SciArena: o3 dominiert neue KI-Plattform zur Bewertung wissenschaftlicher Antworten
Mit SciArena steht erstmals eine offene Plattform zur Verfügung, die große Sprachmodelle anhand menschlicher Präferenzen bei wissenschaftlichen Literaturaufgaben bewertet. Erste Ergebnisse zeigen deutliche Unterschiede zwischen den Modellen.
Mit SciArena stellen Forschende der Yale University, der New York University und des Allen Institute for AI eine neue offene Evaluierungsplattform für LRMs und LLMs vor. Die Plattform soll die Leistungsfähigkeit großer Sprachmodelle bei der Bearbeitung wissenschaftlicher Literaturaufgaben vergleichbar machen – ein Bereich, der bisher kaum systematisch untersucht wurde.
Im Gegensatz zu klassischen Benchmarks beruht SciArena auf der Bewertung durch echte Forschende und gleicht in der Bewertungsmethodik der Chatbot Arena: Nutzerinnen und Nutzer stellen wissenschaftliche Fragen, erhalten zwei modellgenerierte, zitierte Langformantworten und entscheiden, welche Antwort besser ist. Die zugrunde liegende Literatur wird mithilfe einer angepassten Retrieval-Pipeline auf Basis von ScholarQA zusammengestellt.
Insgesamt wurden über 13.000 Bewertungen von 102 Forschenden aus Natur-, Ingenieur-, Lebens- und Sozialwissenschaften gesammelt. Die Fragen decken ein breites Spektrum ab, von konzeptionellen Erklärungen bis zur Literatursuche.
o3 dominiert, Open Source überzeugt
