Seoul World Model: Navers neue Video-KI basiert auf echten Street-View-Aufnahmen

Kurz & Knapp
- Der südkoreanische Internetkonzern Naver hat mit dem Seoul World Model ein Video-Weltmodell vorgestellt, das reale Stadtgeometrie aus 1,2 Millionen eigener Street-View-Aufnahmen nutzt, um ortsgebundene Videos zu generieren.
- Das Modell lernt anhand von Aufnahmen aus unterschiedlichen Zeitpunkten, feste Strukturen wie Gebäude von zufälligen Objekten zu unterscheiden. Simulierte Videos ergänzen fehlende Blickwinkel, und bei langen Strecken dient ein Street-View-Bild etwas weiter voraus auf der Route als visueller Anker für mehr Konsistenz.
- In Tests übertraf SWM sechs aktuelle Video-Weltmodelle in visueller Qualität und zeitlicher Konsistenz und generalisierte ohne zusätzliches Training auf fremde Städte wie Busan und Ann Arbor.
Der südkoreanische Internetkonzern Naver hat ein Video-Weltmodell entwickelt, das reale Stadtgeometrie aus über einer Million eigener Street-View-Aufnahmen als Grundlage nutzt. Das Modell generalisiert ohne Finetuning auf fremde Städte.
Bisherige Video-Weltmodelle erzeugen zwar visuell überzeugende, aber vollständig erfundene Umgebungen. Alles jenseits des Startbildes, die Geometrie unsichtbarer Straßen, entfernte Gebäude, halluziniert das Modell frei. Forschende von Naver und Naver Cloud gehen nun einen grundlegend anderen Weg: Ihr Seoul World Model (SWM) verankert die Videogenerierung in der tatsächlichen Geometrie und Erscheinung einer konkreten Großstadt.
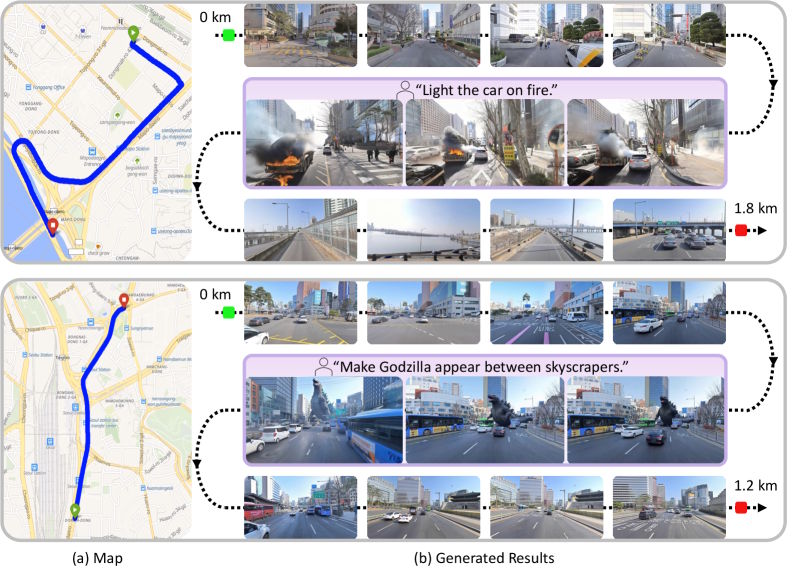
Laut dem Forschungspapier handelt es sich um das erste Weltmodell, das an einen realen physischen Ort gebunden ist. Naver gilt als das "Google Südkoreas" und betreibt unter anderem die dort dominierende Suchmaschine sowie den Kartendienst Naver Map, der ähnlich wie Google Maps über eigene Straßenpanoramen verfügt. Aus diesem Fundus speist sich das Modell.
