Wer das beste KI-Modell sucht, sollte sich nicht nur auf Bestenlisten verlassen

Kurz & Knapp
- Forschende am MIT und IBM Research zeigen, dass Rankings populärer LLM-Plattformen wie LMArena extrem instabil sind: Nur 2 von 57.477 entfernten Nutzerbewertungen reichten aus, um das bestplatzierte Modell zu ändern.
- Das Muster wiederholt sich bei fast allen untersuchten Plattformen. Einzige Ausnahme ist MT-bench, wo 2,74 Prozent nötig waren, was die Forscher auf das kontrollierte Design mit kuratierten Fragen und Experten-Annotatoren zurückführen.
- Die Forschenden empfehlen, Bewertungen auf Ausreißer zu prüfen, damit Rauschen oder Nutzerfehler nicht das Spitzenranking bestimmen.
Forschende zeigen, dass populäre LLM-Ranking-Plattformen überraschend fragil sind. Es reicht, nur 0,003 Prozent der Nutzerbewertungen zu entfernen, um die Spitzenplatzierung in einer Rangliste zu kippen.
Plattformen wie Arena (ehemals LMArena bzw. Chatbot Arena) zeigen im Gegensatz zu standardisierten Benchmarks, wie Sprachmodelle im offenen Austausch mit echten Nutzern abschneiden.
Die per Crowdsourcing erstellten Präferenz-Rankings sind in der Branche entsprechend einflussreich: Nutzer ziehen sie heran, um einzuschätzen, wie hilfreich ein LLM tatsächlich antwortet, und Unternehmen verwenden die Platzierung zur Vermarktung ihrer Modelle.
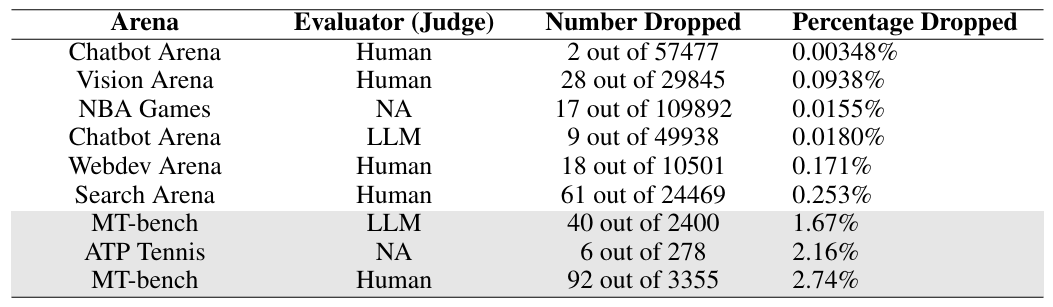
Doch laut einer Studie von Forschenden am MIT und IBM Research sind diese Rankings sehr instabil: Es genügt, nur zwei Nutzerbewertungen aus insgesamt 57.477 zu entfernen, um das bestplatzierte Modell zu ändern.
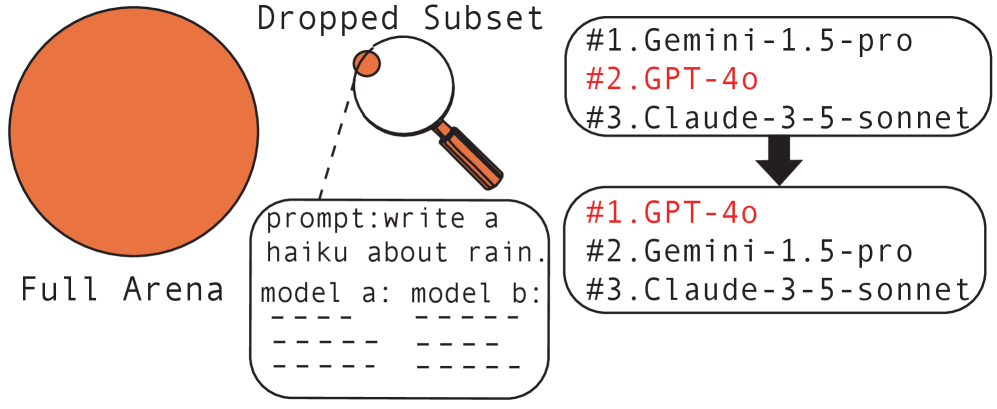
Konkret wechselte die Spitzenposition von GPT-4-0125-preview zu GPT-4-1106-preview. Die beiden entfernten Bewertungen waren Fälle, in denen GPT-4-0125-preview gegen deutlich schwächer platzierte Modelle verloren hatte: Vicuna-13b auf Rang 43 und Stripedhyena-nous-7b auf Rang 45. Eine qualitative Analyse mit einem starken Richtermodell stufte diese Präferenzen als atypisch ein, also als Urteile, die vom Durchschnittsnutzer abweichen.
