VideoControlNet gibt euch mehr Kontrolle über KI-Videos

VideoControlNet setzt auf Diffusionsmodelle und ControlNet für mehr Kontrolle über KI-generierte Videos.
Für eine bessere Kontrolle der Bildsynthese über Stable Diffusion gibt es verschiedene Erweiterungen. Eine der wichtigsten ist ControlNet. Es erlaubt beispielsweise, die Posen von Personen oder die Struktur eines Raumes aus einem Eingabebild zu extrahieren und als Vorlage für die Bildsynthese zu verwenden.
Forschende der Beihang University und der University of Hong Kong präsentieren nun VideoControlNet, eine Erweiterung, die diese Idee auf die Synthese von Videos anwendet.
Die Videosynthese mit Diffusionsmodellen ist trotz teilweise beeindruckender Ergebnisse wie Runways Gen-2 immer noch von Artefakten geprägt und schwer zu kontrollieren. VideoControlNet hingegen verwendet Prompts und ein Eingabevideo zusammen, um neue Videos zu generieren. So können Hintergründe, Belichtung oder Personen ausgetauscht werden, während die Geometrie und zeitliche Struktur des Originals erhalten bleibt.
VideoControlNet basiert auf Video-Codec-Methoden
VideoControlNet ist inspiriert von der Art und Weise, wie Videocodecs unnötig wiederholte Informationen in einer Videosequenz reduzieren. Konkret definiert das Team das erste Bild als I-Frame und teilt die folgenden Bilder in verschiedene Bildgruppen (GoPs) ein, wobei das letzte Bild jeder GoP als Schlüsselbild (P-Frame) und die anderen Bilder als B-Frames definiert werden.
Das erste Bild des Videos, das sogenannte I-Frame, wird mithilfe eines Diffusionsmodells und ControlNet erzeugt. Anschließend werden die P-Frames erzeugt, die auf Veränderungen des vorhergehenden Bildes, also des I-Frames oder anderer P-Frames, basieren. Das Team hat dafür eine Technik entwickelt, die es als bewegungsgesteuerte P-Frame-Generierung (MgPG) bezeichnet. Wenn Teile des Bildes verdeckt sind, füllt das Diffusionsmodell diese aus.
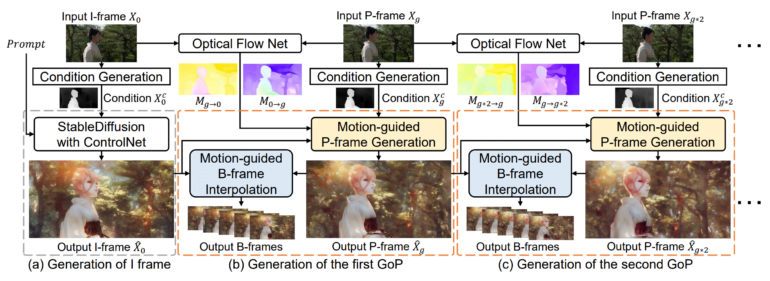
Schließlich werden alle verbleibenden Bilder, die B-Frames, mit einer Methode erzeugt, die das Team als bewegungsgesteuerte B-Frame-Interpolation (MgBI) bezeichnet. Diese B-Frames basieren auf Informationen aus vorherigen und folgenden B-Frames.
Nächstes Projekt soll Konsistenz erhöhen
In Experimenten zeigt das Team, dass VideoControlNet die generativen Fähigkeiten des verwendeten Diffusionsmodells beibehält und durch die Nutzung von Bewegungsinformationen erfolgreich auf Videos erweitert.
Das Team zeigt Beispiele für Style Transfer, der Videobearbeitung des Vorder- und des Hintergrunds.
Style Transfer
Video: Hu, Xu
Vordergrund
Video: Hu, Xu
Hintergrund
Video: Hu, Xu
Als nächstes möchte das Team mehr lernfähige Netzwerke integrieren, um die Konsistenz zu erhöhen.
Mehr Beispiele und den Code gibt es auf der VideoControlNet-Projektseite.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 20 Prozent Launch-Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: „KI Radar“ – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.