enhanced Interleaved-MRoPE das ursprüngliche MRoPE aus Qwen2-VL. MRoPE (Multimodal Rotary Position Embedding) ist ein Verfahren, mit dem KI-Modelle die Position von Elementen in Bildern und Videos verstehen.
Das ursprüngliche MRoPE teilte die mathematischen Repräsentationen in separate Gruppen auf: eine für die zeitliche Dimension, eine für horizontale und eine für vertikale Positionen. Das neue Interleaved-MRoPE verteilt diese drei Dimensionen gleichmäßig über alle verfügbaren mathematischen Bereiche, statt getrennte Blöcke zu bilden. Das soll besonders bei langen Videos die Leistung verbessern.
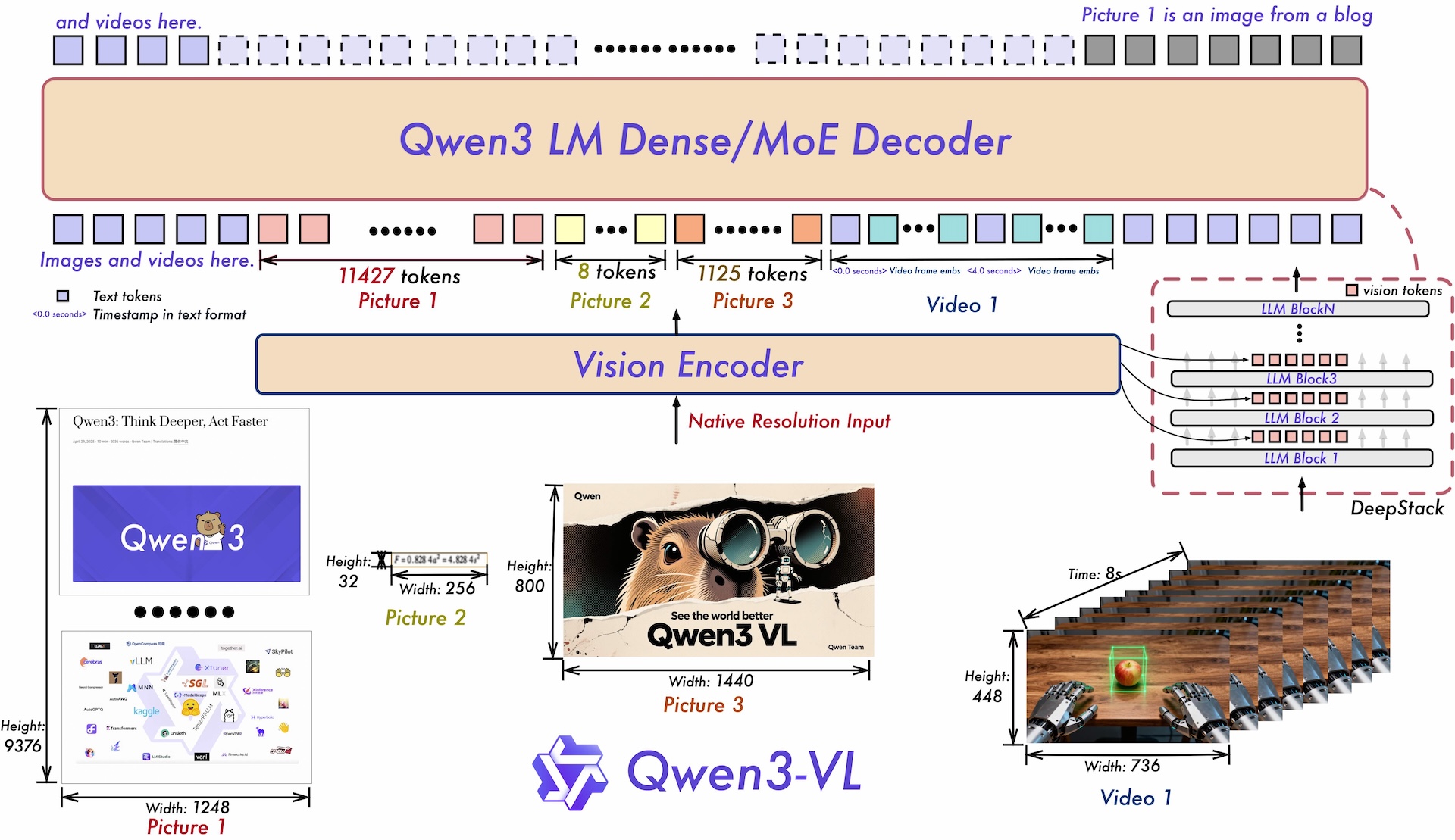
Zweitens nutzt die DeepStack-Technologie nicht nur das finale Ergebnis der Bilderkennung, sondern greift auch auf Zwischenergebnisse aus verschiedenen Ebenen des SigLIP-2 Vision Encoders zu. Diese enthalten unterschiedlich detaillierte visuelle Informationen.
Drittens ersetzt eine textbasierte Zeitstempel-Ausrichtung die komplexe T-RoPE-Methode aus Qwen2.5-VL. Anstatt jedem Videoframe eine mathematische Zeitposition zuzuweisen, fügt das System einfache Textmarker wie "<3.8 seconds>" direkt in den Input ein. Das reduziert die Komplexität und verbessert das Verständnis für zeitbasierte Videoaufgaben.
Training mit einer Billion Token auf 10.000 GPUs
Das Training erfolgte in vier Phasen auf Alibaba-Servern mit bis zu 10.000 GPUs. Zunächst lernte das System, Bilder und Text miteinander zu verknüpfen, bevor das vollständige multimodale Training mit etwa einer Billion Token folgte. Die Trainingsdaten stammten aus verschiedenen Quellen: chinesische und englische Websites für Bild-Text-Paare, 3 Millionen PDFs aus Common Crawl, über 60 Millionen STEM-Aufgaben aus dem Bildungsbereich sowie Videos von Lehrplattformen bis zu YouTube-Material.
In den späteren Phasen erweiterte das System schrittweise seine Fähigkeit, längere Kontexte zu verarbeiten von 8000 über 32 000 bis zu 262 000 Token. Die "Thinking"-Varianten erhielten zusätzliches Training mit Chain-of-Thought-Daten, um ihre Denkschritte explizit zu durchlaufen und bei komplexen Problemen bessere Ergebnisse zu erzielen.
Apache 2.0 für breitere Nutzung
Alle seit September verfügbaren Qwen3-VL-Modelle stehen unter der Apache-2.0-Lizenz mit offenen Gewichten auf Hugging Face zur Verfügung. Die Modellreihe umfasst Dense-Varianten von 2B bis 32B Parametern sowie Mixture-of-Experts-Modelle mit 30B-A3B (30 Milliarden Parameter, 3 Milliarden aktiv) und 235B-A22B (235 Milliarden Parameter, 22 Milliarden aktiv pro Token).
Manche Fähigkeiten, etwa Frames aus stundenlangen Videos zu extrahieren, sind für ein multimodales Sprachmodell inzwischen nicht mehr sonderlich beeindruckend – Googles Modell Gemini 1.5 Pro war bereits Anfang 2024 dazu in der Lage. Qwen3-VL zeigt aber über viele Disziplinen hinweg ordentliche Ergebnisse, und ist im Gegensatz zu Googles Modell frei verfügbar. Das Vorgängermodell Qwen2.5-VL ist schon in vielen agentischen KI-Systemen anderer Forschungsarbeiten zu finden, weshalb Qwen3-VL durch seine Fortschritte die Entwicklung insgesamt weiter antreiben dürfte.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.