"Wenn das bestplatzierte LLM nur von zwei oder drei Nutzerbewertungen aus Zehntausenden abhängt, kann man nicht davon ausgehen, dass dieses Modell im Einsatz alle anderen konsistent übertrifft", sagt Tamara Broderick, Professorin am MIT und Seniorautorin der Studie.
Fragilität zieht sich durch fast alle Plattformen
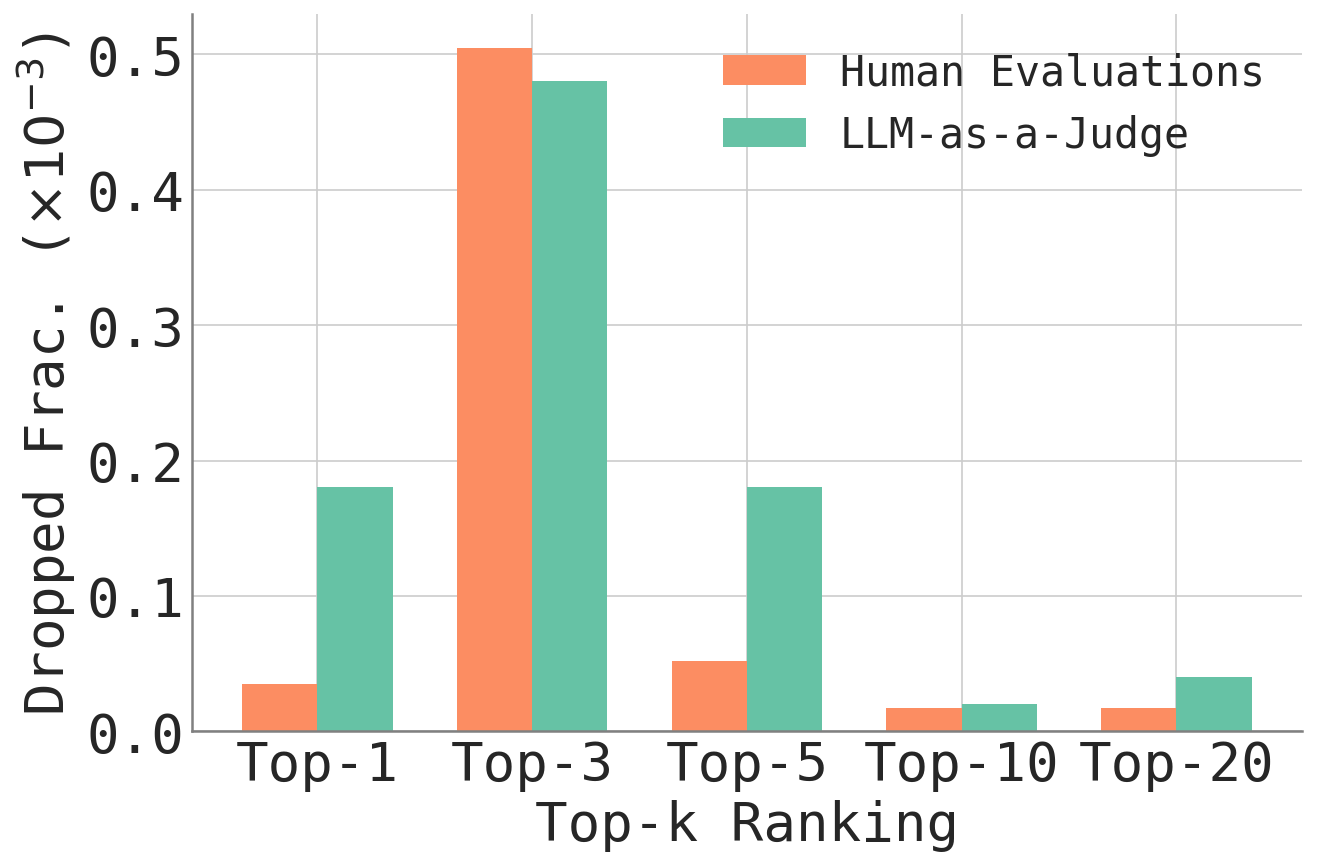
Die Forschenden untersuchten neben Chatbot Arena auch Vision Arena, Search Arena, Webdev Arena und MT-bench. Das Muster wiederholt sich: Bei Chatbot Arena mit LLM-Richtern genügten 9 von 49.938 Bewertungen (0,018 Prozent) für einen Wechsel an der Spitze, bei Vision Arena 28 von 29.845 (0,094 Prozent), bei Search Arena 61 von 24.469 (0,253 Prozent).