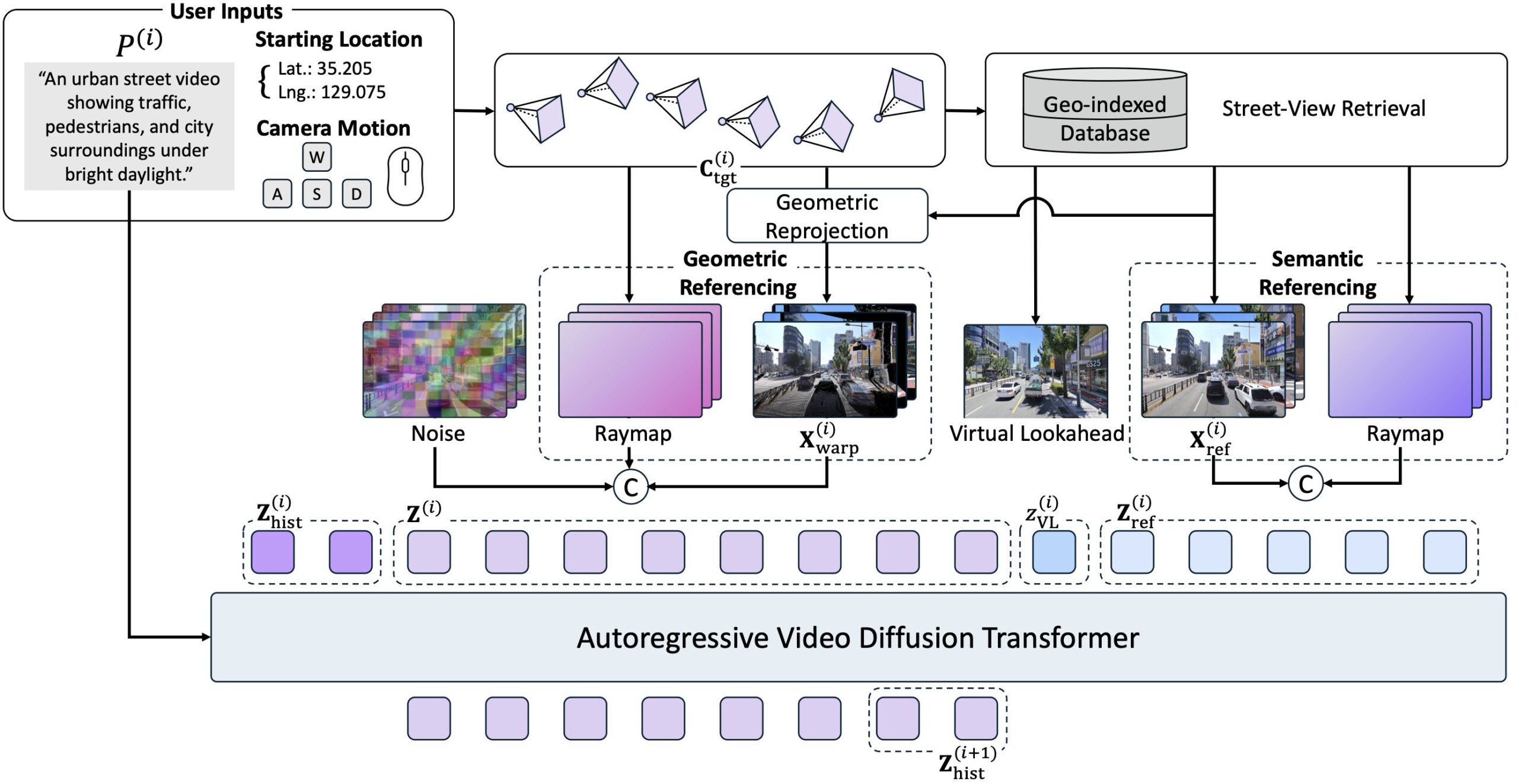
Nutzer geben geografische Koordinaten, eine gewünschte Kamerabewegung und einen Textprompt ein. Das Modell durchsucht dann eine Datenbank mit 1,2 Millionen Panoramabildern von Naver Map, ruft die räumlich nächstgelegenen Street-View-Aufnahmen ab und nutzt sie als Orientierung für die schrittweise Videogenerierung.
Echte Straßendaten bringen drei Probleme mit sich
Die Arbeit mit realen Aufnahmen stellt das Modell vor Herausforderungen, die bei rein synthetischen Weltmodellen nicht auftreten. Am schwersten wiegt, dass Street-View-Bilder Momentaufnahmen sind. Autos und Fußgänger, die zum Aufnahmezeitpunkt dort standen, haben mit der dynamischen Szene, die das Modell generieren soll, nichts zu tun. Ohne Gegenmaßnahme würde das Modell diese zufälligen Objekte aus den Referenzbildern in die generierte Szene kopieren.

Die Forscher lösen das mit Cross-temporal Pairing: Im Training kombinieren sie Referenzbilder und Zielsequenzen bewusst aus unterschiedlichen Aufnahmezeitpunkten. So lernt das Modell, dauerhafte Strukturen wie Gebäudefassaden von zufällig anwesenden Objekten wie parkenden Autos zu unterscheiden. In den Ablationsstudien erweist sich dieser Mechanismus als wirkungsvollster Einzelfaktor.
Hinzu kommt, dass Street-View-Kameras auf Fahrzeugen montiert sind und nur alle 5 bis 20 Meter ein Bild aufnehmen. Es gibt also weder durchgehende Videos noch Aufnahmen aus Fußgängerperspektive oder aus der Luft. Um diese Lücke zu schließen, erzeugen die Forscher 12.700 synthetische Videos im Unreal-Engine-Simulator CARLA, mit Kamerapfaden aus Fußgänger-, Fahrzeug- und Freiflugperspektive. Zusätzlich entwickelten sie eine Pipeline, die aus den räumlich verstreuten Einzelbildern zeitlich zusammenhängende Trainingsvideos interpoliert.

