Together AI stellt Open-Source-Alternative zu OpenAIs Deep Research vor

Together AI hat mit "Open Deep Research" ein offenes KI-Tool veröffentlicht, das komplexe Fragen durch strukturierte, mehrstufige Webrecherche beantworten soll.
Das System orientiert sich am Konzept des von OpenAI eingeführten „Deep Research“, geht aber bewusst einen offenen Weg: Code, Datensätze und Architektur sind frei verfügbar.
Im Gegensatz zur klassischen Websuche, bei der Nutzer:innen eine Liste von Links erhalten und selbst Informationen extrahieren müssen, liefert Deep Research strukturierte Berichte mit Zitaten, verspricht Together AI in einem Blogartikel.
Auch Google, Grok und Perplexity bieten Deep Research Funktionen, zuletzt hatte Anthropic eine Form der Funktion veröffentlicht. Kurz nach Veröffentlichung von OpenAIs Recherchewerkzeug hatte Hugging Face ebenfalls eine quelloffene Alternative vorgestellt, diese aber nicht weiterentwickelt.
Planen, suchen, reflektieren, schreiben
Der Workflow von Open Deep Research besteht aus vier Schritten: Zunächst erstellt ein Planungsmodell eine Liste relevanter Suchanfragen. Anschließend werden mithilfe der Such-API von Tavily Inhalte gesammelt. Ein Bewertungsmodell prüft, ob noch Wissenslücken bestehen, bevor ein Schreibmodell den finalen Bericht generiert.
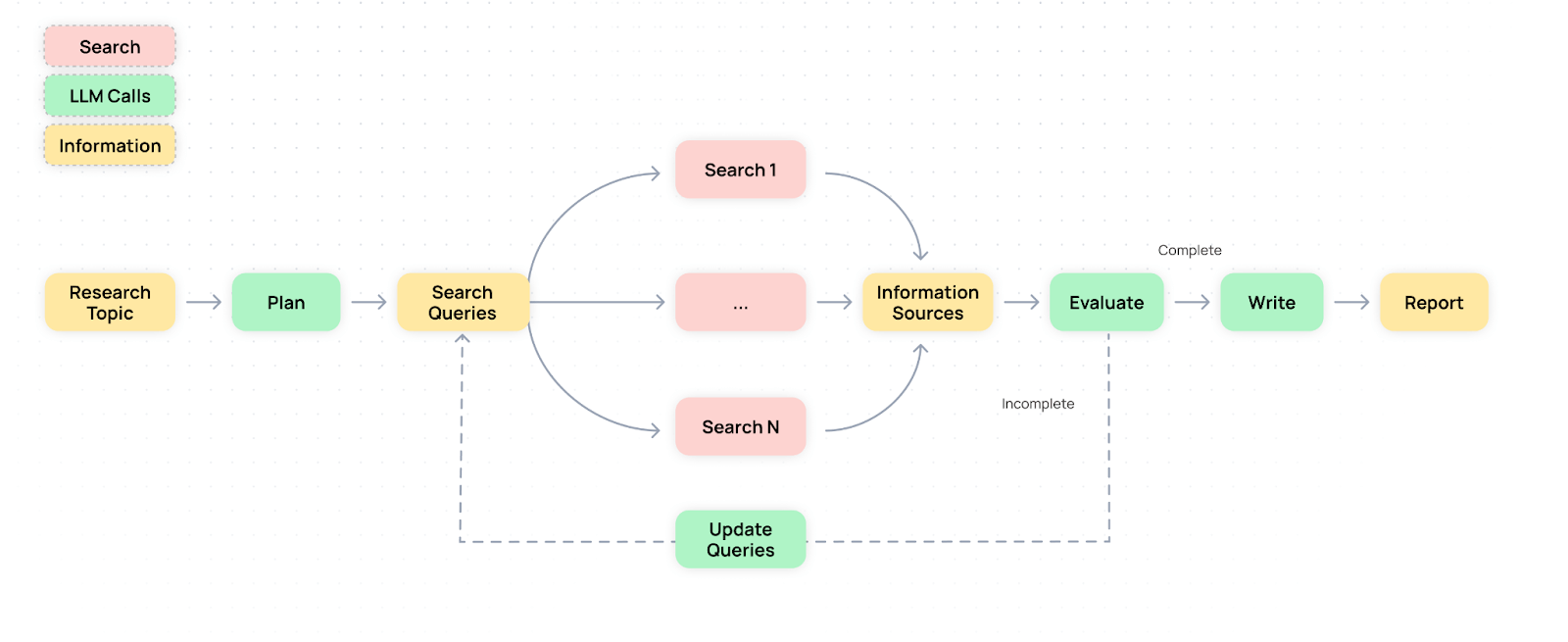
Um mit langen Texten umgehen zu können, fasst ein weiteres Modell die Inhalte zusammen und bewertet deren Relevanz. So soll vermieden werden, dass die Kontextfenster der Sprachmodelle überlaufen.
Die Architektur basiert auf einer Mischung spezialisierter Modelle von Alibaba, Meta und DeepSeek: Qwen2.5-72B für Planung, Llama-3.3-70B für Zusammenfassungen, Llama-3.1-70B für strukturierte Extraktion und DeepSeek-V3 für die Berichtserstellung. Alle Modelle werden in der eigenen Together AI Cloud gehostet.
Multimodale Ausgaben und Podcast-Funktion
Die Ausgabe erfolgt in HTML und kombiniert Text mit visuell aufbereiteten Inhalten. Neben dem Textbericht generiert das System etwa Diagramme über die Javascript-Bibliothek Mermaid JS sowie automatisch erstellte Cover-Bilder mithilfe von Black Forest Labs’ Flux-Modellen.
Die Ergebnisse können unter anderem auch als Podcast ausgegeben werden. | Video: Together AI
Zusätzlich kann ein kurzer Podcast erstellt werden, der die Inhalte des Berichts zusammenfasst, erzeugt mit Cartesias Sonic-Sprachmodellen.
Benchmarks zeigen Vorteile mehrstufiger Recherche
Für die Bewertung nutzt Together AI drei populäre Benchmarks: FRAMES (mehrstufige Logik), SimpleQA (Faktenwissen) und HotPotQA (Multi-Hop-Fragen). In allen drei Fällen schnitt Open Deep Research deutlich besser ab als Basismodelle ohne Suchwerkzeuge. Auch im Vergleich zu LangChains Open Deep Research (LDR) und Hugging Faces SmolAgents (SearchCodeAgent) erzielte das System meist höhere Antwortqualität.
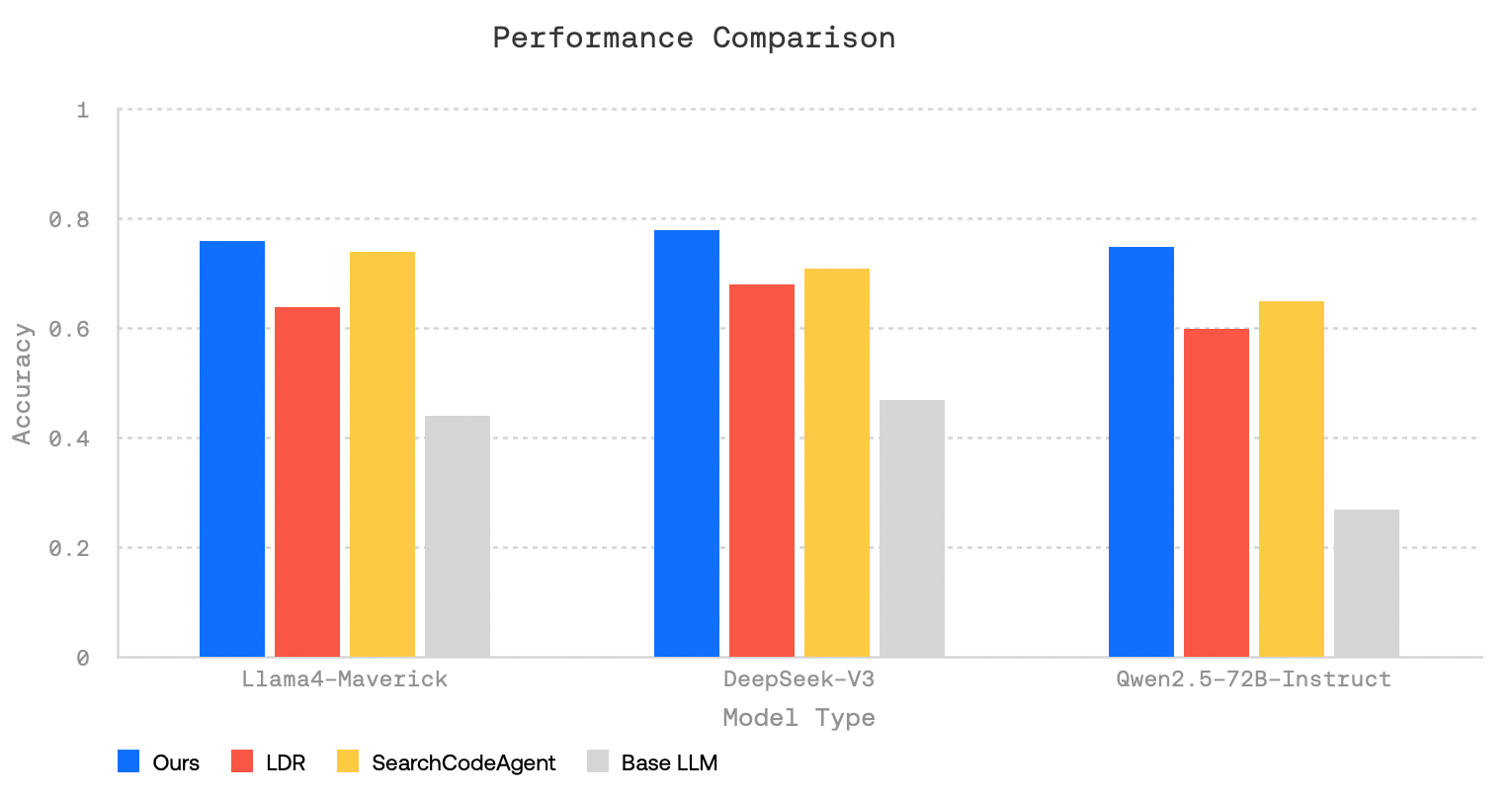
Mehrere aufeinanderfolgende Rechercheschritte verbessern die Antwortqualität signifikant. Bei Beschränkung auf einen einzigen Suchdurchlauf sank die Genauigkeit.
Bekannte Schwächen: Halluzinationen, Bias, veraltete Daten
Trotz der Fortschritte bleiben laut Together AI die üblichen Schwächen bestehen: Fehler in frühen Schritten können sich durch die gesamte Pipeline fortpflanzen. Zudem sind Halluzinationen bei der Quelleninterpretation möglich, insbesondere bei uneindeutigen oder widersprüchlichen Informationen.
Auch strukturelle Bias in Trainingsdaten oder Suchindizes können sich bekanntermaßen auf die Ergebnisse auswirken. Themen mit geringer Abdeckung oder hoher Aktualitätsanforderung sind besonders betroffen – etwa bei Live-Ereignissen. Caching könne zwar Kosten senken, führe aber dazu, dass veraltete Informationen geliefert werden, wenn keine Ablaufzeit gesetzt ist.
Offene Plattform für Community und Forschung
Together AI will mit der Veröffentlichung eine offene Grundlage schaffen, auf der weitere Experimente und Verbesserungen aufbauen können. Die Architektur sei so gestaltet, dass sie leicht erweiterbar ist. Entwickler:innen können eigene Modelle einbinden, Datenquellen anpassen oder neue Ausgabeformate ergänzen. Der vollständige Code und die Dokumentation sind öffentlich verfügbar.
Zuletzt hat Together AI unter anderem ein quelloffenes Coding-Modell auf Niveau von o3-mini präsentiert, jedoch mit deutlich weniger Parametern als die geschlossene Konkurrenz.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.