Sprachmodelle scheitern bei komplexen Theory-of-Mind-Tests von Meta

Metas ExploreToM ist ein Framework für Theory-of-Mind-Daten - und zeigt, dass selbst aktuelle Spitzenmodelle wie Llama-3.1-70B und GPT-4o bei anspruchsvollen ToM-Szenarien versagen.
Laut einer Studie von Forschern von Metas FAIR sowie der Universitäten Washington und Carnegie Mellon ist es schwierig, das Theory-of-Mind-Verständnis (ToM) von großen Sprachmodellen (LLM) robust zu bewerten. Theory of Mind bezieht sich auf die Fähigkeit, die Absichten, Ziele, Gedanken und Überzeugungen anderer zu verstehen und ist eine Grundlage der sozialen Intelligenz.
Vorhandene Datensätze sind laut dem Team jedoch zu einfach und könnten zu einer Überschätzung der Fähigkeiten der Modelle führen. In früheren Tests haben Modelle wie GPT-4 Bestwerte geliefert und immer wieder zu Behauptungen geführt, dass Sprachmodelle eine ToM entwickelt hätten. Wahrscheinlicher ist jedoch, dass sie von der narrativen Praxis der ToM gelernt haben und mit dieser Fähigkeit simple ToM-Tests bestehen.
Um dieses Problem zu lösen, stellen die Forscher ExploreToM vor, das erste Framework, das die Generierung vielfältiger und herausfordernder ToM-Daten in großem Maßstab ermöglicht. Der Ansatz verwendet einen Suchalgorithmus mit einer speziellen domänenspezifischen Sprache, um komplexe Handlungsabläufe und neuartige, vielfältige, aber plausible Szenarien zu erzeugen, mit denen die Grenzen von LLMs getestet werden können.
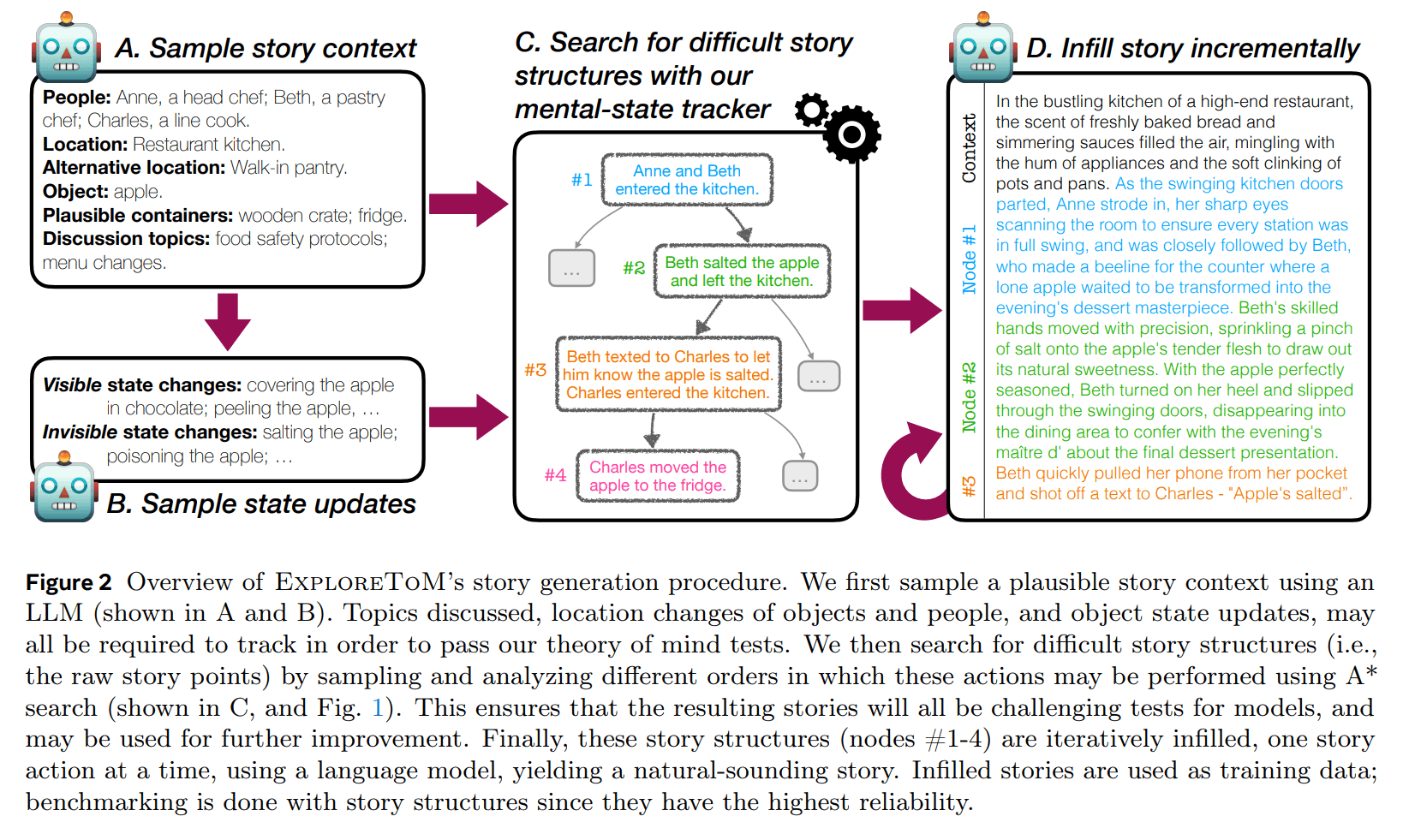
Die Forscher zeigen, dass selbst Spitzenmodelle wie Llama-3.1-70B, Mixtral 7x8B und GPT-4o an den mit ExploreToM generierten Daten immer wieder scheitern. Ihre Genauigkeit sank in den Tests auf bis zu 0 Prozent für Mixtral und Llama und bis zu 9 Prozent für GPT-4o.
ExploreToM-Daten eignen sich auch zum Finetuning von Sprachmodellen
Die Studie zeigt, dass die Methode auch für die Erstellung komplexer und vielfältiger ToM-Trainingsdaten verwendet werden kann. Eine Feinabstimmung von Llama-3.1 8B Instruct mit ExploreToM-Daten führte zu einer Verbesserung der Genauigkeit um 27 Punkte im klassischen ToMi-Benchmark.
Die Forscher zeigen auch, dass LLMs Schwierigkeiten mit dem einfachen Zustandsverfolgen haben - eine grundlegende Fähigkeit, die dem ToM-Reasoning zugrunde liegt. Es bezieht sich auf die Fähigkeit, den Zustand der Welt und die Überzeugungen der Beteiligten über diesen Zustand im Verlauf einer Geschichte oder Interaktion zu verfolgen.
Die von ExploreToM generierten Fragen werden daher etwa zu gleichen Teilen in interessante Fragen, die ToM einschließlich State-Tracking erfordern, und uninteressante Fragen, die nur State-Tracking erfordern, unterteilt. Die Forscher zeigen, dass die untersuchten Sprachmodelle bei reinen State-Tracking-Fragen noch schlechter abschneiden als bei ToM-Fragen. Dies deutet darauf hin, dass die Verbesserung des State-Tracking ein entscheidender Schritt sein könnte, um Sprachmodelle mit besseren ToM-Fähigkeiten auszustatten.
Andererseits zeigten die Experimente, dass für eine gezielte Verbesserung der ToM-Fähigkeiten durch Feintuning Daten verwendet werden sollten, die explizit ToM erfordern, und nicht nur State-Tracking. Alle Daten gibt es auf Hugging Face.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.