
Snowflake veröffentlicht das hauseigene Sprachmodell Arctic als Open Source. Es soll vor allem bei unternehmensrelevanten Aufgaben mit Effizenz glänzen.
Das Datenbank- und Analyse-Unternehmen Snowflake hat mit Arctic ein eigenes Large Language Model (LLM) entwickelt und stellt es ab sofort als Open Source zur Verfügung. Arctic zeichnet sich laut Snowflake durch hohe Effizienz sowohl beim Training als auch bei der Inferenz aus.
Snowflake positioniert Arctic für Unternehmensanwendungen. Das Modell sei besonders leistungsfähig bei unternehmensrelevanten Aufgaben wie der Generierung von SQL-Code, allgemeiner Programmierung und dem Befolgen komplexer Anweisungen.

Fokus auf effizientes KI-Training
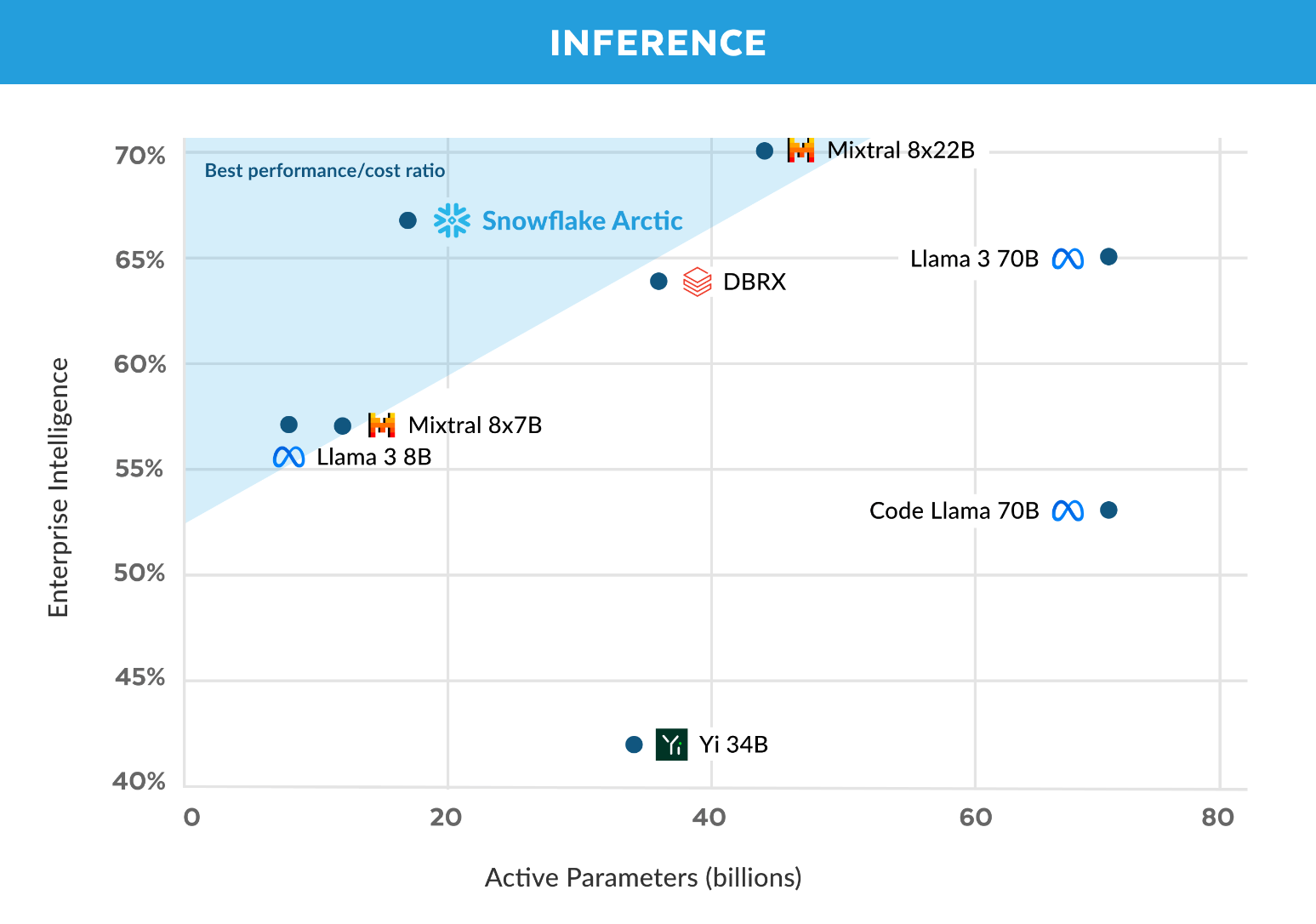
Diese Stärken fasst Snowflake in der selbst definierten Metrik "Enterprise Intelligence" zusammen. Hier soll Arctic bei vergleichbarem Trainingsaufwand deutlich besser abschneiden als Open-Source-Konkurrenten.
Laut Snowflake wurde für das Training von Arctic ein Budget von weniger als 2 Millionen US-Dollar benötigt, was etwa 3.000 GPU-Wochen entspricht. Dennoch sei Arctic gleichwertig oder sogar besser in Bezug auf Enterprise Intelligence als Modelle wie Llama 3, 8B und 70B von Meta, die mit einem wesentlich höheren Budget trainiert wurden.

Um diese Trainingseffizienz zu erreichen, setzt Arctic auf eine hybride Architektur aus Dense Transformer und Mixture of Experts (MoE). Die Basis bildet ein Dense Transformer mit 10 Milliarden Parametern, der durch eine MoE Residualschicht mit insgesamt 480 Milliarden Parametern ergänzt wird.
Eine detaillierte Beschreibung des Modells und des Trainings gibt Snowflake in einem "Cookbook" heraus, in dem die Entwickler ihre Erkenntnisse und empfohlene Vorgehensweisen zum Training von MoE-Modellen beschreiben. Damit sollen Interessierte in die Lage versetzt werden, selbst effiziente LLMs zu erstellen, ohne den mühsamen Weg unzähliger Experimente gehen zu müssen.
Die Modell-Checkpoints für die Basis- und die instruierte Version von Arctic stehen ab sofort auf Hugging Face unter der Apache 2.0-Lizenz zum Download bereit. Auf Github gibt es Hinweise zur Inferenz und zum Fine-Tuning.
In Zusammenarbeit mit Nvidia und der vLLM-Community will Snowflake auch optimierte Implementierungen für das Fine-Tuning und Inferencing bereitstellen. Weitere Modelle der Arctic-Serie sind bereits in Planung.


