Sehen, hören, coden: Alibabas Qwen3.5-Omni macht alles gleichzeitig

Kurz & Knapp
- Alibaba hat mit Qwen3.5-Omni ein omnimodales KI-Modell veröffentlicht, das Text, Bilder, Audio und Video verarbeitet und in drei Varianten verfügbar ist.
- Bei Audio-Aufgaben soll es Googles Gemini 3.1 Pro übertreffen. Die Spracherkennung deckt nun 74 Sprachen ab, der Vorgänger kam auf elf.
- Anders als bei früheren Qwen-Modellen gibt es bislang keine offenen Modellgewichte, Qwen3.5-Omni ist nur als API-Dienst nutzbar.
Alibaba veröffentlicht Qwen3.5-Omni, ein omnimodales KI-Modell mit Text-, Bild-, Audio- und Videoverständnis. Es soll Gemini 3.1 Pro bei Audio-Aufgaben übertreffen und beherrscht eine neue Fähigkeit: Programmieren per gesprochener Anweisung und Videoinput.
Die neueste Generation aus Alibabas Qwen-Reihe erscheint in drei Instruct-Varianten (Plus, Flash und Light), verarbeitet Kontexte von bis zu 256.000 Tokens und erfasst laut dem Qwen-Team mehr als zehn Stunden Audio sowie über 400 Sekunden 720P-Video bei einem Frame pro Sekunde. Vortrainiert wurde das Modell nativ omnimodal auf über 100 Millionen Stunden audiovisuellem Material. Neben Text gibt es auch Sprache aus.
215 Benchmarks: Qwen3.5-Omni-Plus soll Gemini 3.1 Pro bei Audio übertreffen
Die Plus-Variante setzt laut dem Qwen-Team auf 215 Audio- und audiovisuellen Teilaufgaben den Stand der Technik. Dazu zählen drei audiovisuelle Benchmarks, fünf Audio-Benchmarks, acht Benchmarks zur Spracherkennung, 156 sprachspezifische Übersetzungsaufgaben und 43 sprachspezifische Erkennungsaufgaben. Qwen3.5-Omni-Plus soll Googles Gemini 3.1 Pro beim allgemeinen Audio-Verständnis, beim Schlussfolgern, bei Erkennung, Übersetzung und Dialog übertreffen. Beim audiovisuellen Gesamtverständnis liege das Modell auf dem Niveau von Gemini 3.1 Pro.

Konkret erreicht Qwen3.5-Omni-Plus laut den veröffentlichten Ergebnissen beim Audio-Verständnis (MMAU) 82,2 Punkte gegenüber 81,1 bei Gemini 3.1 Pro. Beim Musik-Verständnis (RUL-MuchoMusic) fällt der Abstand mit 72,4 zu 59,6 deutlicher aus. Im Sprachdialog-Benchmark VoiceBench erzielt das Modell 93,1 gegenüber 88,9 bei Gemini. Die visuellen und textbasierten Fähigkeiten sollen denen der reinen Qwen3.5-Textmodelle gleicher Größe entsprechen.
Bei der Sprachgenerierung misst sich das Qwen-Team mit ElevenLabs, Gemini 2.5 Pro, GPT-Audio und Minimax. Auf dem anspruchsvollen "Seed-hard"-Testset kommt Qwen3.5-Omni-Plus auf eine Wortfehlerrate von 6,24. GPT-Audio liegt bei 8,19, Minimax bei 8,62 und ElevenLabs bei 27,70. Beim Klonen von Stimmen über 20 Sprachen hinweg erreicht das Modell eine Wortfehlerrate von 1,87 und einen Cosine-Ähnlichkeitswert von 0,79.
Von 11 auf 74 Sprachen: Zehnfacher Sprung bei der Spracherkennung
Von 11 auf 74 Sprachen: Zehnfacher Sprung bei der Spracherkennung
Im Vergleich zum Vorgänger Qwen3-Omni hat das Qwen-Team die Sprachunterstützung massiv ausgebaut. Die Spracherkennung deckt nun 74 Sprachen und 39 chinesische Dialekte ab, insgesamt 113 Sprachen und Dialekte. Der Vorgänger kam auf elf Sprachen und acht chinesische Dialekte. Die Sprachausgabe unterstützt jetzt 36 Sprachen und Dialekte. Insgesamt stehen 55 verschiedene Stimmen zur Auswahl, darunter benutzerdefinierte, szenariospezifische, dialektale und mehrsprachige Varianten.

Bei der Spracherkennung auf dem Fleurs-Datensatz (Top 60 Sprachen) erreicht Qwen3.5-Omni-Plus eine Wortfehlerrate von 6,55, verglichen mit 7,32 bei Gemini 3.1 Pro. Bei chinesischen Varianten wie Kantonesisch ist der Vorsprung erheblich: 1,95 gegenüber 13,40. Das Kontextfenster wächst ebenfalls deutlich, von 32.000 auf 256.000 Token.
