Sprachmodelle denken anders: Studie zeigt tiefe Lücke zu menschlichem Reasoning
Eine große Analyse von mehr als 170.000 Denkspuren offener Reasoning-Modelle zeigt: Große Sprachmodelle setzen bei schwierigen Aufgaben vor allem einfache Standardstrategien ein. Eine neue, kognitionswissenschaftlich begründete Einteilung von Denkprozessen macht sichtbar, welche Fähigkeiten fehlen und wann zusätzliche Denkhinweise im Prompt wirklich helfen.
Laut der Studie „Cognitive Foundations for Reasoning and Their Manifestation in LLMs“ reichen heutige Tests für Sprachmodelle nicht aus, um deren Denkfähigkeit zu beurteilen. Sie messen vor allem, ob eine Antwort stimmt, schreiben die Autor:innen im Paper. Ob ein Modell wirklich schlussfolgert oder nur bekannte Muster wiederholt, bleibe meist unsichtbar.
Das Team wertete deshalb 171.485 ausführliche Denkspuren von 17 Modellen sowie 54 laut mit gesprochene Lösungswege von Menschen aus und verglich sie. Die Aufgaben reichen von Rechenaufgaben über Fehlersuche bis zu politischen und medizinischen Dilemmata.

Neue Landkarte für das Denken von KI-Modellen
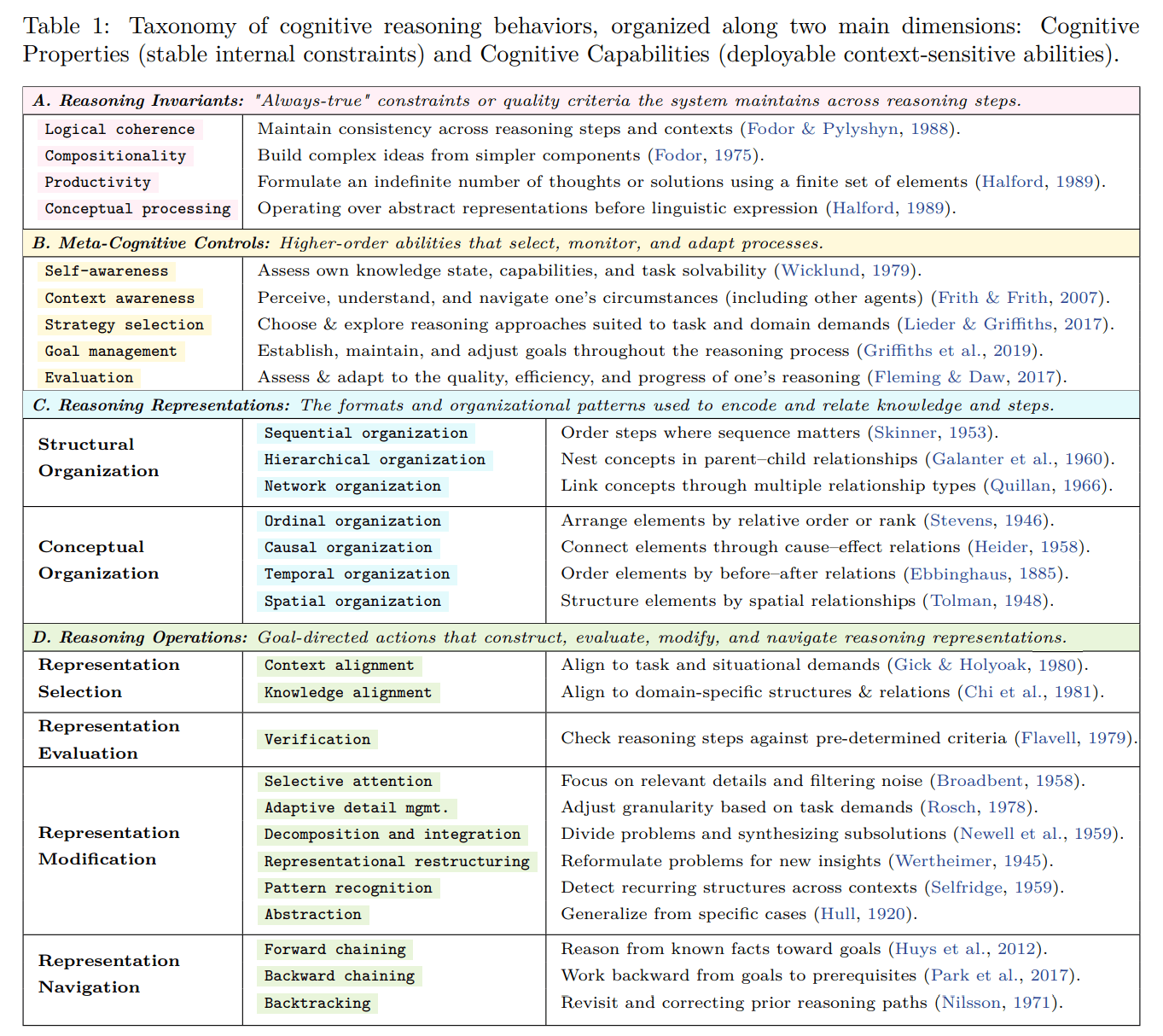
Um diese Spuren zu vergleichen, definieren die Forschenden 28 wiederkehrende „Denkbausteine“. Dazu gehören:
- Grundregeln wie Widerspruchsfreiheit und das Kombinieren einfacher Begriffe zu komplexeren,
- Selbststeuerung, etwa sich Ziele setzen, die eigene Unsicherheit bemerken oder den Fortschritt bewerten,
- verschiedene Arten, Informationen zu ordnen – als Liste, Baum, Ursache-Wirkungs-Kette oder räumliches Bild,
- typische Denkbewegungen wie Probleme zerlegen, Zwischenschritte prüfen, einen Ansatz zurückrollen oder aus Beispielen eine allgemeine Regel ableiten.
