
Microsoft zeigt mit WaveCoder und CodeOcean, wie generative KI für bessere Trainingsdaten eingesetzt werden kann.
Microsoft-Forscher haben WaveCoder vorgestellt, ein neues Modell für Programmiersprachen, das mit weniger Trainingsbeispielen besser sein soll als Modelle ähnlicher Größe. Außerdem hat das Team CodeOcean entwickelt, einen kuratierten Datensatz mit 20.000 verschiedenen Codebeispielen, um die Feinabstimmung von Foundation-Modellen für Programmieranwendungen zu verbessern.
Eine der größten Herausforderungen bei der Erstellung kleinerer, effizienterer Modelle für Programmiersprachen besteht den Forschern zufolge darin, die Größe des Trainingsdatensatzes mit der Leistung des Modells in Einklang zu bringen. Der CodeOcean-Datensatz soll diese Herausforderung meistern, indem er maximale Vielfalt in einer begrenzten Anzahl von Beispielen bietet. Als Basis für CodeOcean dient CodeSearchNet, ein riesiger Code-Datensatz mit 2 Millionen Paaren von Kommentaren und Code, den das Team durch Embeddings und ein BERT-basiertes Modell auf eine kleinere, aber dennoch vielfältige Teilmenge reduziert hat.
CodeOcean nutzt Generator-Diskriminator-Framework für qualitativ hochwertige Trainingsdaten
Um Trainingsbeispiele zu erstellen, die Code und Instruktionen enthalten, verwendeten die Forscher dann ein Generator-Diskriminator-Framework, um Instruktionen auf der Grundlage der rohen Codebeispiele zu erstellen. Zuerst wurde GPT-4 verwendet, um Aufgaben innerhalb spezifischer Szenario-Kontexte zu definieren. Diese Aufgaben wurden dann mit einer Instruktion kombiniert und an GPT-3.5 übergeben, um ähnliche Instruktionen für weitere Beispiele zu generieren. Auf diese Weise generiert das Team automatisch eine große Menge an Trainingsdaten, die Instruktionen und Code enthalten, etwa Codeaufgaben mit natürlichsprachlichen Beschreibungen und Lösungen.