ARIA soll ein bekanntes Problem der Sprachausgabe lösen
Die Architektur folgt weiterhin dem Thinker-Talker-Prinzip. Der Thinker analysiert omnimodale Eingaben und erzeugt Text, der Talker wandelt diesen in kontextbezogene Sprache um. Beide Komponenten setzen nun auf eine Hybrid-Attention-MoE-Architektur statt auf die reine Mixture-of-Experts-Architektur des Vorgängers.
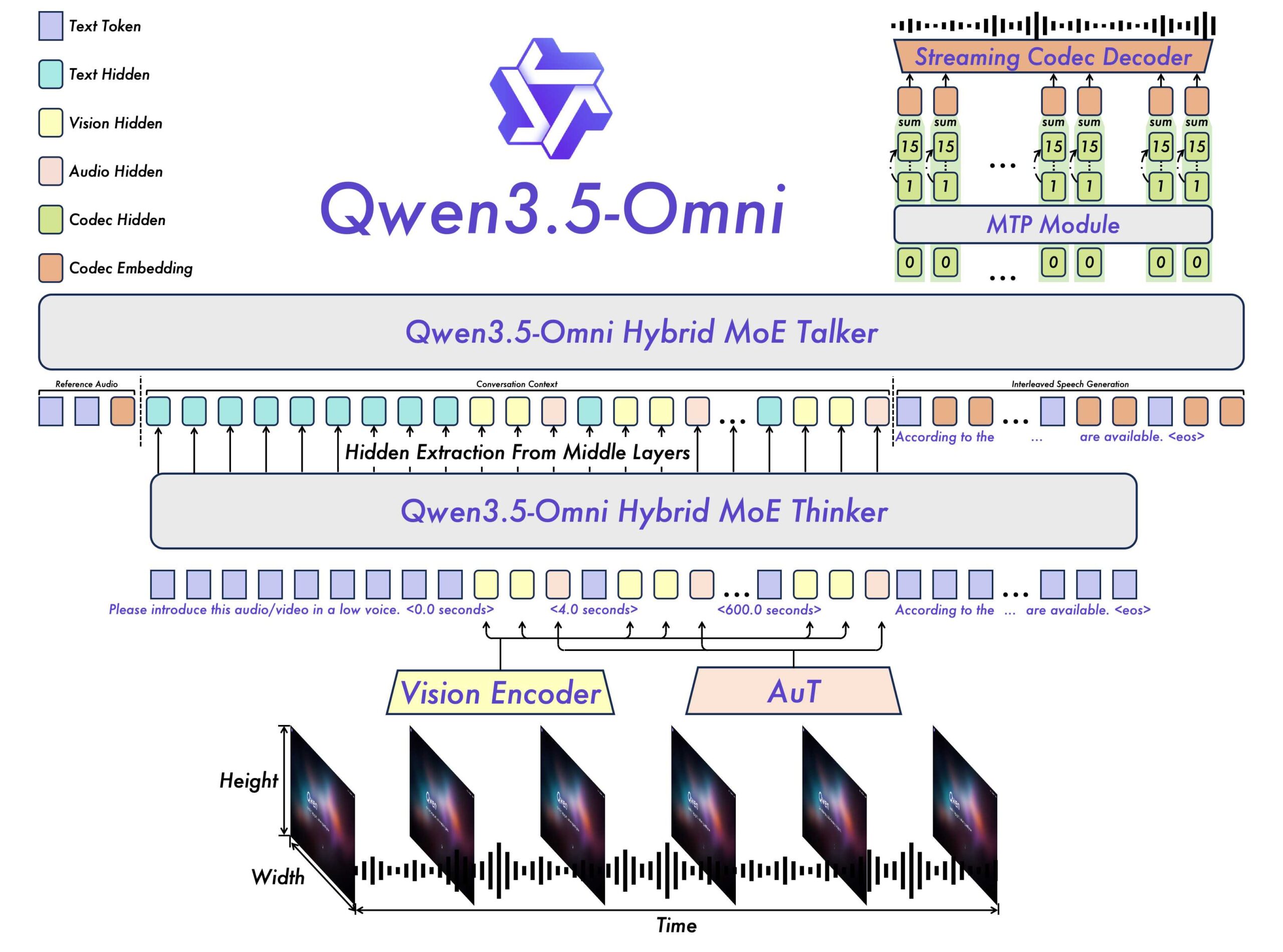
Die wichtigste technische Neuerung heißt ARIA (Adaptive Rate Interleave Alignment). Das Verfahren gleicht Text- und Sprach-Token dynamisch ab und verschränkt sie miteinander. Damit will das Qwen-Team ein verbreitetes Problem bei der Echtzeit-Sprachausgabe lösen: Weil Text- und Sprach-Token unterschiedlich effizient kodiert werden, kommt es bei Streaming-Gesprächen häufig zu Auslassungen, Versprechern oder undeutlich ausgesprochenen Zahlen. ARIA soll die Sprachsynthese natürlicher und robuster machen, ohne die Echtzeitfähigkeit einzuschränken. Der Vorgänger arbeitete noch mit einer starren 1:1-Zuordnung zwischen Text- und Audio-Token.