Diese Einteilung verwenden sie, um in jeder Denkspur Satzstücke zu markieren, in denen ein bestimmter Baustein sichtbar wird.
Bei schwierigen Aufgaben schalten Modelle auf Autopilot
Das Ergebnis: Auf klar strukturierten Aufgaben – etwa klassischen Rechenproblemen – setzen Modelle relativ viele unterschiedliche Bausteine ein. Werden die Aufgaben unklarer, etwa bei offenen Fallanalysen oder Dilemmata, verengen sie ihr Verhalten jedoch. Dann dominieren lineares Abarbeiten, einfache Plausibilitätschecks und das Nach-vorne-Denken von gegebenen Fakten aus, berichten die Autor:innen.
Eine statistische Auswertung zeigt jedoch, dass erfolgreiche Lösungen auf solchen Aufgaben eher mit mehr Vielfalt verbunden sind: mit hierarchischer Strukturierung, dem Aufbau von Ursache-Wirkungs-Netzen, Rückwärtsschlüssen vom Ziel aus und bewussten Reframing-Schritten. In den menschlichen Denkprotokollen tauchen solche Muster deutlich häufiger auf: Sie benennen ihr Vorgehen, bewerten Zwischenergebnisse, wechseln flexibler zwischen Strategien und Darstellungsformen.
Anschaulich wird das in den im Paper dokumentierten Beispielen. In einem logischen Checkerboard-Problem kommt ein Mensch mit einem relativ kurzen Argument zum Ziel, das auf einer knappen Abstraktion der Farbverteilung beruht. Ein DeepSeek-R1-Trace dagegen umfasst mehr als 7.000 Tokens, listet koordinatenweise Felder auf, schwenkt mehrfach zwischen Hypothesen hin und her und versucht wiederholt Verifikation, bevor sich eine abstraktere Einsicht abzeichnet.
Bei einer offenen Designaufgabe zur Gesundheitsreform zerlegt eine menschliche Versuchsperson das Problem explizit in Teilziele, benennt die gewählte Strategie, bewertet Quellen nach Glaubwürdigkeit, fokussiert relevante Informationen, ordnet unterschiedliche Gesundheitssysteme nach Kriterien, abstrahiert daraus eine zusammengesetzte Bewertung und reflektiert am Ende, dass das Ergebnis überraschend ist. Der entsprechende DeepSeek-R1-Trace nutzt zwar ebenfalls Problemzerlegung und kausale Überlegungen, zeigt aber kaum explizite Strategiewechsel, Selbstreflexion oder Repräsentationswechsel, so die Autor:innen.
In der aggregierten Auswertung resultiert daraus ein klares Muster: Menschen setzen häufiger Meta-Kognition und abstrakte Verarbeitung ein und wechseln flexibler zwischen Repräsentationen, während LLMs zu langen, sequenziellen Ketten mit vielen Wiederholungen tendieren.
Ob die Ergebnisse auch für proprietäre Reasoning-Modelle großer Anbieter wie OpenAI gelten, ist allerdings unklar. Es ist gut vorstellbar, dass der üblicherweise starke Einsatz automatisch erzeugter Reasoning-Traces dazu beiträgt, dass offene Modelle in eine Art sequenziellen Autopiloten verfallen. Ob sich proprietäre Modelle, die intensiver mit menschlichen Denkspuren trainiert werden, systematisch anders verhalten, bleibt eine offene Frage, die die Studie selbst nicht beantwortet.
