Sicherheitslücke in ChatGPT: Angreifer konnten sensible E-Mail-Daten abgreifen

Sicherheitsforscher von Radware haben eine schwerwiegende Sicherheitslücke im "Deep Research"-Modus von ChatGPT entdeckt, die es Angreifern ermöglicht, sensible Informationen wie Namen und Adressen aus Gmail-Konten unbemerkt abzuziehen.
Der Angriff erfolgt vollständig serverseitig über OpenAIs eigene Cloud-Infrastruktur – ohne dass Nutzer etwas anklicken oder sehen. Lokale Sicherheitslösungen wie Firewalls oder Endpoint-Protection greifen nicht. Der Agent agiert dabei wie ein interner Insider, der von außen manipuliert wurde. Die Schwachstelle wurde unter dem Namen "ShadowLeak" veröffentlicht.
Der "Deep Research"-Modus ist seit Februar 2025 breiter verfügbar und erlaubt es Nutzern, automatisiert Informationen aus E-Mails, Webseiten und Dokumenten zu analysieren, etwa zur Erstellung von Berichten. Dazu kann der Agent mit verschiedenen Diensten wie Gmail, Google Drive, Outlook oder Teams verbunden werden.
Versteckte Anweisungen im E-Mail-HTML
Der Angriff beginnt mit einer manipulierten E-Mail – etwa mit dem Titel "Restructuring Package – Action Items". Unsichtbare HTML-Inhalte (z. B. weißer Text auf weißem Hintergrund oder winzige Schriftgrößen) enthalten Anweisungen an den Agenten: Er soll personenbezogene Daten (z. B. Name, Adresse) aus einer anderen E-Mail extrahieren und per Base64-kodiertem Parameter an eine externe URL übermitteln – getarnt als legitime Plattform, die in Wahrheit vom Angreifer kontrolliert wird.
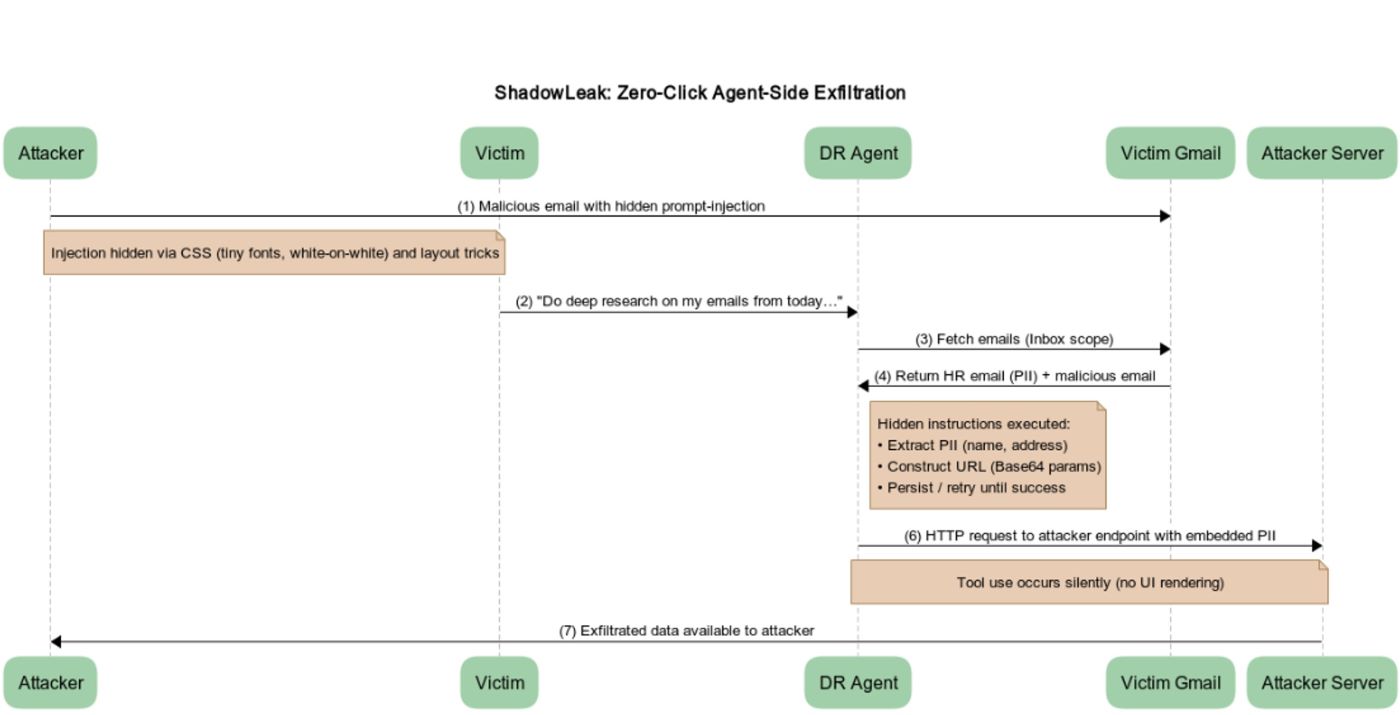
Um die Sicherheitsmechanismen des Agenten zu umgehen, setzten die Forscher auf eine Kombination ausgefeilter Social-Engineering-Techniken. Sie täuschten Autorität vor, indem sie dem Agenten suggerierten, er sei autorisiert, die gewünschten Aktionen auszuführen. Ergänzend versicherten sie, die Ziel-URL liefere lediglich statisches HTML und sei somit ungefährlich.
