Transformer² von Sakana AI: Sprachmodelle sollen besser dazulernen können

Das japanische KI-Unternehmen Sakana AI stellt mit Transformer² einen Ansatz für Sprachmodelle vor, die sich flexibler an neue Aufgaben anpassen können. Das Team sieht darin einen Schritt in Richtung kontinuierlich lernender KI-Systeme.
Transformer² ist ein zweistufiges Lernverfahren für große Sprachmodelle. Diese KI-Systeme werden normalerweise einmal trainiert und können dann eine Vielzahl von Aufgaben lösen - von der Textgenerierung über Zusammenfassungen bis hin zu Frage-Antwort-Systemen. Doch wenn es darum geht, sich flexibel an neue, unvorhergesehene Aufgaben anzupassen, stoßen heutige LLMs schnell an ihre Grenzen. Das will Transformer² ändern.
Dazu nutzt das Team so genannte Expertenvektoren, die es mit einer Technik namens Singular Value Fine-Tuning (SVF) trainiert. Jeder dieser Vektoren optimiert das LLM für einen bestimmten Aufgabentyp, zum Beispiel Mathematik, Programmieren oder logische Schlussfolgerungen.
Transformer² setzt auf Experten-Vektoren
Traditionell müsste für eine solche Anpassung an eine neue Aufgabe das gesamte Netz mit all seinen Gewichten angepasst werden. Dies ist jedoch mit vielen Problemen verbunden: Die Netze können alte Fähigkeiten wieder verlernen, Informationen vergessen und bei größeren Modellen ist ein erneutes Training sehr teuer. Alternative Ansätze wie LoRA versuchen diese Probleme zu umgehen, indem sie kleine Erweiterungen trainieren, die an das bestehende Netz andocken und ihm so neue Informationen hinzufügen.
SVF geht einen anderen Weg: Statt die Gewichte direkt zu verändern, lernt es Vektoren, die bestimmen, wie stark jede Verbindung im Netz berücksichtigt wird. Mathematisch gesehen skalieren diese Vektoren die Singulärvektoren der Gewichtsmatrizen - daher der Name.
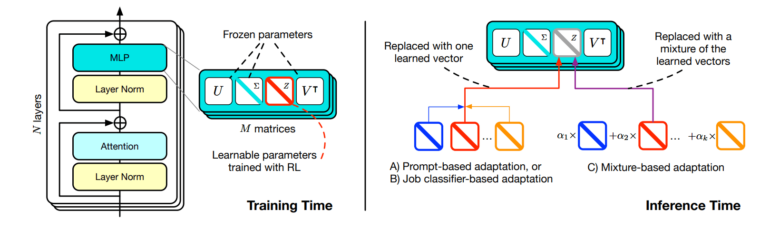
Dieser Ansatz hat mehrere Vorteile: Erstens müssen viel weniger Parameter gelernt werden, was Speicherplatz und Rechenzeit spart. Während LoRA etwa 6,82 Millionen Parameter für die Anpassung benötigt, kommt SVF mit nur 160.000 aus. Zweitens schützen die Expertenvektoren das Modell davor, sich zu sehr auf eine Aufgabe zu spezialisieren und dabei Gelerntes zu "vergessen". Und drittens sind die Experten leicht kombinierbar, was später für die Adaption auf verschiedene Aufgaben hilfreich ist.
Video: Sakana AI
Transformer² lernt die optimalen Expertenvektoren durch Reinforcement Learning. Für jede Trainingsaufgabe schlägt das Modell Lösungen vor und bekommt Rückmeldung, wie gut diese waren. Daraus leitet es ab, wie es die Expertenvektoren anpassen muss, um besser zu werden. Schritt für Schritt werden die Vektoren so optimiert, bis das Modell die Aufgabe meistert.
Few-Shot-Adaption schlägt reines Prompting
Die Forscher haben drei Strategien entwickelt, mit denen Transformer² die gelernten Experten nutzt, um sich an neue Aufgaben anzupassen.
Die erste Strategie verwendet spezielle "Adaptation Prompts", die dem Modell helfen, die Art der Aufgabe zu erkennen. Anhand dieser Beschreibung wählt Transformer² den am besten geeigneten Expertenvektor aus. Die zweite Strategie verwendet einen Klassifikator, ein Modul, das anhand einiger Beispiele die Art der Aufgabe erkennt und den richtigen Experten auswählt.
Die dritte Strategie ist die Few-Shot-Adaption. Hier kombiniert Transformer² alle gelernten Expertenvektoren zu einem neuen, maßgeschneiderten Vektor. Dazu analysiert es zunächst einige Beispiele der neuen Aufgabe. Dann probiert es viele Kombinationen der Experten aus und behält die beste. Je mehr Beispiele es gibt, desto besser kann Transformer² die Vektoren anpassen.
Transformer² schlägt LoRAs
Transformer² wurde mit verschiedenen Benchmark-Datensätzen getestet, die von Mathematik über Programmierung bis hin zu Wissens- und Verständnisfragen reichten. Als Vergleich diente das Verfahren LoRA.
Das Ergebnis: Bei Mathematikaufgaben schnitt Transformer² um bis zu 16 Prozent besser ab als LoRA - und das bei deutlich weniger Parametern. Auch bei der Anpassung an völlig neue Aufgaben zeigte sich die Stärke des Verfahrens. So erzielte es bei einem Mathematiktest eine um 4 Prozent höhere Genauigkeit als das unveränderte Ausgangsmodell. Dagegen verschlechterte sich die Leistung des zugrundeliegenden Llama-Modells mit LoRA sogar.
Die Untersuchungen zur Few-Shot-Adaption zeigten, dass Transformer² bei komplexen mathematischen Aufgaben nicht nur die mathematischen Experten, sondern auch Fähigkeiten aus dem Bereich des Programmierens und des logischen Denkens einsetzte. Es kombinierte also flexibel verschiedene Fähigkeiten.
Die Expertenvektoren konnten sogar zwischen verschiedenen Modellen übertragen werden. So konnte ein kleineres Modell von den Experten eines größeren profitieren - eine vielversprechende Möglichkeit, Wissen effizient weiterzugeben und auch kleinere Modelle zu verbessern.
Vom "Lebenslangen Lernen" ist man noch ein gutes Stück entfernt
Trotz der Fortschritte: Die Fähigkeiten der mit SVF trainierten Expertenvektoren sind weiterhin an die latenten Komponenten des Basismodells gebunden. Die Experten können also nur Fähigkeiten abbilden, die bereits im vortrainierten Modell vorhanden sind. Völlig neue Fähigkeiten können so nicht ohne weiteres hinzugefügt werden - vom "lebenslangen Lernen", bei dem ein Modell kontinuierlich dazulernt, ist die Methode also noch ein Stück weit entfernt. Auch ob das Verfahren auf größere Modelle jenseits der 70 Milliarden Parameter effizient skaliert ist noch nicht abschließend geklärt.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.