Programmieren per Video und Sprache als emergente Fähigkeit
Beim Skalieren des omnimodalen Trainings ist laut dem Qwen-Team eine unerwartete Fähigkeit aufgetaucht. Das Modell kann auf Grundlage gesprochener Anweisungen und Videoinhalte direkt Code schreiben. Das Team nennt das "Audio-Visual Vibe Coding". In den veröffentlichten Demos erzeugt Qwen3.5-Omni-Plus etwa aus einer mündlichen Beschreibung und einem Videoclip ein funktionierendes Snake-Spiel. Die Fähigkeit sei nicht gezielt trainiert worden, sondern durch das native multimodale Skalieren entstanden.
Außerdem kann das Modell Audio- und Videoinhalte so detailliert beschreiben, dass die Ergebnisse an Drehbücher erinnern. Es segmentiert automatisch, setzt sekundengenaue Zeitstempel und liefert feingranulare Angaben zu Figuren, Dialogen, Soundeffekten und deren Zusammenspiel. In einer Demo zerlegt das Modell einen dreiminütigen Dokumentarfilm über Löwen Szene für Szene und benennt jeden Sprecher, jeden Schnitt und jedes Geräusch. Eine weitere Demo zeigt, wie das Modell Gewaltszenen in Videospielen für die Inhaltsmoderation erkennt und tabellarisch mit Zeitstempeln und Risikostufen auflistet.
Echtzeit-Interaktion mit intelligenter Unterbrechung und Websuche
Für Gespräche in Echtzeit bringt Qwen3.5-Omni mehrere Funktionen mit, die dem Vorgänger fehlten. Die "semantische Unterbrechung" erkennt, ob ein Nutzer tatsächlich etwas sagen will, und ignoriert Hintergrundgeräusche oder kurze Einwürfe. Das Modell entscheidet eigenständig, ob es eine Websuche startet, um aktuelle Fragen zu beantworten, und beherrscht komplexe Funktionsaufrufe.
Nutzer können die Sprechweise des Modells per Sprachbefehl anpassen. Lautstärke, Tempo und Emotion lassen sich während des Gesprächs steuern. Per Voice Cloning lässt sich eine eigene Stimme hochladen und als KI-Assistentenstimme verwenden. Alle diese Funktionen stehen laut dem Qwen-Team über die Realtime API bereit. Das Modell ist zudem über Qwen Chat und das Alibaba Cloud Model Studio zugänglich. Anders als bei früheren Qwen-Veröffentlichungen wie dem Vorgänger Qwen3-Omni und den Qwen3.5-Textmodellen hat Alibaba bislang keine Modellgewichte veröffentlicht und nennt auch keine Lizenz. Qwen3.5-Omni ist damit vorerst nur als API-Dienst nutzbar.
Qwen3.5-Omni erscheint inmitten von Teamturbulenzen und Modelloffensive
Qwen3.5-Omni reiht sich in eine Serie schneller Veröffentlichungen ein. Erst im April 2025 hatte Alibaba mit Qwen3-Omni den Vorgänger vorgestellt. Das 30-Milliarden-Parameter-Modell erzielte laut Alibaba auf 32 von 36 Audio- und Video-Benchmarks Spitzenleistungen und antwortete bei reinen Audio-Eingaben in 211 Millisekunden. Parallel hat Alibaba die Qwen-3.5-Textmodellreihe auf vier Modelle erweitert. Das Flaggschiff Qwen3.5-397B-A17B nutzt eine Mixture-of-Experts-Architektur mit 397 Milliarden Gesamt- und 17 Milliarden aktiven Parametern.
Die Veröffentlichung fällt allerdings in eine unruhige Phase. Alibabas KI-Chefentwickler Junyang Lin, der leitende Kopf hinter der gesamten Qwen-Modellreihe, hat kürzlich überraschend seinen Rücktritt erklärt. Weitere Schlüsselfiguren des Teams folgten, darunter Verantwortliche für Qwen-Coder, Post-Training und Qwen 3.5/VL. Auslöser soll eine interne Umstrukturierung gewesen sein, bei der ein von Googles Gemini-Team abgeworbener Forscher die Leitung übernehmen sollte. Alibaba-CEO Eddie Wu kündigte daraufhin eine neue "Foundation Model Task Force" an und betonte, die Weiterentwicklung von Grundlagenmodellen bleibe eine "zentrale strategische Priorität".
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnieren