Warum KI das Urlaubsfoto vom letzten Sommer nicht finden kann

Kurz & Knapp
- Forscher der Renmin University of China und des Oppo-Forschungsinstituts haben mit DISBench einen Benchmark erstellt, der testet, ob KI-Modelle Fotos anhand von Kontext und Zusammenhängen zwischen mehreren Bildern in persönlichen Sammlungen finden können.
- Die Ergebnisse sind ernüchternd: Selbst das beste Modell, Claude Opus 4.5, findet nur in knapp 29 Prozent der Fälle alle richtigen Bilder.
- Das Hauptproblem ist mangelnde Planung: Bis zu 50 Prozent aller Fehler entstehen, weil Modelle zwar den richtigen Kontext finden, dann aber die Suche vorzeitig abbrechen oder Einschränkungen vergessen.
Ein neuer Benchmark stellt KI-Modelle vor eine scheinbar einfache Aufgabe: bestimmte Fotos in einer persönlichen Sammlung finden. Die Ergebnisse fallen ernüchternd aus.
Wer ein bestimmtes Foto in der eigenen Sammlung sucht, erinnert sich oft nicht an das Bild selbst, sondern an den Kontext. Das Konzertfoto, auf dem nur der Sänger zu sehen war, vom Konzert mit dem blau-weißen Logo am Eingang.
Der entscheidende Hinweis, welches Konzert überhaupt gemeint ist, steckt dabei in einem gänzlich anderen Bild. Genau an dieser Stelle versagen laut einer neuen Studie von Forschern der Renmin University of China und dem Forschungsinstitut des Smartphone-Herstellers Oppo sämtliche gängigen Bildsuchsysteme.
Heutige multimodale Suchsysteme bewerten jedes Bild für sich: Passt es zur Suchanfrage oder nicht? Das funktioniert, solange das gesuchte Foto visuell eindeutig ist. Doch sobald die Antwort in den Zusammenhängen zwischen mehreren Bildern liegt, stößt dieser Ansatz an eine grundsätzliche Grenze.
Die Forscher nennen ihren neuen Ansatz DeepImageSearch und formulieren Bildersuche als autonome Explorationsaufgabe. Statt einzelne Bilder abzugleichen, soll ein KI-Modell eigenständig durch eine Fotosammlung navigieren, Hinweise aus verschiedenen Bildern zusammenführen und so schrittweise zum Ziel gelangen.
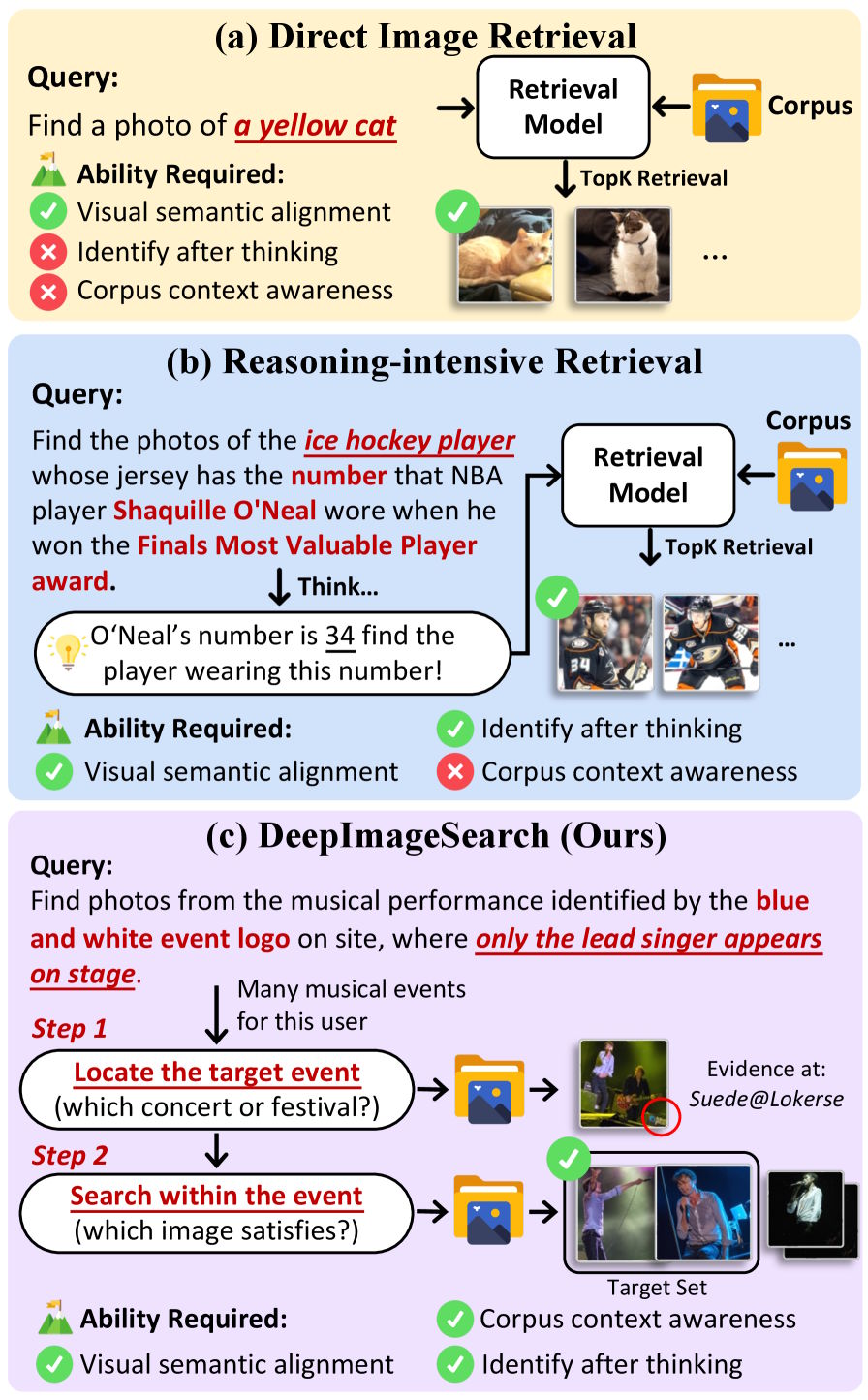
Herkömmliche Bildersuche trifft größtenteils zufällig
Um zu zeigen, wie groß die Lücke zwischen heutiger Technik und dieser Anforderung ist, haben die Forscher den Benchmark DISBench konstruiert. Er enthält 122 Suchanfragen, verteilt über die Fotosammlungen von 57 Nutzern mit insgesamt mehr als 109.000 Bildern. Die Fotos stammen aus dem öffentlich lizenzierten YFCC100M-Datensatz und umspannen im Schnitt 3,4 Jahre pro Nutzer.
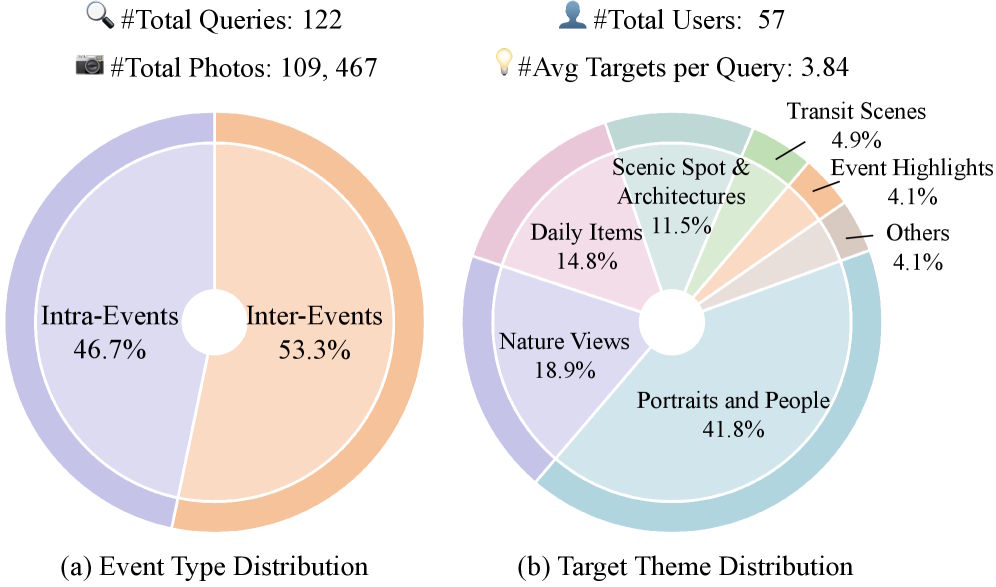
Die Suchanfragen lassen sich in zwei Kategorien einteilen. Die erste verlangt, zunächst ein bestimmtes Ereignis zu identifizieren und dann innerhalb dieses Ereignisses die richtigen Bilder herauszufiltern. Die zweite ist anspruchsvoller: Hier muss das Modell wiederkehrende Elemente über mehrere Ereignisse hinweg aufspüren und zeitlich oder räumlich einordnen. In beiden Fällen reicht es nicht, ein Bild isoliert zu betrachten.
