Visual ChatGPT: Chatbot kann jetzt Bilder verarbeiten
Die Zukunft der KI-Modelle ist multimodal - daran besteht eigentlich kein Zweifel. Doch dafür müssen nicht zwangsweise große neue Modelle trainiert werden. Stattdessen lassen sich auch bestehende Lösungen miteinander verbinden.
Microsoft hat den im November 2022 veröffentlichten OpenAI-Chatbot ChatGPT um eine essenzielle Funktion erweitert: Bildverarbeitung. Bislang konnte das Sprachmodell lediglich mit Text umgehen, Visual ChatGPT hingegen kann neben Texten auch Bilder verschicken und empfangen.
Laut den Wissenschaftler:innen könnte dafür ein multimodales Konversationsmodell trainiert werden - das benötige allerdings eine große Menge an Daten und Rechenressourcen. Zudem sei dieser Weg wenig flexibel und das Modell ließe sich nicht ohne neues Training auf andere Modalitäten wie Audio oder Video erweitern.
Verknüpfung zwischen ChatGPT und 22 Bildmodellen
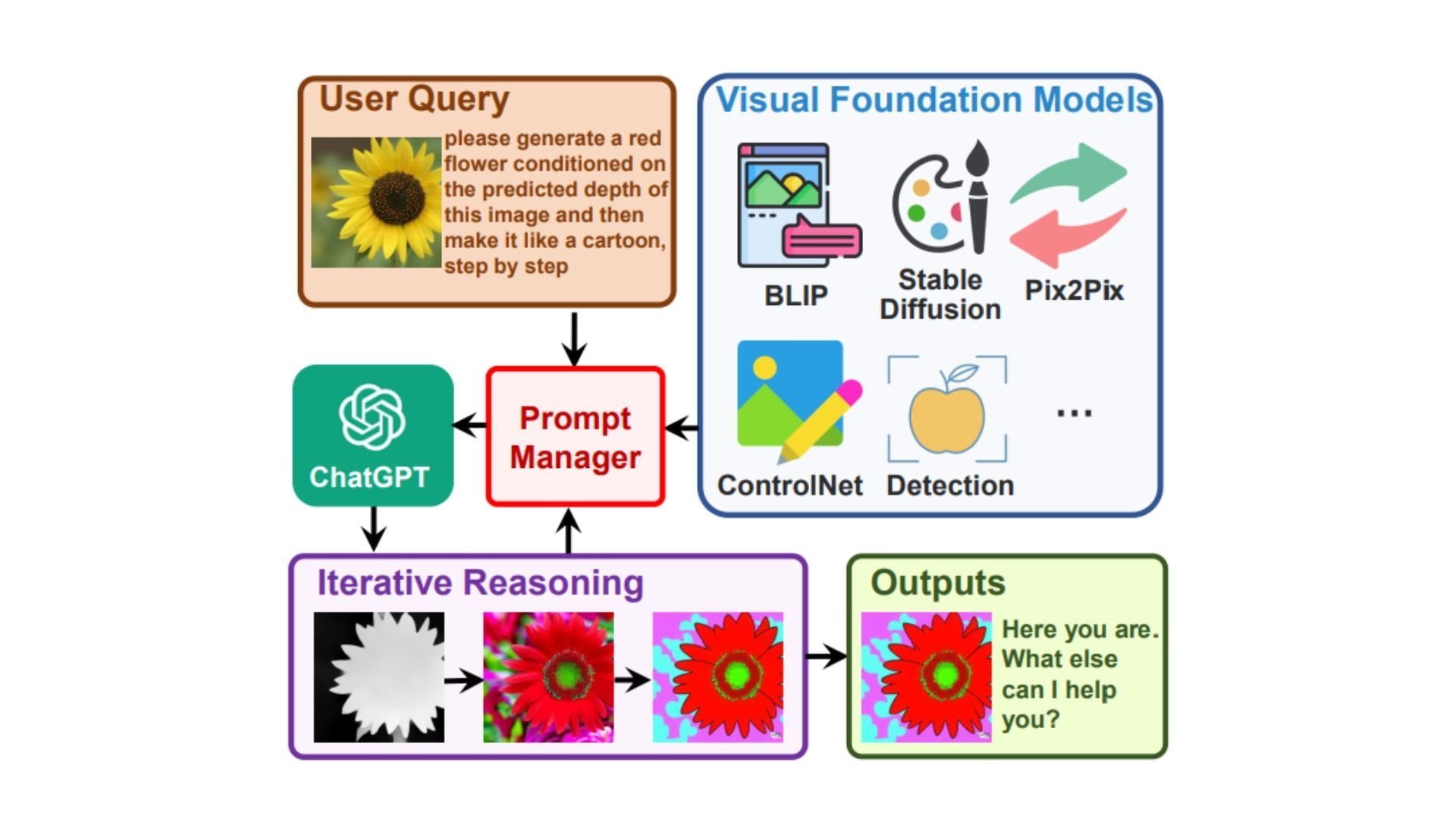
