Studie zeigt, warum Reasoning-Modelle oft weit über die Lösung hinausdenken

Große Reasoning-Modelle denken oft weit über die korrekte Lösung hinaus – mit Gegenproben, Umformulierungen und redundanten Bestätigungen. Eine neue Studie von Bytedance zeigt, dass die Modelle eigentlich wissen, wann sie fertig sind, die gängigen Sampling-Verfahren sie aber zum Weiterdenken zwingen.
Neu ist das Problem nicht: Auf dem Benchmark AIME 2025 produziert Deepseek-R1 laut den Forschenden Antworten, die fast fünfmal länger sind als die von Claude 3.7 Sonnet, bei vergleichbarer Genauigkeit. QwQ-32B liefere mit den kürzesten Antworten zwei Prozentpunkte mehr Genauigkeit bei 31 Prozent weniger Token. Und in 72 Prozent der Fälle, in denen sowohl korrekte als auch falsche Antworten generiert wurden, sei die längere Antwort häufiger die falsche gewesen.
Die Lösung steht längst da, das Modell redet trotzdem weiter
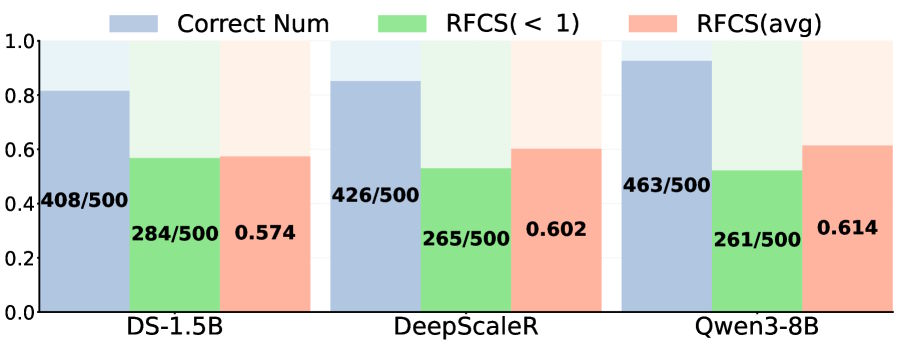
Um das Problem messbar zu machen, führen die Forschenden die Metrik RFCS (Ratio of the First Correct Step) ein. Sie erfasst, an welchem Schritt einer Gedankenkette die korrekte Antwort erstmals erscheint, im Verhältnis zur Gesamtlänge. Auf dem MATH-500-Benchmark stehe bei mehr als der Hälfte der korrekt beantworteten Aufgaben die richtige Lösung deutlich vor dem Ende.
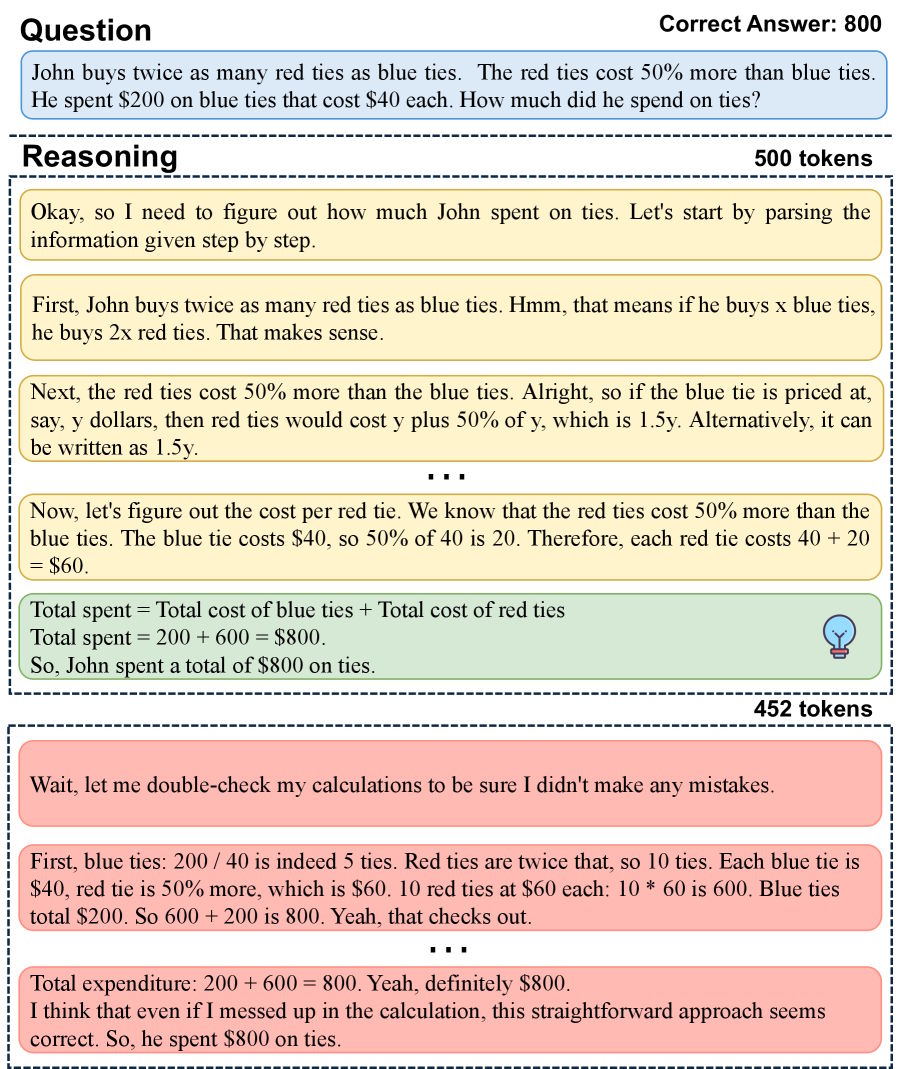
In einem Beispiel leitete das Modell die Antwort nach 500 Token ab, erzeugte dann aber weitere 452 überflüssige Token mit Gegenproben, Umformulierungen und erneuten Bestätigungen. Dieses Muster betreffe sowohl kleinere Modelle wie Deepseek-R1-Distill-Qwen-1.5B als auch leistungsfähigere wie Qwen3-8B. Stärkeres Post-Training ändere daran nichts Wesentliches.