Vorgegebene Denkpfade helfen nur starken Modellen
Das Team testet auch, ob sich aus den erfolgreichsten Mustern praktische Prompts bauen lassen. Aus typischen Erfolgsstrukturen leiten sie Anweisungen ab, die den Denkprozess vorgeben – etwa zuerst relevante Informationen auswählen, dann eine Struktur aufbauen und erst danach Schlüsse ziehen.
Modelle wie Qwen3-14B, Qwen3-32B, R1-Distill-Qwen-14B/32B, R1-Distill-Llama-70B und Qwen3-8B verbessern ihre Genauigkeit im Mittel deutlich, teilweise um mehr als 20 Prozent relativ. Auf Dilemmata und Case Analysis-Aufgaben steigt die Genauigkeit in einzelnen Fällen um bis zu 60 Prozent. Besonders profitieren komplexe, schlecht strukturierte Problemtypen wie Dilemma, Diagnosis-Solution und Case Analysis.
Bei kleineren oder weniger leistungsfähigen Modellen kehrt sich der Effekt dagegen teilweise um. Hermes-3-Llama-3-8B und DeepScaleR-1.5B verzeichnen im Durchschnitt zweistellige relative Einbußen und brechen auf einigen gut strukturierten Aufgaben um 70 Prozent ein. Auch R1-Distill-Qwen-7B und OpenThinker-32B reagieren gemischt, mit Gewinnen in manchen und Verlusten in anderen Kategorien.
Die Autor:innen folgern daraus, dass es offenbar eine Fähigkeits-Schwelle gibt: Nur Modelle mit ausreichend starken Reasoning- und Instruktionskompetenzen können detaillierte kognitive Leitplanken sinnvoll nutzen. Zudem deuten die Ergebnisse darauf hin, dass zusätzliche Strukturhinweise bei gut strukturierten Problemen weniger bringen und mit gelernten Heuristiken kollidieren können. Ob die Guidance tatsächlich latente Fähigkeiten freilegt oder vor allem das Abrufen trainierter Muster optimiert, bleibt laut Studie offen.
Die Community optimiert, was leicht messbar ist
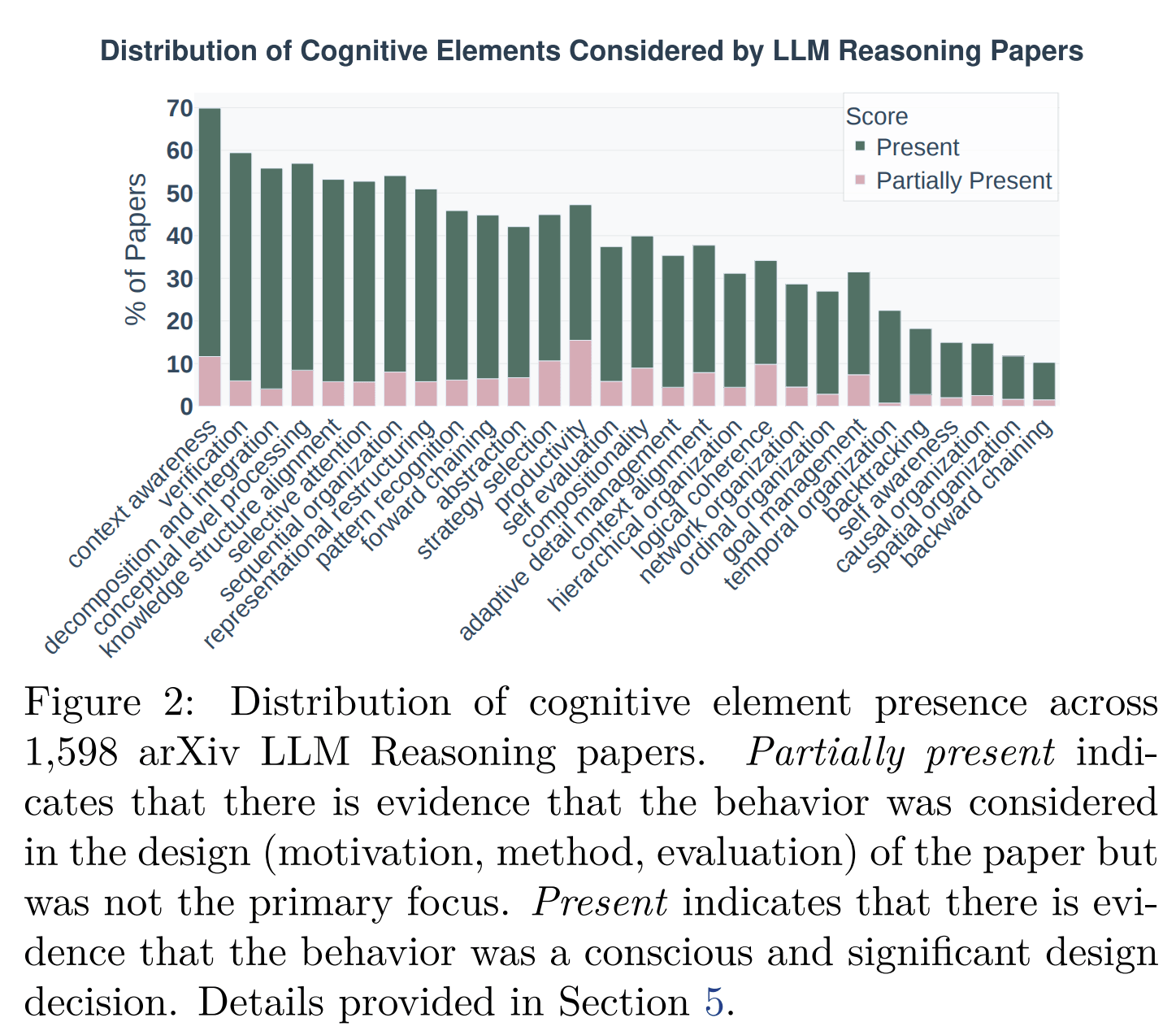
Eine zusätzliche Meta-Analyse von 1.598 arXiv-Papers zeigt zudem, dass die LLM-Reasoning-Forschung bislang vor allem gut messbare Muster wie Schritt-für-Schritt-Erklärungen und Problemzerlegung untersucht. Meta-Kognition sowie räumliche und zeitliche Organisation spielen dagegen selten eine Rolle - obwohl die empirische Analyse der Reasoning-Traces nahelegt, dass gerade sie für schwierige, schlecht strukturierte Probleme entscheidend sind, wie die Studie hervorhebt.