Die einzige Ausnahme bildet MT-bench. Dort waren 92 von 3.355 Bewertungen nötig, rund 2,74 Prozent. Die Forscher führen die höhere Robustheit auf das Design zurück: MT-bench verwendet 80 sorgfältig konstruierte Multi-Turn-Fragen und setzt auf Experten-Annotatoren statt auf Crowd-Bewertungen. Ob menschliche oder KI-basierte Bewertungen grundsätzlich anfälliger sind, lässt sich laut der Studie nicht pauschal sagen.
Schnelle Approximation statt kombinatorischer Suche
Alle möglichen Kombinationen von Bewertungen durchzuprobieren, um die einflussreichsten zu finden, wäre rechnerisch unmöglich. Die Forschenden entwickelten daher eine Approximationsmethode, die gezielt jene Datenpunkte aufspürt, deren Entfernung ein Ranking am stärksten verändern würde.
Anschließend wird das Ergebnis durch eine exakte Neuberechnung ohne diese Datenpunkte verifiziert. Auf einem handelsüblichen Laptop dauert die Analyse eines Datensatzes mit 50.000 Bewertungen laut den Forschenden unter drei Minuten.
Dass das Problem nicht KI-spezifisch ist, zeigt ein Vergleich mit Sportdaten: Bei historischen NBA-Spielen genügten 17 von 109.892 Partien (0,016 Prozent), um das bestplatzierte Team zu ändern. Die Ursache liegt laut der Studie im zugrundeliegenden statistischen Verfahren, dem Bradley-Terry-Modell, das sowohl LLM-Plattformen als auch Sport-Rankings verwenden. Es wird offenbar dann fragil, wenn die Leistungsunterschiede an der Spitze gering ausfallen.
Rauschen und Nutzerfehler als mögliche Ursache
Die Forscher schlagen mehrere Maßnahmen vor: Nutzer sollten neben ihrer Präferenz auch ein Konfidenzniveau angeben können, Plattformen könnten uninformative Prompts herausfiltern oder Bewertungen durch Mediatoren prüfen lassen.
Die Studie unterscheidet sich dabei von früheren Arbeiten, die zeigten, dass Chatbot Arena durch das Einschleusen gefälschter Stimmen manipulierbar ist. Hier geht es um die statistische Robustheit gegenüber bereits vorhandenen Daten, nicht um gezielte Angriffe.
"Wir können nie wissen, was der Nutzer in dem Moment gedacht hat, aber vielleicht hat er sich verklickt oder nicht aufgepasst", sagt Broderick. "Die große Erkenntnis ist, dass man nicht will, dass Rauschen, Nutzerfehler oder Ausreißer bestimmen, welches das bestplatzierte LLM ist."
Bereits im Mai 2025 geriet die Plattform in die Kritik: Eine Studie warf ihr vor, große Anbieter wie Meta oder Google systematisch zu bevorzugen, unter anderem weil diese zahlreiche Modellvarianten vorab privat testen und anschließend nur die bestplatzierten Versionen öffentlich in die Rangliste einfließen lassen konnten.
Zudem erhielten ihre Modelle deutlich mehr Nutzerbewertungen als die kleinerer Anbieter. Die Arena-Betreiber wiesen die Vorwürfe zurück. Anfang Januar sammelte das US-Start-up weitere 150 Millionen Dollar ein und verdreifachte seine Bewertung auf 1,7 Milliarden Dollar.
Die Studie des MIT und IBM Research zeigt wieder einmal, dass Benchmarks und Ranking-Plattformen bestenfalls eine grobe Annäherung an die tatsächliche Leistungsfähigkeit von KI-Modellen sind. Sie sind fragil, leicht verzerrbar – sei es durch Nutzerfehler, Sättigungseffekte oder gezielte Optimierung auf Testaufgaben – und dennoch die beste systematische Vergleichsmethode, die die Branche derzeit hat. Wer wissen will, welches Modell wirklich überzeugt, kommt um eigene Erfahrungen in der Praxis nicht herum. Hier taugen Benchmarks zur Vorauswahl.
KI-News ohne Hype – von Menschen kuratiert
Mit dem THE‑DECODER‑Abo liest du werbefrei und wirst Teil unserer Community: Diskutiere im Kommentarsystem, erhalte unseren wöchentlichen KI‑Newsletter, 6× im Jahr den "KI Radar"‑Frontier‑Newsletter mit den neuesten Entwicklungen aus der Spitze der KI‑Forschung, bis zu 25 % Rabatt auf KI Pro‑Events und Zugriff auf das komplette Archiv der letzten zehn Jahre.
Jetzt abonnieren