Die Modelle wissen es, die Sampling-Verfahren nicht
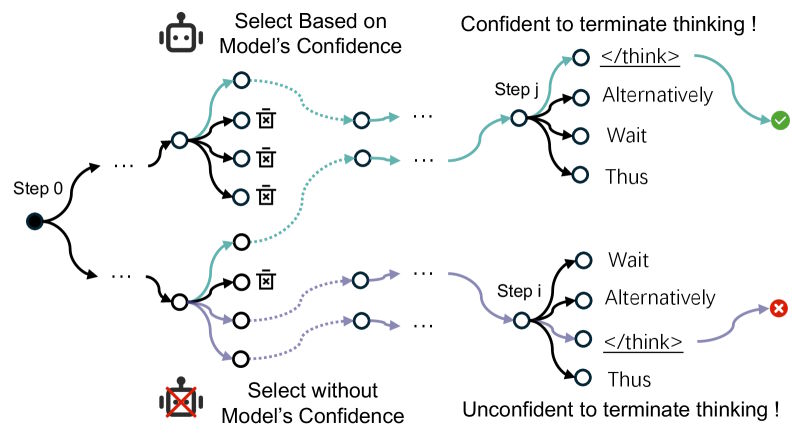
Der eigentliche Befund liegt eine Ebene tiefer. Lässt man das Modell während der Inferenz mehrere alternative Gedankenketten gleichzeitig verfolgen statt nur eine einzige, identifiziert es zuverlässig kurze, präzise Denkpfade, denen es selbst hohe Konfidenz zuweist. Die Forschenden zeigen das mit einem Verfahren namens TSearch, das nicht die Wahrscheinlichkeit einzelner Token bewertet, sondern die durchschnittliche Wahrscheinlichkeit über die gesamte bisherige Kette hinweg.
Drei Beobachtungen stützen die These: Die so selektierten Pfade führen zu kürzeren und gleichzeitig genaueren Antworten. Am Endpunkt solcher Pfade rangiert das Abbruchsignal konsistent auf Platz eins der wahrscheinlichsten nächsten Token – das Modell ist sich also sicher, dass es fertig ist. Und je mehr parallele Pfade man zulässt, desto stabiler wird dieses Verhalten. Die Fähigkeit zur effizienten Terminierung steckt also bereits in den Modellen, wird aber von gängigen Sampling-Verfahren schlicht nicht abgerufen.
SAGE: Schrittweise Exploration statt Token für Token
Darauf aufbauend stellen die Forschenden SAGE (Self-Aware Guided Efficient Reasoning) vor. Statt Token für Token zu expandieren, erweitert SAGE die Gedankenkette um ganze Reasoning-Schritte und prüft nach jedem Schritt, ob das Modell selbst signalisiert, dass die Lösung steht. Ist das der Fall, wird der Denkprozess beendet.
In den Experimenten zeige SAGE ein aufschlussreiches Verhalten: Bei starken Modellen und schwierigen Benchmarks steige primär die Genauigkeit, bei schwächeren Modellen und einfacheren Aufgaben sinke vor allem die Antwortlänge. Wo das Modell unter Overthinking leide, kürze SAGE ab. Wo noch Kapazität für bessere Lösungen liege, finde SAGE sie.
Effiziente Denkmuster dauerhaft einbrennen
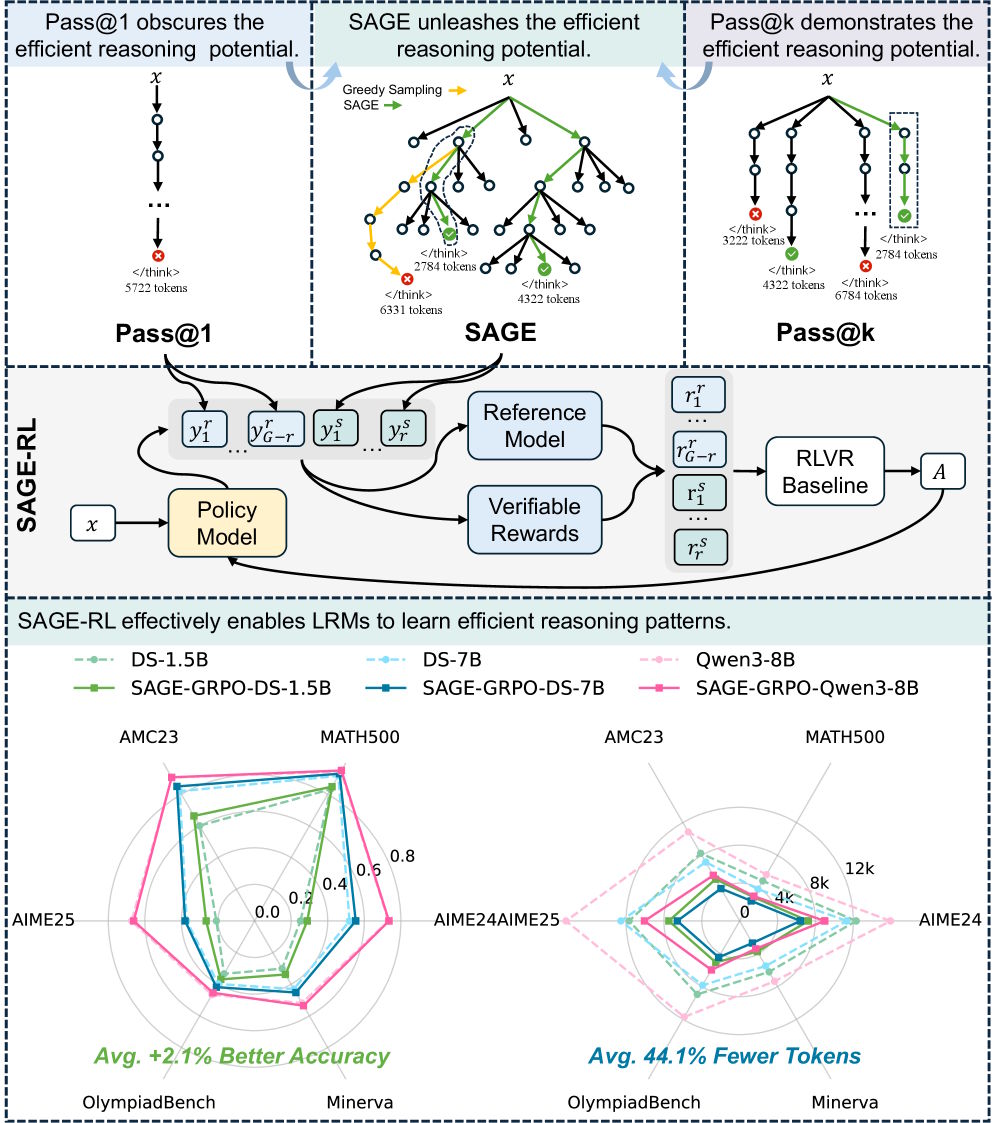
Um diese Muster dauerhaft in die Modelle zu integrieren, schlagen die Forschenden SAGE-RL vor, eine minimale Modifikation gängiger Reinforcement-Learning-Verfahren. Von acht Antworten pro Trainingsgruppe werden lediglich zwei durch SAGE generiert, die restlichen sechs durch Standard-Sampling. So lernt das Modell über den Vorteilsschätzer, die präziseren Denkpfade zu bevorzugen.
Die Ergebnisse auf sechs Mathematik-Benchmarks, darunter MATH-500, AIME 2024 und 2025 sowie OlympiadBench, fallen laut den Forschenden klar aus: Während Methoden wie LC-R1, ThinkPrune oder AdaptThink die Token-Anzahl nur auf Kosten der Genauigkeit reduzierten, verbessere SAGE-RL beides gleichzeitig. Auf Deepseek-R1-Distill-Qwen-7B erreiche SAGE-GRPO 93 Prozent auf MATH-500 statt 91,6 Prozent bei einer Reduktion der Antwortlänge von 3.871 auf 2.141 Token.
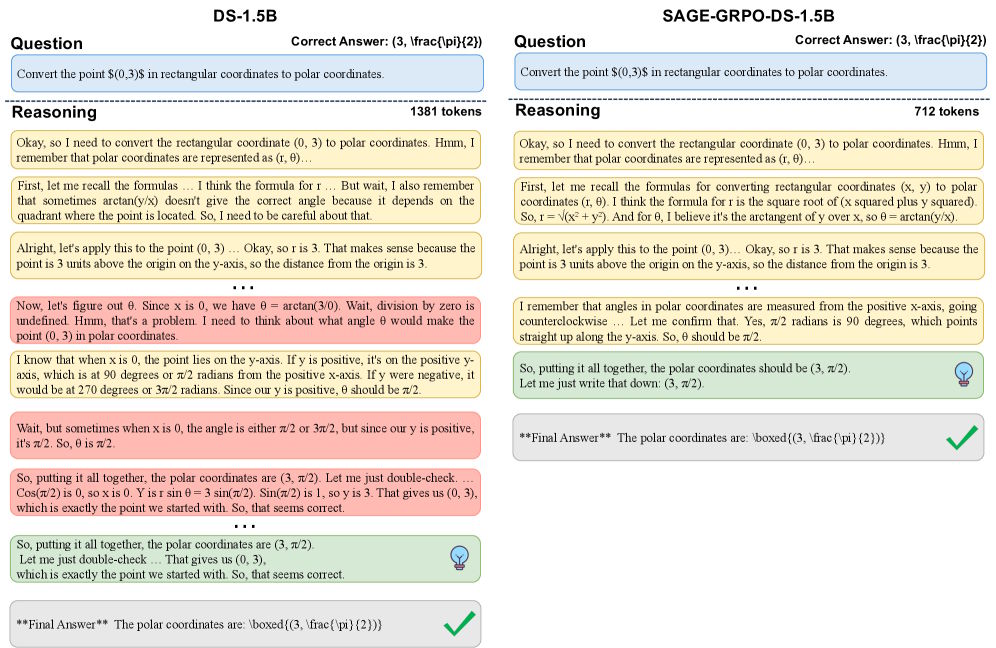
Auf AIME 2025 steige die Genauigkeit von DS-1.5B um 6,2 Prozentpunkte. Selbst bei Qwen3-8B, einem der stärksten Modelle seiner Größenklasse, halbiere SAGE-GRPO die Antwortlänge auf AIME 2025 von 18.342 auf 9.183 Token bei vergleichbarer Genauigkeit. Die Inferenzzeit sinke bei der Mehrzahl der Modelle und Benchmarks um mehr als 40 Prozent.
Auf besonders schwierigen Aufgaben zeige SAGE-RL die größten Verbesserungen, was darauf hindeute, dass gerade dort das Potenzial für effizienteres Reasoning am größten sei. Die Studie legt nahe, dass die Lösung für das Overthinking-Problem nicht in neuen Architekturen oder aufwendigeren Belohnungsfunktionen liegen muss – möglicherweise genügt es, den Modellen zuzuhören, wenn sie signalisieren, dass sie fertig sind.
Das Overthinking-Problem von Reasoning-Modellen beschäftigt die Forschung seit einiger Zeit. Bereits vor rund einem Jahr hatte eine Studie gezeigt, dass übermäßiges "Nachdenken" in interaktiven Szenarien die Leistung erheblich beeinträchtigt. Kürzlich legten Google-Forschende dar, dass Reasoning-Modelle ihre Gedankenketten als interne Debatten zwischen simulierten Perspektiven strukturieren. Was die Genauigkeit zwar verbessert, aber auch erklärt, warum die Denkprozesse so lang ausfallen.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.