Microsoft will mit LLM-Augmenter Chatbot-Fehler bekämpfen

Microsoft zeigt LLM-Augmenter, ein Framework, mit dem ChatGPT und andere Sprachmodelle weniger Falschinformationen produzieren sollen.
Mit ChatGPT von OpenAI, dem Chatbot Bing von Microsoft oder demnächst Bard von Google haben große Sprachmodelle Einzug in die Gesellschaft gehalten. Eine Schwäche dieser Modelle ist, dass sie Fakten halluzinieren und mit großer Überzeugung aussprechen.
Seit Jahren entwickeln Forschende verschiedene Methoden, um Halluzinationen in Sprachmodellen zu reduzieren. Mit dem Einsatz der Technologie in kritischen Bereichen, etwa in der Suche, wird eine Lösung immer dringender.
Mit dem LLM-Augmenter stellt Microsoft nun ein Framework vor, mit dem die Anzahl der Halluzinationen zumindest etwas reduziert werden kann.
Microsofts LLM-Augmenter setzt auf Plug-and-Play-Module
In ihrer Arbeit haben Forschende von Microsoft und der Columbia University ChatGPT um vier Module erweitert: Working Memory, Policy, Action Executor und Utility. Diese Module sind ChatGPT vorgeschaltet und erweitern die Anfragen der Nutzenden um Fakten, die dann in einem erweiterten Prompt an ChatGPT weitergeleitet werden.
Das Working Memory verfolgt den internen Dialog und speichert alle wichtigen Informationen einer Konversation, einschließlich der menschlichen Anfrage, der abgerufenen Fakten und der ChatGPT-Antworten.
Das Policy-Modul wählt die nächste Aktion des LLM-Augmenters aus, einschließlich der Abfrage von Wissen aus externen Datenbanken wie Wikipedia, des Aufrufs von ChatGPT, um einen Antwortkandidaten zu generieren, der vom Utility-Modul geprüft wird, und des Sendens einer Antwort an die Nutzenden, wenn die Antwort die Prüfung durch das Utility-Modul besteht.
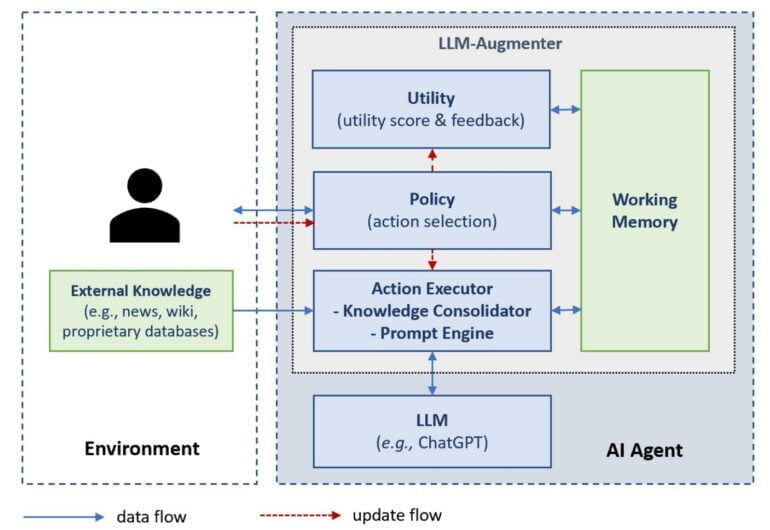
Die Strategien des Policy-Moduls können von Hand geschrieben oder erlernt werden. Im Paper setzt Microsoft für ChatGPT aufgrund der geringen Bandbreite zum Zeitpunkt der Tests auf manuell geschriebene Regeln, wie "Rufe immer externe Quellen auf", zeigt aber anhand eines T5-Modells, dass der LLM-Augmenter Verfizierungsstrategien auch lernen kann.
Der Action Executor wird vom Policy-Modul gesteuert und kann Wissen aus externen Quellen sammeln und verknüpfen sowie aus diesen Fakten und den Antwortkandidaten von ChatGPT neue Prompts generieren, die diese Fakten enthalten und wiederum an ChatGPT weitergeleitet werden. Das Utility-Modul stellt fest, ob die Antwortkandidaten von ChatGPT dem gewünschten Ziel einer Konversation entsprechen und gibt eine Rückmeldung an das Policy-Modul.
In einem Dialog zur Informationssuche prüft das Utility-Modul beispielsweise, ob alle Antworten durch externe Quellen belegt sind. In einem Dialog zur Reservierung in einem Restaurant sollten die Antworten dagegen eher gesprächsartig sein und den Benutzer ohne abzuschweifen durch den Reservierungsprozess führen. Auch hier kann laut Microsoft eine Mischung aus spezialisierten Sprachmodellen und handgeschriebenen Regeln verwendet werden.