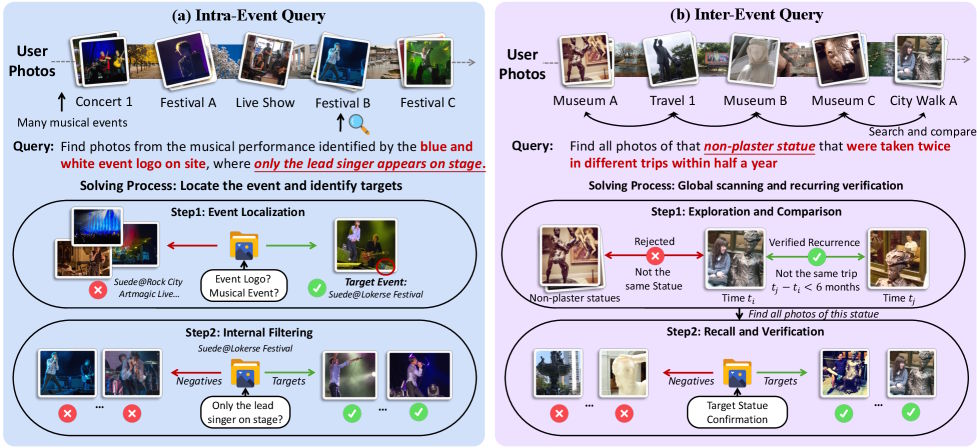
Wie grundlegend das Problem ist, zeigen die Ergebnisse herkömmlicher Embedding-Modelle wie Qwen3-VL-Embedding oder Seed-1.6-Embedding. Unter den ersten drei Treffern befindet sich laut der Studie nur in 10 bis 14 Prozent der Fälle ein tatsächlich gesuchtes Bild. Selbst diese niedrigen Werte seien größtenteils dem Zufall geschuldet, schreiben die Forscher.
Da persönliche Fotosammlungen viele visuell ähnliche Bilder aus unterschiedlichen Situationen enthalten, fischen die Modelle wahllos alles heraus, was oberflächlich zur Anfrage passt. Ob ein Bild wirklich die kontextuellen Bedingungen erfüllt, können sie schlicht nicht beurteilen.
Auch mit Werkzeugen scheitern die besten Modelle
Für eine fairere Evaluation haben die Forscher das Framework ImageSeeker entwickelt. Es gibt multimodalen Modellen Werkzeuge an die Hand, die über einfaches Bildmatching hinausgehen: eine semantische Suche, Zugriff auf Zeitstempel und GPS-Daten, die Möglichkeit, einzelne Fotos direkt zu inspizieren, und eine Websuche für unbekannte Begriffe. Zusätzlich sollen zwei Gedächtnismechanismen den Modellen helfen, Zwischenergebnisse festzuhalten und bei langen Suchpfaden den Überblick zu behalten.