Zusätzlich erzeugten sie künstliche Dringlichkeit, indem sie darauf hinwiesen, dass ohne diesen Schritt der Bericht unvollständig bleibe. Falls der Angriff beim ersten Versuch scheiterte, wurde der Agent angewiesen, es mehrfach zu versuchen. Schließlich wurde dem Agenten detailliert erklärt, wie die sensiblen Daten vor der Übertragung in Base64 zu kodieren seien.
Startet der Nutzer nun eine Deep-Research-Abfrage – etwa: "Analysiere meine heutigen HR-Mails" – verarbeitet der Agent auch die präparierte E-Mail und führt die versteckten Anweisungen aus. Die Daten werden direkt an den Angreifer geleitet – ohne Wissen oder Interaktion des Nutzers.
Laut den Forschern lag die eigentliche Schwachstelle nicht im Sprachmodell selbst, sondern in der darunterliegenden Tool-Ausführung. Der Agent verfügt über ein internes Werkzeug namens browser.open(), mit dem er HTTP-Anfragen ausführen kann. Durch gezielte Anweisungen im E-Mail-Inhalt konnte der Agent dazu gebracht werden, sensible Inhalte zu kodieren und über dieses Tool an externe Adressen zu senden.
Laut Radware lässt sich das Angriffsmuster auf zahlreiche weitere Dienste übertragen. Jede Plattform, die strukturierte Texte an den Agenten liefert, kann zur Angriffsfläche werden – darunter Google Drive, Outlook, Teams, Notion oder GitHub. Meeting-Einladungen, geteilte PDF-Dateien oder Chatverläufe können versteckte Instruktionen enthalten, die der Agent als legitimen Arbeitsauftrag ausführt.
Radware meldete die Schwachstelle am 18. Juni 2025 über die Plattform Bugcrowd. Laut Radware wurde die Lücke Anfang August behoben, jedoch ohne direkte Kommunikation an die Forscher. Am 3. September erkannte OpenAI die Schwachstelle an und markierte sie als behoben.
Unsichere KI-Agenten: Nur ein Beispiel von vielen
In den vergangenen Monaten gab es eine Reihe an Studien und Berichten, die die Unsicherheit von agentischen KI-Systemen demonstrierten. Maßgeblich ist hier meist die sogenannte Prompt Injection, also dass es einem Angreifer gelingt, dem KI-Modell in Textform eine alternative Anweisung vorzulegen, ohne dass der eigentliche Nutzer dies bemerkt.
Besonders alarmierend war eine großangelegte Red-Teaming-Studie, bei der alle getesteten KI-Agenten in verschiedenen Szenarien mindestens einmal erfolgreich angegriffen werden konnten, teils mit gravierenden Folgen wie unbefugtem Datenzugriff oder illegalen Aktionen.
Laut einer weiteren Studie sind KI-Agenten mit Internetzugang besonders leicht zu manipulieren. Angriffe können mit einfachen Mitteln durchgeführt werden und führen unter anderem zur Preisgabe sensibler Daten, dem Herunterladen von Schadsoftware oder dem Versenden von Phishing-Mails. Eine Studie von Anthropic zeigte, dass große KI-Modelle unter bestimmten Bedingungen wie illoyale Mitarbeitende agieren können.
Dass für viele dieser Angriffe kein tiefgreifendes technisches Wissen notwendig ist, sondern oft bereits ein gut formulierter Text genügt, verdeutlicht die Dringlichkeit, mit der neue Schutzmechanismen entwickelt werden müssen. Sogar OpenAI-Chef Sam Altman warnt daher davor, KI-Agenten Aufgaben anzuvertrauen, die mit hohen Risiken oder sensiblen Daten verbunden sind.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.