Insgesamt arbeite die LLM-Reasoning-Forschung daher bisher primär mit einem engen, auf linearer Zerlegung basierenden Begriffsapparat, der viele relevante kognitive Phänomene ausblende.
Was die Studie für die nächste Generation von Reasoning-Modellen bedeutet
Aus den Befunden leiten die Forschenden mehrere Herausforderungen und Chancen ab. Erstens fehle bislang eine Theorie, die Trainingsverfahren systematisch mit entstehenden kognitiven Fähigkeiten verknüpfe. Erfahrungen aus der Kognitionspsychologie legen nahe, dass prozedurale Fähigkeiten durch Wiederholung entstehen, Meta-Kognition jedoch explizite Reflexion über den eigenen Denkprozess erfordert. Übertragen auf LLMs könnte das bedeuten, dass Standard-RL-Setups Verifikation fördern, aber kaum Selbstüberwachung und Strategiewechsel, argumentiert das Team im Paper.
Zweitens zeigt die Studie, dass LLMs zwar bei klaren Aufgaben wie Story Problems oder Faktenabfragen gut abschneiden, aber bei ähnlich aufgebauten, aber weniger klaren Design- oder Diagnoseaufgaben große Schwierigkeiten haben. In der Kognitionsforschung gilt: Wer wirklich flexibel denken will, muss abstrakte Regeln aus vielen verschiedenen Aufgabenformen ableiten. Die Forschenden schlagen deshalb vor, LLMs in Zukunft gezielt mit Trainingsdaten zu konfrontieren, die strukturell unterschiedlich sind, und ihnen beizubringen, Aufgabenformen miteinander zu vergleichen.
Drittens warnen die Autor:innen, dass man aus den erzeugten Lösungsschritten der Modelle noch nicht erkennen kann, ob sie wirklich verstanden haben oder einfach Muster wiederholen. Um das zu prüfen, brauche es spezielle Tests, die zeigen, ob ein Modell sein Wissen flexibel auf neue Situationen übertragen kann, sowie genauere Analysen, wie das Modell intern arbeitet.
Viertens sehen die Forschenden ihre vorgeschlagene Landkarte als Werkzeug, um das Training von LLMs gezielter zu steuern. So könnten zum Beispiel Belohnungen im Reinforcement Learning so gestaltet werden, dass Modelle gezielt seltene, aber wichtige Denkweisen wie Reframing oder Metakognition lernen.
Code und Daten will das Team auf GitHub und Hugging Face bereitstellen.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.