Tencents Open-Source-Modell Hunyuan-A13B kombiniert schnelles und langsames "Denken"
Der chinesische Technologiekonzern Tencent hat sein neues Sprachmodell Hunyuan-A13B als Open Source veröffentlicht. Das Modell soll mit dynamischem Reasoning zwischen schnellem und langsamem Denken wechseln können.
Das zentrale Feature von Hunyuan-A13B ist ein System, das die Denktiefe dynamisch an die Aufgabenkomplexität anpasst. Das Modell bietet zwei Modi: einen schnellen Modus für einfache Anfragen mit kurzer Inferenz und einen tiefergehenden Modus für komplexe Aufgaben, die mehrstufiges Denken erfordern.
Im Standard-Modus führt das Modell ausführliche Denkprozesse durch, bevor es eine Antwort generiert. Der schnelle Modus überspringt diese Schritte. Nutzer:innen können das Verhalten über spezielle Befehle steuern: "/think" aktiviert den Denkmodus, "/no_think" deaktiviert ihn.
Das Modell basiert auf einer Mixture-of-Experts-Architektur (MoE) mit insgesamt 80 Milliarden Parametern, von denen bei Inferenz jedoch nur 13 Milliarden aktiv sind. Das Modell kann Texte mit bis zu 256.000 Tokens verarbeiten.
Training mit wissenschaftlichem Fokus
Laut dem technischen Bericht wurde Hunyuan-A13B zunächst auf 20 Billionen Tokens trainiert, dann speziell auf Reasoning-Aufgaben optimiert und schließlich für allgemeine Anwendungen verfeinert. Tencent sammelte dabei 250 Milliarden Tokens aus STEM-Bereichen, um die Zuverlässigkeit bei wissenschaftlichen Aufgaben zu verbessern.
Video: Tencent
Diese Trainingsdaten stammen aus Lehrbüchern, Tests und Wettbewerben für Mathematik, aus Open-Source-Code-Projekten wie GitHub, aus Puzzle-Sammlungen für Logik und aus wissenschaftlichen Texten von Mittelschul- bis Universitätsniveau.
Besonders gut für Agenten-Aufgaben
In eigenen Benchmarks soll Hunyuan-A13B-Instruct mit führenden Modellen von OpenAI, Deepseek und Alibaba (Qwen) mithalten können. Laut Tencent erreicht das Modell in Aufgaben wie dem amerikanischen Mathematik-Wettbewerb AIME (2024) 87,3 Prozent korrekte Antworten, während OpenAI o1 bei 74,3 Prozent liegt. Wie wenig aussagekräftig solche Angaben jedoch teilweise sind, zeigt schon ein Blick auf die Ergebnisse der 2025er-Ausgabe: Dort liegt o1 nämlich um knapp drei Prozent vorn.
Außerdem scheint Tencent sich die Benchmarks etwas zurechtzubiegen, da man zum Vergleich die veraltete Januar-Version von Deepseek-R1 heranzieht. In AIME 2024 und AIME 2025 erreichte die Version aus dem Mai 91,4 respektive 87,5 Punkte.