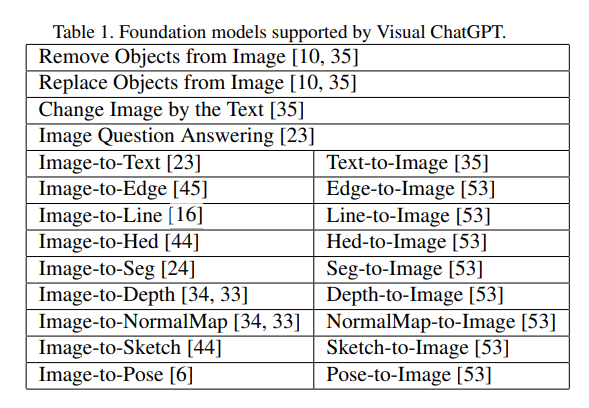
Statt also ein neues Modell zu trainieren, verknüpfen die Forschenden ChatGPT mit insgesamt 22 verschiedenen Visual Foundation Models (VFM), darunter Stable Diffusion. Diese Modelle übernehmen verschiedene Aufgaben und können etwa Fragen zu Bildern beantworten, Bilder generieren und bearbeiten oder Informationen wie Tiefendaten ableiten.
Die Brücke zwischen ChatGPT und VFM schlägt das Team mithilfe eines Prompt-Managers, der folgende Aufgaben übernimmt:
- ChatGPT explizit die Fähigkeiten der einzelnen VFM mitteilen und die Eingabe-/Ausgabeformate angeben
- Verschiedene visuelle Informationen wie PNGs oder Bilder mit Tiefeninformationen in ein für ChatGPT verständliches Sprachformat umwandeln
- Verläufe, Prioritäten und Konflikte der verschiedenen VFMs berücksichtigen
Visual ChatGPT kann so Bilder generieren, korrekt benennen, abspeichern und für weitere Eingaben bereithalten oder Bilder von Nutzer:innen als Eingabe verarbeiten.
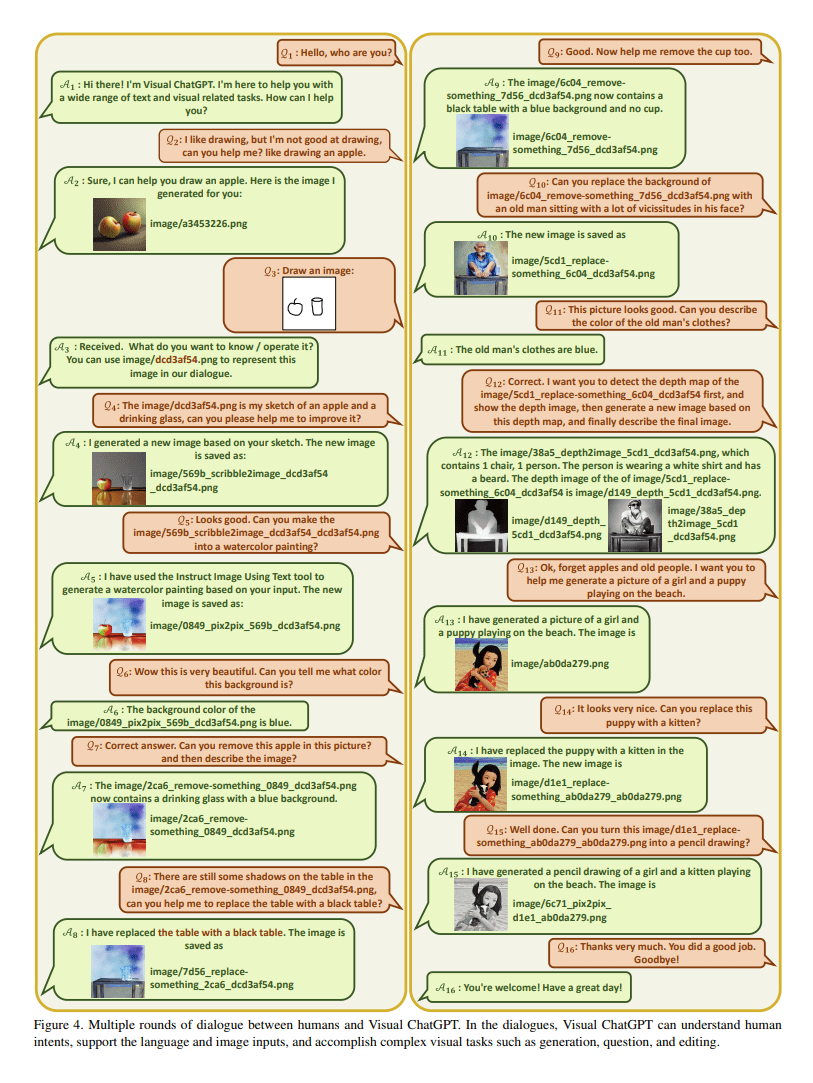
Falls dem Konversationsmodell nicht ganz klar ist, welches VFM zur Lösung der Aufgabe am besten geeignet ist, fragt Visual ChatGPT nach. Auf diesem Weg kann es auch mehrere VFMs miteinander verbinden.
Wenngleich die von Microsoft mit Visual ChatGPT gezeigten Beispiele vielversprechend sind, gebe es auch noch einige Einschränkungen. So sei Visual ChatGPT natürlich vollständig abhängig von ChatGPT und den verknüpften Bildmodellen.
Auch die maximale Anzahl an Tokens, die ChatGPT verarbeiten kann, sei ein limitierender Faktor. Außerdem sei ein erhebliches Maß an Prompt Engineering notwendig, um VFMs in Sprache umzuwandeln.
Vorherige Entwicklungen legten wichtige Grundsteine
Microsoft integriert in Visual ChatGPT einige existierende Methoden für mehr Kontrolle über Bildmodelle mit zusätzlichen Modellen oder Prompt-Enineering. Hier gab es in den letzten Monaten einige Fortschritte wie InstructPix2Pix, ControlNet oder GLIGEN.
Die Wissenschaftler:innen haben ihren Quellcode auf GitHub veröffentlicht. Eine Demo gibt es zudem auf Hugging Face, dafür ist allerdings ein eigener API-Schlüssel von OpenAI notwendig.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnierenKI-News ohne Hype
Von Menschen kuratiert.
- Mehr als 16 % Rabatt.
- Lesen ohne Ablenkung – keine Google-Werbebanner.
- Zugang zum Kommentarsystem und Austausch mit der Community.
- Wöchentlicher KI-Newsletter.
- 6× jährlich: “KI Radar” – Deep-Dives zu den wichtigsten KI-Themen.
- Bis zu 25 % Rabatt auf KI Pro Online-Events.
- Zugang zum kompletten Archiv der letzten zehn Jahre.
- Die neuesten KI‑Infos von The Decoder – klar und auf den Punkt.