Das KI-Start-up Reka hat ein neues multimodales Sprachmodell namens Reka Core vorgestellt, das mit GPT-4 mithalten kann und neben Text und Bildern auch Video und Audio versteht.
Das KI-Start-up Reka hat ein neues multimodales Sprachmodell namens Reka Core vorgestellt. Laut Reka handelt es sich dabei um das bisher leistungsstärkste Modell des Unternehmens. Es wurde in nur wenigen Monaten von Grund auf neu entwickelt und hauptsächlich auf NVIDIA H100-GPUs mit einer Spitzenleistung von rund 2.500 H100- und 2.500 A100-GPUs trainiert.
Reka Core kann nicht nur Texte, sondern auch Bilder, Videos und Audiodateien verstehen und Text generieren. Damit ähnelt es dem kürzlich von Google vorgestellten Gemini 1.5 Pro. Im Gegensatz zu GPT-4 von OpenAI, das bisher neben Text nur Bilder verarbeiten kann, deckt Reka Core alle Modalitäten ab.
Video: Reka Core Demo
Benchmarks auf GPT-4- und Claude-3-Niveau
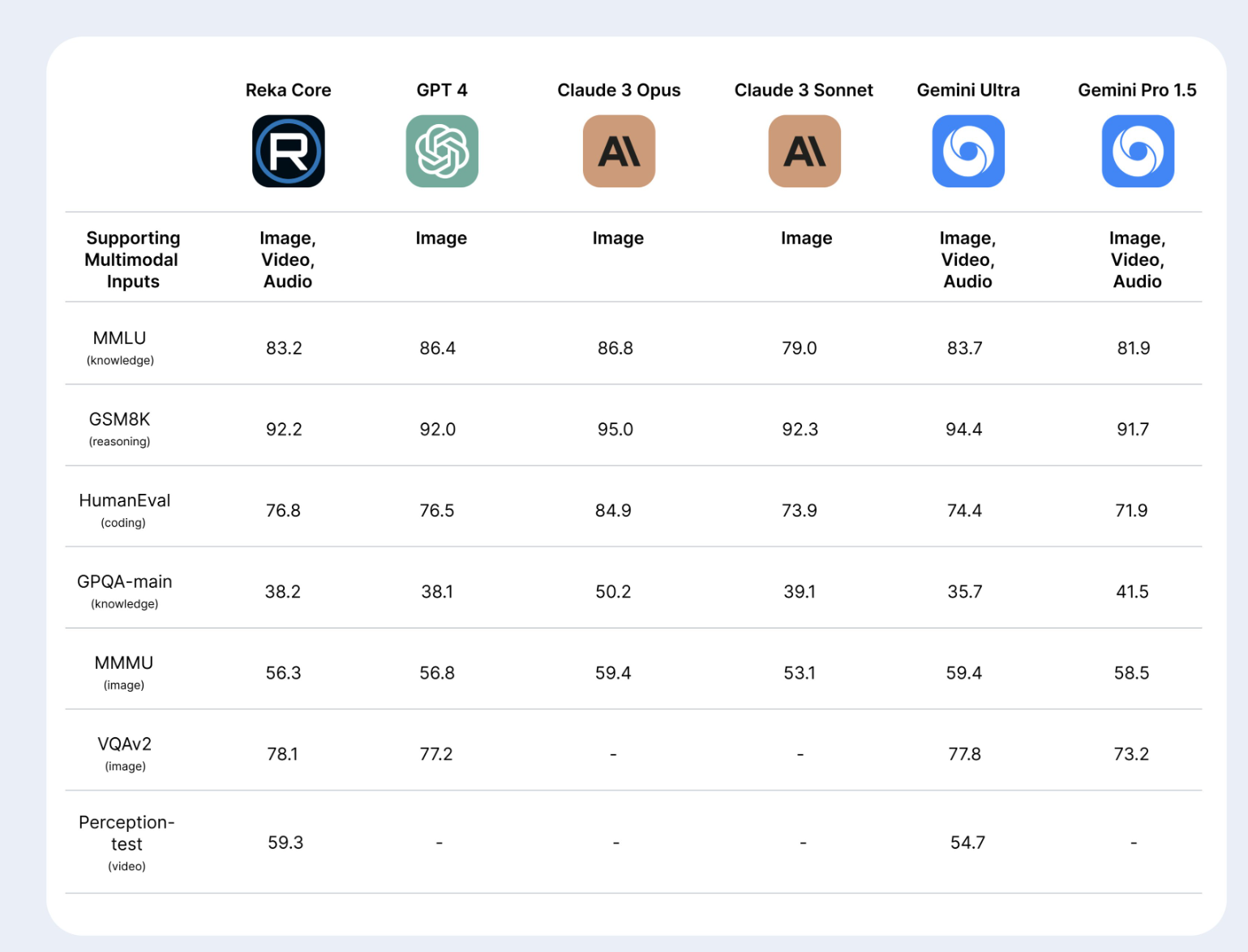
In ersten Benchmarks kann sich Reka Core mit führenden Modellen wie GPT-4, Claude 3 von Anthropic und Gemini Ultra von Google messen. Bei Aufgaben zum Bildverständnis wie MMMU erreicht Reka Core mit 56,3 Prozent fast die Leistung von GPT-4V (56,8 Prozent). Auch bei der Videoanalyse (Perception Test) übertrifft Reka Core mit 59,3 Prozent Gemini Ultra (54,7 Prozent).
Beim MMLU-Benchmark für allgemeines Sprachverständnis und Frage-Antwort-Aufgaben erreicht Reka Core eine Genauigkeit von 83,2 Prozent. Damit liegt es knapp hinter GPT-4 (86,4 Prozent), aber vor Modellen wie Claude 3 Sonnet (79 Prozent). Im Reasoning Benchmark GSM8K erreicht Reka Core 92,2 Prozent und liegt damit auf dem Niveau von GPT-4 (92 Prozent).