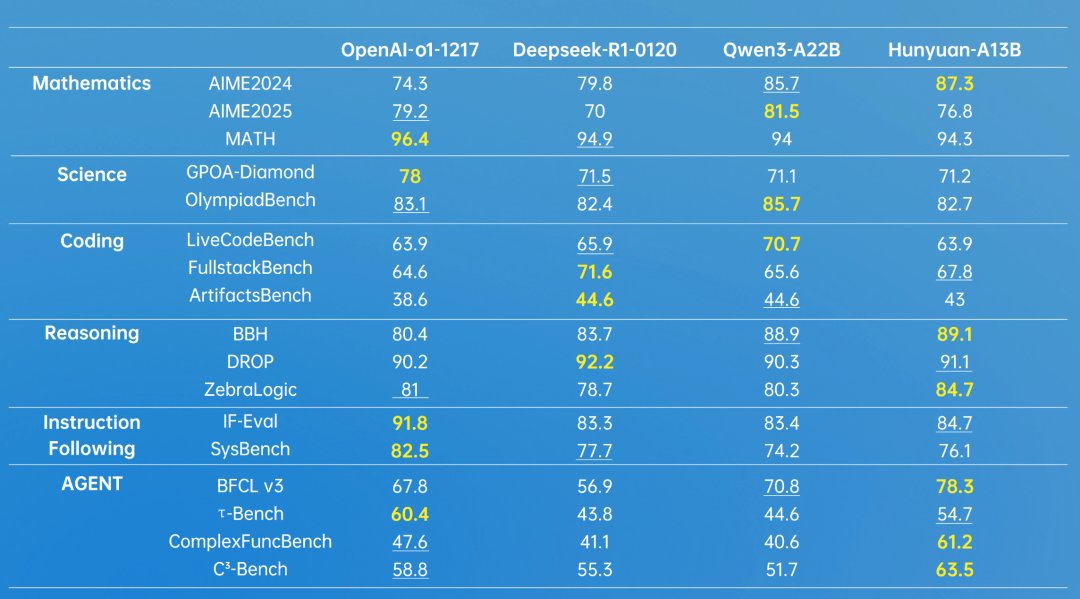
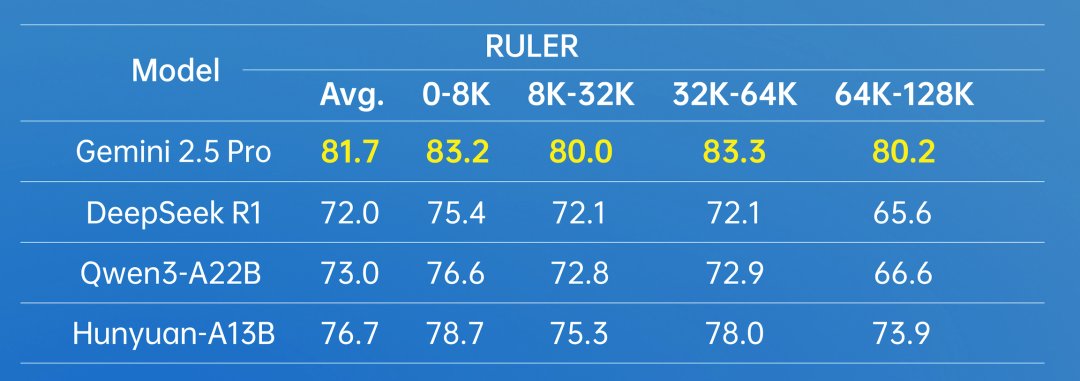
Besonders stark soll das Modell bei automatisierten Aufgaben und der Nutzung von Tools abschneiden. In Agenten-Benchmarks erreichte A13B beinahe durchgehend Bestwerte. Bei Tests, die das große Kontextfenster schrittweise mehr ausnutzten, blieb die Leistung besser als bei Deepseek-R1 oder Qwen3-A22B, wurde von Gemini 2.5 Pro aber sichtlich übertroffen.
Tencent hat zusätzlich zwei neue Test-Datensätze veröffentlicht: ArtifactsBench für die Bewertung von Code-Generierung und C3-Bench speziell für Agenten-Aufgaben.
Das Modell ist auf Hugging Face und GitHub unter der Apache-2.0-Lizenz verfügbar. Tencent stellt vorgefertigte Docker-Images für verschiedene Deployment-Frameworks bereit. Über Tencent Cloud ist auch ein API-Zugang verfügbar, im Browser kann man es hier testen.
Der hybride Reasoning-Ansatz zeigt, dass Tencent an ähnliche Konzepte wie andere führende KI-Unternehmen glaubt. Dieser dynamische Ansatz erinnert unter anderem an Modelle wie Claude 3.7 Sonnet und Qwen3, die ebenfalls zwischen verschiedenen Reasoning-Modi wechseln können.
Tencent hat sich vor Sprachmodellen vorrangig mit Video-Generatoren beschäftigt und dazu im Dezember 2024 HunyuanVideo vorgestellt. Im März folgte mit Hunyuan-T1 ein reines Reasoning-LLM, das laut Unternehmen bereits mit OpenAI o1 mithalten konnte.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.