Schließlich schaukeln sich bei langen Strecken kleine Fehler auf, weil das Modell Video Abschnitt für Abschnitt erzeugt. Bisherige Methoden nutzen das allererste Bild als festen Orientierungspunkt, doch der verliert seinen Nutzen, sobald die Kamera Hunderte Meter weitergefahren ist.
SWM ersetzt diesen statischen Anker durch einen sogenannten Virtual Lookahead Sink: Für jeden neuen Abschnitt ruft das Modell ein Street-View-Bild ab, das etwas weiter voraus auf der Strecke liegt, und fügt es als virtuelles Ziel ein. So steht dem Modell stets ein fehlerfreier Orientierungspunkt zur Verfügung, der sich mit der Kamerabewegung mitbewegt.
Tiefenkarten und Originalbilder ergänzen sich
Die abgerufenen Street-View-Bilder fließen über zwei ergänzende Wege in die Generierung ein. Einerseits projiziert das Modell eine räumlich nahe Referenzaufnahme mithilfe ihrer Tiefeninformationen in die Zielperspektive und erhält so Hinweise auf das räumliche Layout der Szene.
Andererseits werden die Referenzbilder nicht direkt als Rohbilder in den Transformer eingespeist, sondern zunächst in latente Repräsentationen kodiert und als semantische Referenzen eingebunden. Dadurch kann das Modell zusätzliche Erscheinungsdetails der Umgebung nutzen. Laut den Forschern verschlechtert sich die Qualität deutlich, wenn einer dieser beiden Pfade wegfällt.
Technisch baut SWM auf Nvidias Cosmos-Predict2.5-2B auf, einem Diffusion-Transformer mit zwei Milliarden Parametern. Die Forscher trainierten das Modell auf 24 Nvidia-H100-GPUs mit 440.000 Seoul-Street-View-Bildern, den synthetischen CARLA-Daten und öffentlich verfügbaren Waymo-Fahrdaten.
Modell funktioniert auch in Städten, die es nie gesehen hat
Die Forscher haben SWM in Seoul und zudem in Busan und der US-Stadt Ann Arbor getestet, obwohl beide Städte im Training vollständig fehlten. Auf eigens erstellten Benchmarks mit jeweils 30 Testsequenzen von etwa 100 Metern Länge übertrifft SWM laut dem Paper sechs aktuelle Video-Weltmodelle, darunter Aether, DeepVerse und HY-World1.5, in visueller Qualität, Kameratreue, zeitlicher Konsistenz und Übereinstimmung mit den realen Orten.
Bestehende Modelle driften den Vergleichen zufolge über längere Strecken zunehmend ab, was zu verschwommenen Videos oder einem vollständigen Zusammenbruch der Generierung führe. SWM halte die Ausgabe hingegen über Hunderte Meter stabil. Trotz der strikten räumlichen Verankerung lässt sich das Modell per Textprompt steuern: Nutzer können Wetter, Tageszeit oder hypothetische Szenarien verändern, während das zugrundeliegende Stadtlayout erhalten bleibt.
Fehlende Videodaten begrenzen die Qualität
Die Forscher benennen auch Schwächen ihres Ansatzes. Weil durchgehende Videoaufnahmen ganzer Städte nicht frei verfügbar seien, basiere das Training auf interpolierten Sequenzen aus Einzelbildern, die qualitativ hinter echtem Videomaterial zurückblieben. Fehlerhafte Zeitstempel in den Metadaten führten zudem gelegentlich dazu, dass Fahrzeuge in generierten Videos abrupt auftauchen oder verschwinden.
Alle verwendeten Street-View-Daten seien datenschutzkonform verarbeitet, Gesichter und Kennzeichen vor dem Training unkenntlich gemacht worden. Als Anwendungsfelder nennen die Forscher Stadtplanung, autonomes Fahren und standortbasierte Exploration.
Weltmodelle sind derzeit ein intensiv beforschtes Feld in der KI-Branche. Runway stellte kürzlich mit GWM-1 ein erstes "General World Model" vor, das eine interne Darstellung einer Umgebung aufbaut und künftige Ereignisse in Echtzeit simulieren soll. Google-Deepmind-CEO Demis Hassabis sieht in solchen Modellen einen entscheidenden Schritt auf dem Weg zur allgemeinen künstlichen Intelligenz und beschreibt ihren Aufbau als langjährige Kernstrategie von Deepmind. Eine aktuelle Studie von Microsoft Research und mehreren US-Universitäten zeigte zudem, dass auch große Sprachmodelle als Weltmodelle fungieren können, indem sie Umgebungszustände mit mehr als 99 Prozent Genauigkeit vorhersagen.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnieren