Tom und Jerry als KI-Cartoons: Neuer Algorithmus generiert einminütige Videostorys

Forscher haben eine neue Methode entwickelt, die es ermöglicht, einminütige Videos mit komplexen Geschichten zu generieren.
Während sich die Qualität von KI-generierten Videos in den letzten Monaten stetig verbessert hat, stoßen die Modelle bei der Videolänge an ihre Grenzen: OpenAIs Sora schafft maximal 20 Sekunden, Metas MovieGen 16 Sekunden und Googles Veo 2 nur 8 Sekunden. Ein Forscherteam von Nvidia, der Stanford University, der UCSD, der UC Berkeley und der UT Austin hat nun eine Lösung für dieses Problem vorgestellt: sogenannte "Test-Time Training"-Layers (TTT-Layers), die längere und zusammenhängendere Videos ermöglichen.
Das Hauptproblem bisheriger Modelle ist die sogenannte "Selbstaufmerksamkeit" in Transformer-Modellen. Dabei muss jedes Element einer Sequenz mit jedem anderen Element in Beziehung gesetzt werden. Bei längeren Videos steigt der Rechenaufwand quadratisch an. Bei einminütigen Videos mit mehr als 300.000 Token wird dies praktisch unmöglich.
Hier kommen rekurrente neuronale Netze (RNNs) ins Spiel. Im Gegensatz zu Transformer-Modellen verarbeiten RNNs Daten sequentiell und speichern Informationen in einem "versteckten Zustand" - ihr Rechenaufwand steigt nur linear mit der Sequenzlänge. Das macht sie eigentlich effizienter für lange Videos, hat aber einen entscheidenden Nachteil: Herkömmliche RNNs sind aufgrund ihrer Architektur nicht gut geeignet, komplexe Zusammenhänge über längere Sequenzen zu erfassen.
Today, we're releasing a new paper – One-Minute Video Generation with Test-Time Training.
We add TTT layers to a pre-trained Transformer and fine-tune it to generate one-minute Tom and Jerry cartoons with strong temporal consistency.
Every video below is produced directly by… pic.twitter.com/Bh2impMBWA
— Karan Dalal (@karansdalal) April 7, 2025
TTT-Layer erlauben deutlich längere Videos
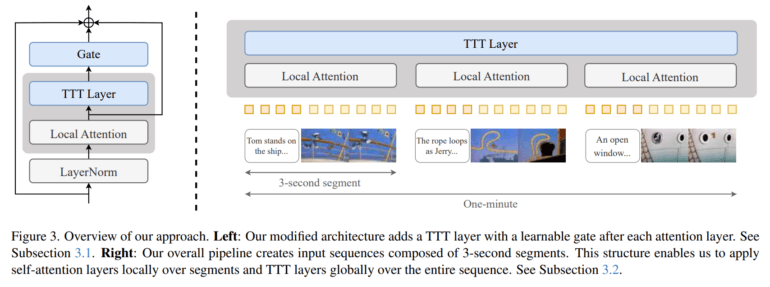
Die Innovation der Forscher besteht darin, dies zu ändern: Ihre TTT-Layer ersetzen die einfachen Hidden States herkömmlicher RNNs durch kleine neuronale Netze, die während der Videogenerierung kontinuierlich dazulernen. Die Schichten werden dann zusammen mit dem Aufmerksamkeitsmechanismus verwendet.
In jedem Verarbeitungsschritt wird dieses Mini-Netz darauf trainiert, Muster im aktuellen Bildausschnitt zu erkennen und zu rekonstruieren. Auf diese Weise entsteht ein Gedächtnis, das Zusammenhänge über längere Abschnitte hinweg viel besser erfassen kann - zum Beispiel, dass ein Raum oder eine Figur über mehrere Szenen hinweg konsistent bleiben sollte. Ein ähnlicher Ansatz des Test-Time Trainings zeigte Ende 2024 auch Erfolge im ARC-AGI-Benchmark, setzte allerdings auf LoRAs.
Für ihren Proof of Concept wählten die Forscher Tom und Jerry Cartoons. "Wir konzentrieren uns auf komplexe Geschichten mit mehreren Szenen und dynamischen Bewegungen - genau dort, wo bisherige Modelle Schwierigkeiten haben", erklären sie. Der Datensatz umfasst rund sieben Stunden Zeichentrickfilmmaterial mit detaillierten menschlichen Beschreibungen.

Nutzer können ihre Videoideen in drei verschiedenen Detailstufen beschreiben:
- Eine kurze Zusammenfassung in 5-8 Sätzen (z.B. "Tom isst glücklich einen Apfelkuchen am Küchentisch. Jerry schaut sehnsüchtig zu...")
- Eine detailliertere Handlung in etwa 20 Sätzen, wobei jeder Satz einem 3-Sekunden-Segment entspricht
- Ein ausführliches Storyboard, bei dem jedes 3-Sekunden-Segment durch einen Absatz von 3-5 Sätzen mit Details zu Hintergrund, Charakteren und Kamerabewegungen beschrieben wird
CogVideo-X mit TTT-Layer erlaubt 20-mal längere Videos
Als Ausgangspunkt diente ein vortrainiertes Modell namens CogVideo-X mit 5 Milliarden Parametern, das ursprünglich nur 3-Sekunden-Clips erzeugen konnte. Die Forscher erweiterten dieses Modell mit ihren TTT-Schichten und trainierten es schrittweise für immer längere Videos - von 3 Sekunden über 9, 18 und 30 bis hin zu 63 Sekunden.
Die rechenintensiven Self-Attention-Mechanismen werden nur auf die 3-Sekunden-Segmente angewendet, während die effizienteren TTT-Layer global über das gesamte Video arbeiten. Dadurch bleibt der Rechenaufwand überschaubar.
"Jedes Video wird von dem Modell in einem einzigen Durchgang erzeugt, ohne nachträgliche Bearbeitung oder Montage", betonen die Forscher. Die Videos erzählen zusammenhängende Geschichten über mehrere Szenen hinweg.
Dennoch zeigt auch das neue Modell Schwächen - manchmal verändern sich Objekte an Segmentübergängen, schweben unnatürlich in der Luft oder die Beleuchtung wechselt abrupt.
Alle Informationen, Beispiele und Vergleiche mit anderen Methoden gibt es auf GitHub.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.