OpenAIs o3 führt das aktuelle Leaderboard an, vor Claude-4-Opus und Gemini-2.5-Pro. Unter den Open-Source-Modellen sticht Deepseek-R1-0528 hervor und übertrifft damit mehrere proprietäre Systeme.
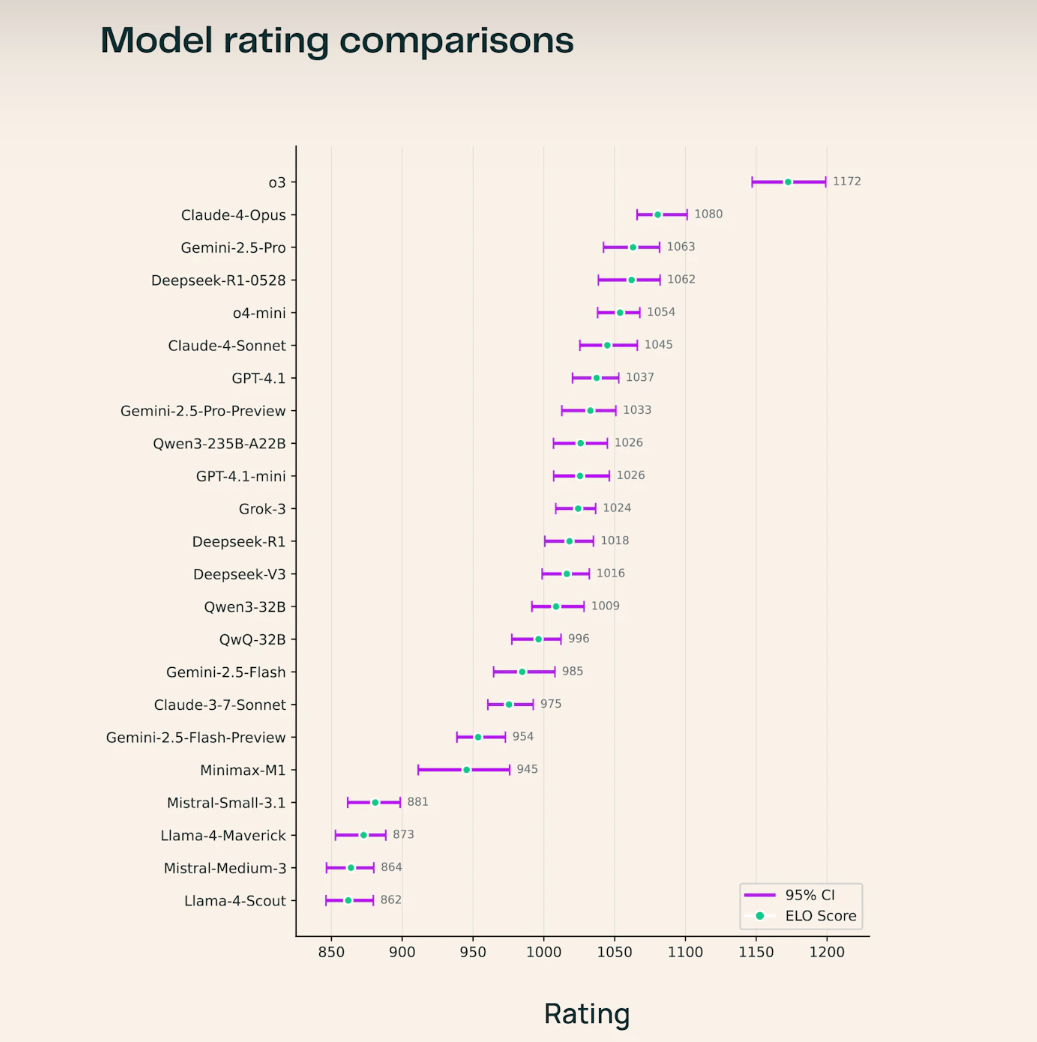
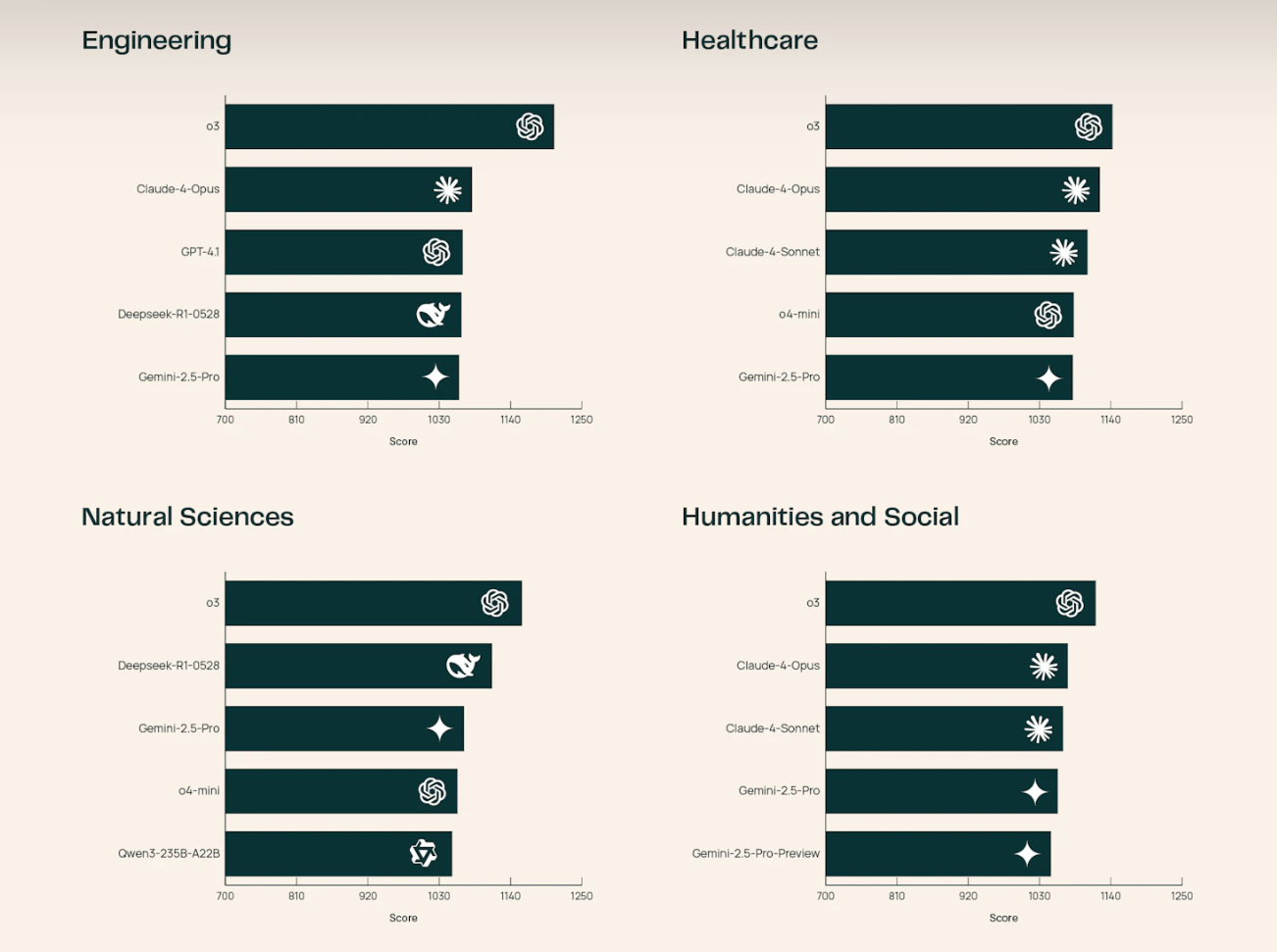
Besonders in den Natur- und Ingenieurswissenschaften zeigt o3 laut dem Team überlegene Leistungen.
Analysen der Forschenden zeigen, dass Nutzer nicht nur auf die Anzahl der Zitationen achten, sondern vor allem auf deren korrekte Zuordnung zu den Aussagen. Der Einfluss von Stilmerkmalen wie Antwortlänge ist in demnach SciArena geringer als in vergleichbaren Plattformen wie Chatbot Arena oder Search Arena.
Automatische Bewertung bleibt schwierig
Mit SciArena-Eval haben die Forschenden zudem einen neuen Benchmark eingeführt, der die Fähigkeiten von Sprachmodellen zur Bewertung anderer Antworten testet. Die besten Modelle erreichen hier nur rund 65 Prozent Übereinstimmung mit menschlichen Präferenzen – ein deutlicher Hinweis auf die Grenzen aktueller LLM-as-a-Judge-Systeme im wissenschaftlichen Kontext.
SciArena ist öffentlich zugänglich, der Code, die Daten und das SciArena-Eval-Benchmark sind Open Source. Ziel ist es, die Entwicklung besserer, menschennaher Modelle im Bereich der wissenschaftlichen Information zu fördern. Künftig soll das System um eine Evaluierung für agentenbasierte Recherche-Plattformen erweitert werden.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.