Studie deckt massive Schwächen in KI-Benchmarks auf

Ein internationales Forschungsteam hat die Validität von Large-Language-Model-Benchmarks systematisch untersucht und dabei erhebliche Mängel aufgedeckt. Die Analyse von 445 Benchmark-Artikeln aus führenden KI-Konferenzen zeigt, dass fast alle Bewertungsverfahren fundamentale methodische Schwächen aufweisen.
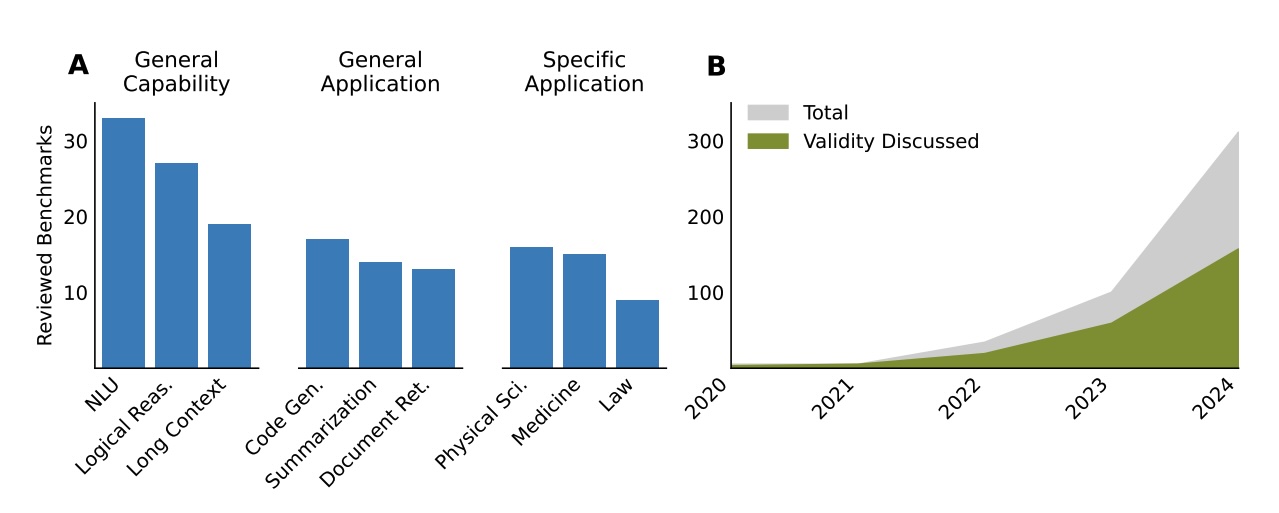
"Fast jeder Artikel hat Schwächen in mindestens einem Bereich", schreiben die Autor:innen in ihrer umfassenden Studie. Sie arbeiteten dabei mit 29 Expert:innen als Reviewer zusammen und untersuchten Benchmarks von renommierten Machine-Learning- und NLP-Konferenzen: ICML, ICLR, NeurIPS, ACL, NAACL und EMNLP aus den Jahren 2018 bis 2024.
Bei der Validität geht es darum, ob ein Test tatsächlich das misst, was er zu messen vorgibt. Ein Benchmark mit hoher Validität bedeutet, dass ein Modell mit guten Ergebnissen die behauptete Fähigkeit tatsächlich besitzt.
Definitionen oft umstritten oder unvollständig
Auffällig ist der Umgang mit Phänomendefinitionen. Zwar liefern 78,2 Prozent der Benchmarks Definitionen für das gemessene Phänomen, doch sind 47,8 Prozent davon umstritten oder unklar. Die Autor:innen stellen fest, dass Schlüsselkonzepte wie "Reasoning", "Alignment" oder "Sicherheit" oft schlecht definiert sind, was die Zuverlässigkeit der Schlussfolgerungen begrenzt.
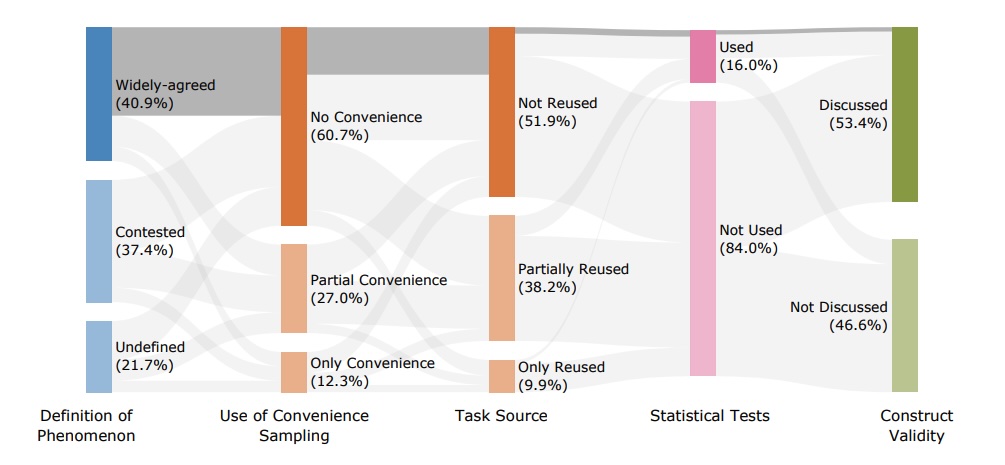
Dabei messen 61,2 Prozent der Benchmarks zusammengesetzte Phänomene wie "agentic capabilities", die sowohl Intentionserkennung als auch strukturierte Ausgabegenerierung umfassen. Die Forschenden kritisieren, dass bei solchen Benchmarks die Teilkomponenten oft nicht separat bewertet würden, was die Interpretation erschwere.
Ein weiteres Problem: 40,7 Prozent aller Benchmarks verwenden künstlich konstruierte Aufgaben, 28,5 Prozent sogar ausschließlich. Nur etwa 10 Prozent nutzen vollständige reale Aufgaben, die tatsächliche Anwendungsszenarien widerspiegeln.
Bequeme Stichprobenauswahl untergräbt Aussagekraft
Kritisch bewerten die Forschenden auch die Stichprobenauswahl. Insgesamt nutzten 39,3 Prozent der Benchmarks sogenanntes Convenience Sampling, davon 12,3 Prozent sogar ausschließlich. Sie greifen also auf leicht verfügbare Datensätze zurück, ohne deren Repräsentativität unbedingt zu prüfen.
Daten aus menschlichen Prüfungen und anderen bereits existierenden Quellen wurden in 38,2 Prozent der Benchmarks wiederverwendet. Noch häufiger recycelten die Autor:innen Daten aus anderen Benchmarks.
Die Wissenschaftler:innen erklären das Problem am Beispiel der AIME-Prüfung: Wenn ein Benchmark Fragen aus einer taschenrechnerfreien Prüfung wiederverwendet, wurden die Zahlen so gewählt, dass sie einfache Arithmetik ermöglichen. Tests nur mit solchen Problemen würden die Leistung bei größeren Zahlen nicht vorhersagen, wo LLMs Schwierigkeiten haben.
Statistische Validierung vernachlässigt
Die metrische Bewertung zeigt weitere Schwächen. Bei 81,3 Prozent der Benchmarks kam exakte Übereinstimmung zumindest teilweise als Metrik zum Einsatz, nur 16 Prozent nutzen statistische Tests zum Modellvergleich. Die Forschenden betonen, dass robuste statistische Methoden für LLM-Benchmarking kritisch seien.
Lediglich 17,1 Prozent setzen LLM-as-a-Judge ein, 13 Prozent menschliche Bewertungen. Nur 16 Prozent nutzten Unsicherheitsschätzungen oder statistische Tests zum Modellvergleich; entsprechende Angaben fehlen also in der großen Mehrheit.
Acht Empfehlungen für bessere Benchmarks
Das Forschungsteam entwickelte acht Kernempfehlungen zur Verbesserung der Benchmark-Validität:
- Forschende sollen präzise und operative Definitionen für gemessene Phänomene erstellen und deren Umfang klar abgrenzen.
- Benchmarks sollen nur das Zielphänomen messen und unabhängige Aufgaben sowie Formatbeschränkungen kontrollieren.
- Datensätze sollen durch strategische Stichprobenauswahl entstehen statt durch bequemes Sampling verfügbarer Daten.
- Autor:innen sollen Limitationen bei der Wiederverwendung von Datensätzen dokumentieren und rechtfertigen.
- Tests sollen prüfen, ob Benchmark-Aufgaben bereits in den Trainingsdaten der Sprachmodelle enthalten waren. Zusätzlich sollen geheime Testdatensätze für kontinuierliche, unverfälschte Evaluierungen vorgehalten werden.
- Statistische Methoden mit Unsicherheitsschätzungen sollen für robuste Modellvergleiche genutzt werden.
- Eine qualitative und quantitative Fehleranalyse soll häufige Ausfallmuster identifizieren und bewerten.
- Die Relevanz des Benchmarks soll durch klare Begründung der Designentscheidungen gerechtfertigt werden.
GSM8K zeigt Verbesserungspotenzial
Am Beispiel des weitverbreiteten GSM8K-Benchmarks demonstriert das Forschungsteam seine Empfehlungen. GSM8K definiert sich als Test für mathematisches Reasoning durch Grundschul-Arithmetik, vermischt aber Leseverständnis und logisches Denken ohne separate Bewertung.
Die Autor:innen stellen fest, dass eine Kontaminationsprüfung wahrscheinlich die Leistungssteigerungen über die Zeit teilweise hätte vermeiden können. Auch eine Fehleranalyse hätte die Nützlichkeit des Benchmarks erhöht.
Dass Benchmarks nur begrenzte Aussagekraft besitzen, hatte schon die Kontroverse um Messungen bei Llama 4 gezeigt. Metas neue KI-Modelle erzielten bei Standard-Benchmarks zunächst hervorragende Ergebnisse, versagten aber bei komplexen Langkontext-Aufgaben mit nur 28,1 Prozent Genauigkeit fast völlig. Zudem stellte sich heraus, dass Meta eine speziell auf menschliche Bewertungen optimierte "experimentelle Chat-Version" für den LMArena-Benchmark verwendet hatte, was die Manipulierbarkeit von Bewertungsverfahren verdeutlicht.
Trotz aller aufgedeckten Schwächen bleiben Benchmarks ein unverzichtbares Werkzeug für die KI-Forschung. Sie ermöglichen es erst, den schrittweisen Fortschritt von Sprachmodellen systematisch zu dokumentieren und verschiedene Ansätze miteinander zu vergleichen.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.