In einer verblindeten Evaluation durch eine unabhängige Drittfirma belegt Reka Core im multimodalen Chat den zweiten Platz knapp hinter GPT-4V und vor allen Claude-3-Modellen. Im reinen Text-Chat belegt Reka Core den dritten Platz hinter GPT-4 Turbo und Claude 3 Opus. Reka Core befindet sich noch in der Trainingsphase und das Start-up erwartet weitere Verbesserungen.
Neben dem Spitzenmodell Reka Core stellte das Start-up auch die kleineren Modelle Reka Flash und Reka Edge vor. Reka Flash übertrifft mit 21 Milliarden Parametern trotz seiner geringeren Größe viele deutlich größere Modelle wie GPT-3.5, Gemini Pro 1.0 oder Mistral in Benchmarks wie MMLU, HumanEval oder bei Bildverständnisaufgaben. Im MMLU-Benchmark erreicht Flash eine Genauigkeit von 75,9 Prozent und liegt damit vor Gemini Pro 1.0 (71,8 Prozent) und nahe an GPT-4 (86,4 Prozent).

Das noch kompaktere Reka Edge mit 7 Milliarden Parametern übertrifft sowohl Mistral-7B als auch Gemma-7B und Llama-7B deutlich in Benchmarks wie MMLU, GSM8K oder HumanEval. So erreicht Edge im MMLU eine Genauigkeit von 65,7 Prozent gegenüber 64,3 Prozent für Gemma-7B und 62,5 Prozent für Mistral-7B.

Laut Reka zeigen Flash und Edge, dass durch effizientes Training und Modellarchitekturen auch mit deutlich weniger Parametern Spitzenleistungen erzielt werden können. Das mache sie zu Alternativen für Anwendungen, bei denen die Modellgröße und die Inferenzkosten kritische Faktoren sind, zum Beispiel auf mobilen Endgeräten.
Effizienz durch skalierbare Architektur
Technisch basiert Reka Core auf einer modularen Encoder-Decoder-Transformer-Architektur. Das Modell wurde in mehreren Phasen mit verschiedenen Datenmischungen, Kontextlängen und Zielen vortrainiert.
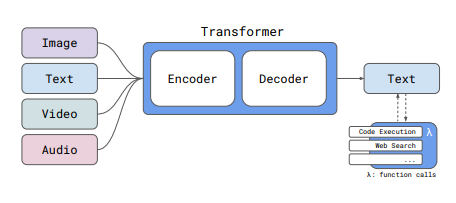
Reka Core verfügt über ein Kontextfenster von 128.000 Token für lange Dokumente. Insgesamt deckt das Training 32 Sprachen ab. Die Trainingsdaten von Reka Core sind eine Mischung aus öffentlich verfügbaren und lizenzierten, proprietären Datensätzen mit einem Wissensstand bis November 2023. Insgesamt wurden ca. 5 Billionen deduplizierte Text-Token verwendet.
Etwa 25 Prozent der Daten sind Code, 30 Prozent STEM und 25 Prozent Webdaten. Multilingual sind 15 Prozent der Daten, die 32 priorisierte Sprachen abdecken. Dazu kommt das gesamte Wikipedia-Korpus mit 110 Sprachen. Für Bild, Video und Audio wurden große multimodale Datensätze verwendet, die hinsichtlich Qualität, Vielfalt und Umfang optimiert wurden.
Showcase und API verfügbar
Beispielausgaben von Reka Core sind in einem öffentlichen Showcase zu sehen. Das Modell kann auch über eine Webplattform, API, lokal oder auf Endgeräten eingesetzt werden. Zu den ersten Partnern gehören Snowflake, Oracle und AI Singapore.
Preislich sortiert sich Reka mit dem teuersten Core-Modell deutlich hinter Claude 3 Opus und ungefähr auf dem Niveau von GPT-4 Turbo ein.
Reka Core:
- $10 / 1M Input-Token
- $25 / 1M Output-Token
Claude 3 Opus (von Anthropic):
- $15 / 1M Input-Token
- $75 / 1M Output-Token
GPT-4 Turbo (von OpenAI):
- $10 / 1M Input-Token
- $30 / 1M Output-Token (für das 128K Modell)
Reka ist ein KI-Start-up, das sich auf universelle Intelligenz, universelle multimodale und mehrsprachige Agenten, selbstverbessernde KI und Modelleffizienz konzentriert. Das Start-up wurde von Forschern von DeepMind, Google, Baidu und Meta gegründet und stellte sich im Sommer 2023 erstmals öffentlich vor.
Zuletzt hat Reka Yasa-1 entwickelt, einen multimodalen KI-Assistenten, der Text, Bilder, Video und Audio verstehen und damit interagieren kann. Reka hat seinen Hauptsitz in San Francisco und ein Büro in Großbritannien.
Personalisierung sticht Grundlagenmodelle
Reka Core zeigt auch, dass GPT-4 im April 2024 längst nicht mehr das übermächtige KI-Modell ist, das es noch vor wenigen Monaten zu sein schien. Neben Reka Core, Gemini 1.5 und Claude 3 haben zahlreiche Modelle kleinerer Unternehmen zumindest aufgeholt. Llama 3 steht in den Startlöchern.
Die technologische Kluft bei der Entwicklung von KI-Modellen scheint sich zu schließen. Mit der Übernahme von Inflection AI durch Microsoft ist dieser Entwicklung kürzlich bereits ein erstes Start-up zum Opfer gefallen - trotz Milliardenfinanzierung. Wie viele große KI-Modelle mit ähnlichen Fähigkeiten braucht die Welt?
In einem aktuellen Podcast äußert sich der CEO von OpenAI, Sam Altman, in diesem Kontext: In Zukunft seien grundlegende KI-Modelle weniger entscheidend, stattdessen drehe sich alles um Personalisierung.
OpenAI und auch Google sollen derzeit einen Forschungsschwerpunkt auf LLM-getriebene personalisierte KI-Agenten legen, die ganze Arbeitsprozesse automatisieren können. OpenAI hat auch sein Angebot im Bereich der Personalisierung für Unternehmensmodelle erweitert.