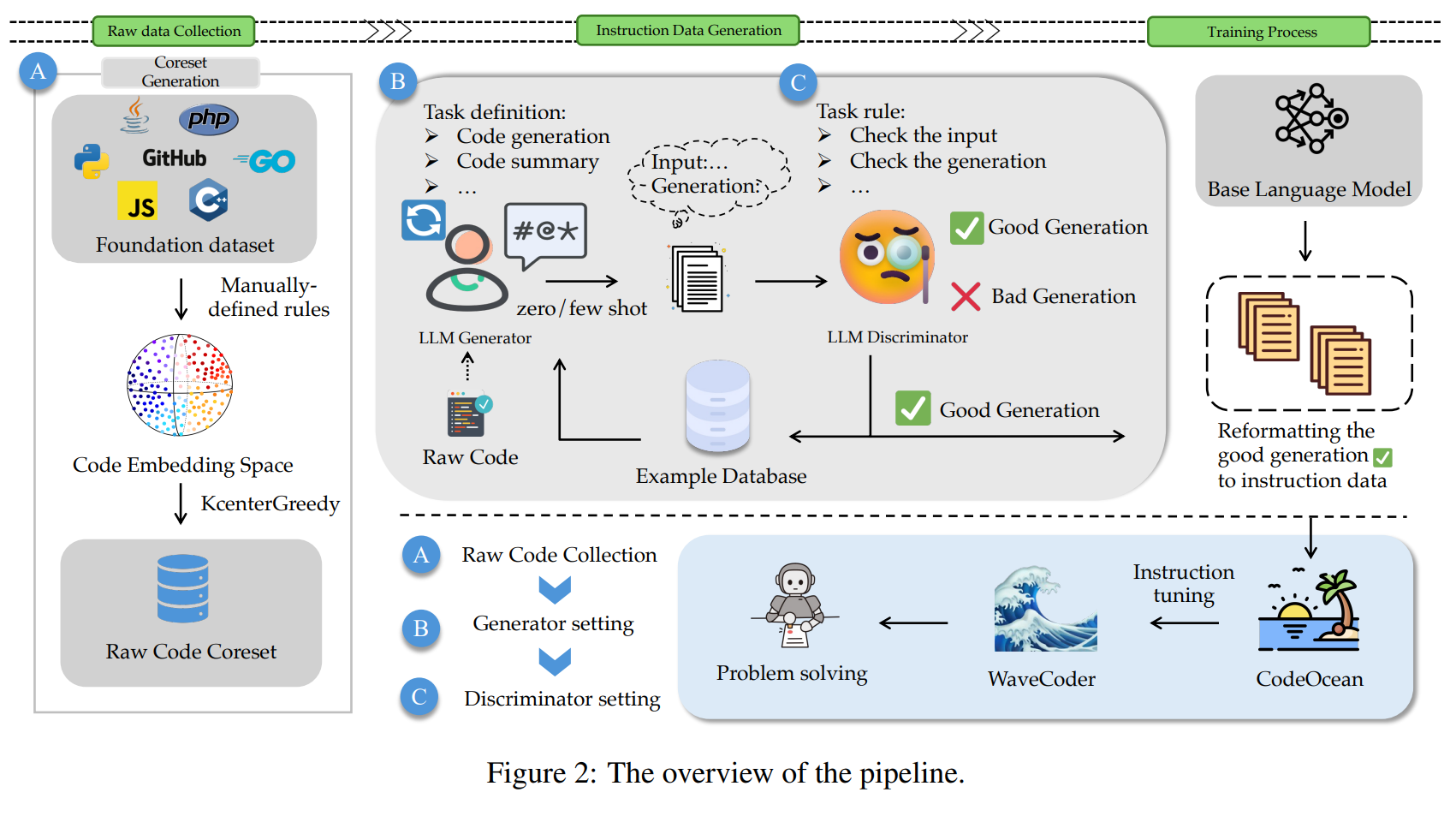
Die Daten werden dann an GPT-4 zurückgeschickt, wo sie nach festgelegten Kriterien bewertet werden. Gute Beispiele werden in eine Beispieldatenbank übertragen, die als Vorlage für die Generierung weiterer Trainingsdaten dient. Durch diesen iterativen Prozess generierte das Team 20.000 qualitativ hochwertige Beispiele, die vier verschiedene Kategorien von Codeaufgaben abdecken: Codegenerierung, Codezusammenfassung, Übersetzung in eine andere Programmiersprache und Codereparatur.
WaveCoder zeigt, wie wichtig gute Daten sind
Das Team trainierte WaveCoder mit diesem Datensatz und verglich es mit WizardCoder, einem Modell, das mit etwa der vierfachen Menge an Daten trainiert wurde. Das Team stellte fest, dass der Leistungsunterschied gering war, was darauf hindeutet, dass verfeinerte und diversifizierte Befehlsdaten die Effizienz des Befehls-Tunings erheblich verbessern können. WaveCoder übertraf auch andere Open-Source-Modelle bei Aufgaben zur Code-Zusammenfassung und -Reparatur in fast allen Programmiersprachen.
Die Forscher nutzten CodeOcean auch, um drei Modelle für Programmiersprachen zu verfeinern: StarCoder-15B, CodeLLaMA (7B und 13B) und DeepseekCoder-6.7B. In drei wichtigen Programmier-Benchmarks - HumanEval, MBPP und HumanEvalPack - zeigten alle Modelle signifikante Verbesserungen von bis zu 20 Prozent.
CodeOcean und WaveCoder sind noch nicht verfügbar, sollen laut einem beteiligten Forscher aber noch veröffentlicht werden.