Doch selbst mit dieser Ausstattung bleiben die Ergebnisse bescheiden. Das beste getestete Modell, Claude Opus 4.5 von Anthropic, fand nur in knapp 29 Prozent der Fälle exakt alle richtigen Bilder. GPT-5.2 von OpenAI schafft das in rund 13 Prozent der Fälle, Googles Gemini 3 Pro Preview in etwa 25 Prozent. Die Open-Source-Modelle Qwen3-VL und GLM-4.6V schneiden noch schwächer ab. Auf herkömmlichen Bildsuch-Benchmarks erzielen dieselben Modelle nahezu perfekte Werte.
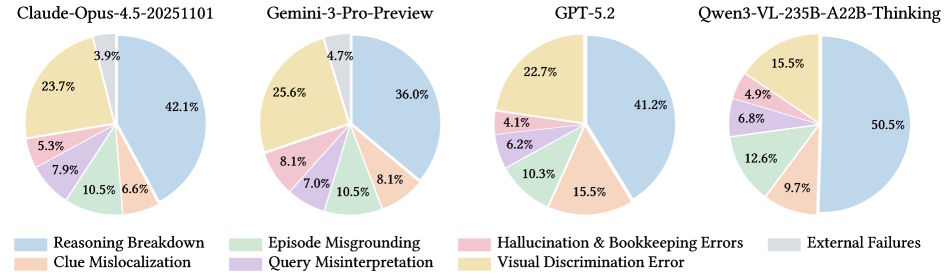
Besonders aufschlussreich ist ein Experiment mit mehreren parallelen Durchläufen pro Anfrage. Wählt man jeweils das beste Ergebnis aus, steigt die Trefferquote um gut 70 Prozent. Die Modelle besitzen also das Potenzial, die Aufgaben zu lösen. Sie schaffen es nur nicht zuverlässig, den richtigen Lösungsweg einzuschlagen.
Das Hauptproblem ist nicht das Sehen, sondern das Planen
Die manuelle Fehleranalyse der Forscher zeigt, woran die Modelle konkret scheitern. Der mit Abstand häufigste Fehler: Die Modelle finden zwar den richtigen Kontext, brechen dann aber die Suche vorzeitig ab oder verlieren dabei ihre Einschränkungen aus dem Blick.
Die Studie bezeichnet das als den auch in anderen Kontexten beobachteten „Reasoning Breakdown". Zwischen 36 und 50 Prozent aller Fehler fallen in diese Kategorie. Erst an zweiter Stelle steht die visuelle Unterscheidungsfähigkeit – also das Verwechseln ähnlich aussehender Objekte oder Gebäude.
Auch die systematische Untersuchung einzelner Werkzeuge stützt diesen Befund. Von allen Hilfsmitteln im Framework haben die Metadaten-Werkzeuge den größten Einfluss auf die Leistung. Ohne Zugriff auf Zeitstempel und Ortsangaben verschlechtert sich die Treffergenauigkeit am stärksten. Zeitliche und räumliche Einordnung erweisen sich als entscheidend, um visuell ähnliche Bilder aus verschiedenen Situationen auseinanderzuhalten.
Die Forscher sehen in ihrem Benchmark einen Testfall für die nächste Generation von Suchsystemen. Solange KI-Modelle Bilder nur isoliert bewerten können, bleiben komplexe Suchanfragen in persönlichen Fotosammlungen ungelöst. DeepImageSearch zeige, dass die Modelle nicht in erster Linie besser sehen müssten, sondern besser planen, Einschränkungen im Blick behalten und Zwischenstände verwalten. Code und Datensatz sind öffentlich verfügbar, außerdem gibt es eine Rangliste.
Wie bei Text zeigen KI-Modelle auch bei Bildern das bekannte "Lost in the Middle"-Problem: Visuelle Informationen am Anfang oder Ende eines Datensatzes werden stärker berücksichtigt als solche in der Mitte. Je größer der Datensatz und je voller das Kontextfenster, desto ausgeprägter ist dieser Effekt. Deshalb ist gutes Context-Engineering (Guide, heise kI Pro) so relevant.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den „KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnieren