RT-2: Google Deepmind stellt neues KI-Modell für Robotersteuerung vor

Google Deepmind stellt mit RT-2 ein neues Modell für die Robotersteuerung vor, das aus Roboterdaten und allgemeinen Webdaten lernt und diese beiden Wissensquellen für die Generierung präziser Roboteranweisungen nutzt.
Seit dem Aufkommen großer Sprachmodelle wird auch in der Robotik versucht, die Fähigkeiten von mit Webdaten trainierten LLMs zu nutzen. Ihr Allgemeinwissen in Kombination mit logischen Fähigkeiten sind für die Robotersteuerung im Alltag wertvoll. So können sie etwa mithilfe von Schritt-für-Schritt-Argumentationen, wie sie von LLMs bekannt sind, effizienter in realen Umgebungen zurechtfinden.
RT-2 kombiniert Roboterdaten, Sprache und Bilder für mehrstufige und multimodale Roboterlogik
Die neue Forschungsarbeit baut auf dem Ende letzten Jahres vorgestellten Robotics Transformer 1 (RT-1) auf, dem ersten "großen Robotermodell", das mit Roboterdemonstrationsdaten trainiert wurde, die von 13 Robotern über einen Zeitraum von 17 Monaten in einer Büro-Küchen-Umgebung gesammelt wurden.
Im Vergleich dazu zeigt RT-2 eine verbesserte Generalisierungsfähigkeit und ein semantisches und visuelles Verständnis, das über die während des Trainings gesehenen Roboterdaten hinausgeht. Das Forschungsteam experimentierte hierfür zusätzlich mit Vision Language Models (VLMs), die auf PaLM-E und PaLI-X basieren. RT-2 kann daher Befehle kombiniert aus visuellen und textuellen Eingaben ableiten, während sich etwa SayCan nur auf Sprache verlassen konnte.
Für RT-2 kombiniert Google Deepmind RT-1 mit einem auf Webdaten trainierten Bild-Sprache-Modell. | Video: Deepmind
Das Ergebnis bezeichnet das Team als "Vision-Language-Action Model", das zu "stark verbesserten Roboterstrategien", einer deutlich verbesserten Generalisierungsleistung und emergenten Fähigkeiten führt. Vereinfacht gesagt kann RT-2 mit ein und demselben Modell "sehen", "lesen" und "handeln".
Diese Robustheit wird durch einen dreistufigen Ansatz erreicht: Erstens lernt RT-2 aus Webdaten, die das Modell mit sprachlichen Grundlagen und Alltagslogik versorgen.
Zweitens lernt es aus Roboterdaten, die dem Modell ein praktisches Verständnis davon vermitteln, wie es mit der Welt interagieren soll.
Schließlich kann RT-2 durch die Kombination dieser beiden Datensätze präzise Befehle für die Robotersteuerung verstehen und generieren, die auf realen Szenarien basieren.
Mit RT-2 sind Roboter in der Lage, wie wir Menschen zu lernen und gelernte Konzepte auf neue Situationen zu übertragen. RT-2 zeigt, wie schnell Fortschritte in der künstlichen Intelligenz in die Robotik einfließen und wie vielversprechend sie für universell agierende Roboter sind.
Google Deepmind
Wenn ältere Systeme etwa Müll entsorgen sollen, müssen sie explizit lernen, was Müll ist, wie man ihn erkennt und wie man ihn einsammelt und entsorgt. Im Gegensatz dazu kann RT-2 auf sein umfangreiches Wissen aus dem Web zurückgreifen, um Müll zu identifizieren und zu entsorgen und sogar Handlungen auszuführen, für die es nicht explizit trainiert wurde. Dazu gehören abstrakte Konzepte wie das Verständnis, wann ein zuvor nützlicher Gegenstand (wie eine Bananenschale oder eine Tüte Chips) zu Abfall wird.
RT-2 ist besser in unbekannten Aufgaben
Das Forscherteam zeigt auch, dass RT-2 in der Lage ist, mehrstufige Schlussfolgerungen zu ziehen, indem es die "Gedankenkette" nutzt. Der Roboter begründet beispielsweise, warum ein Stein ein besserer improvisierter Hammer ist als ein Stück Papier oder warum ein müder Mensch einen Energy-Drink brauchen könnte, und trifft so bessere Entscheidungen.

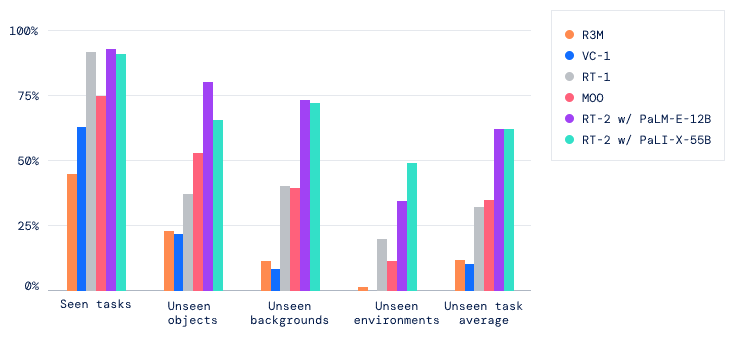
Durch die Übertragung des erworbenen Wissens auf neue Szenarien verbessert RT-2 die Anpassungsfähigkeit von Robotern an unterschiedliche Umgebungen. In mehr als 6000 Robotertests zeigte RT-2 bei trainierten Aufgaben die gleiche Leistung wie sein Vorgänger RT-1 und erzielte große Fortschritte bei untrainierten Aufgaben, bei denen sich die Erfolgsrate von 32 Prozent auf 62 Prozent fast verdoppelte.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.