LLM-Augmenter verringert Chatbot-Fehler, aber weitere Forschung ist notwendig
In den von Microsoft durchgeführten Tests zeigt das Team, dass der LLM-Augmenter die ChatGPT-Ergebnisse verbessern kann: In einem Kundendienst-Test bewerteten Menschen die generierten Antworten als 32,3 Prozent nützlicher - laut Microsoft ein Wert, der Fundiertheit oder Halluzinationen der Antworten misst - und als 12,9 Prozent menschlicher als die nativen ChatGPT-Antworten.
Im Wiki-QA-Benchmark, bei dem das Modell Sachfragen beantworten muss, die oft Informationen erfordern, die über mehrere Wikipedia-Seiten verteilt sind, erhöht LLM-Augmenter die Anzahl richtiger Aussagen ebenfalls deutlich, kommt aber nicht an speziell für diese Aufgabe trainierte Modelle heran.
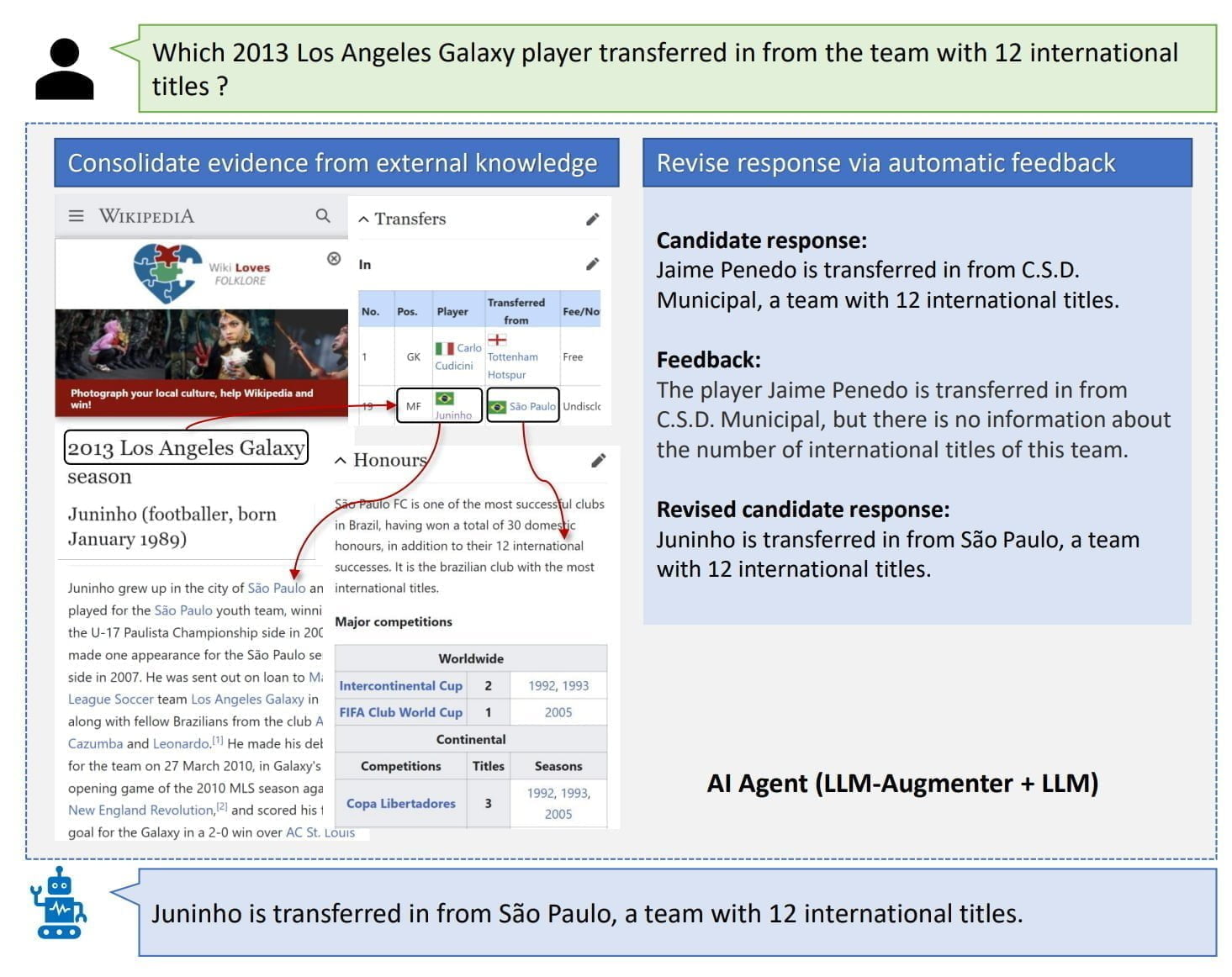
Microsoft plant ein Update der Arbeit mit einem mit ChatGPT trainierten Modell und mehr menschlichem Feedback für die eigenen Ergebnisse. Feedback von und Interaktionen mit Menschen sollen auch für das Training von LLM-Augmentern genutzt werden. Das Team vermutet, dass weitere Verbesserungen mit verfeinerten Prompt-Designs möglich sind.
Ob LLM-Augmenter oder ein ähnliches Framework für Bing genutzt wird, verrät das Paper nicht.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.